weave.init() が呼び出された後に、ChatNVIDIA ライブラリ経由で行われた LLM 呼び出しを自動的にトレースしてログに記録します。
トレース
- Python
- TypeScript
Weave は ChatNVIDIA Python ライブラリ のトレースを自動的に取得できます。任意のプロジェクト名を指定して
weave.init(<project-name>) を呼び出し、トレースの取得を開始します。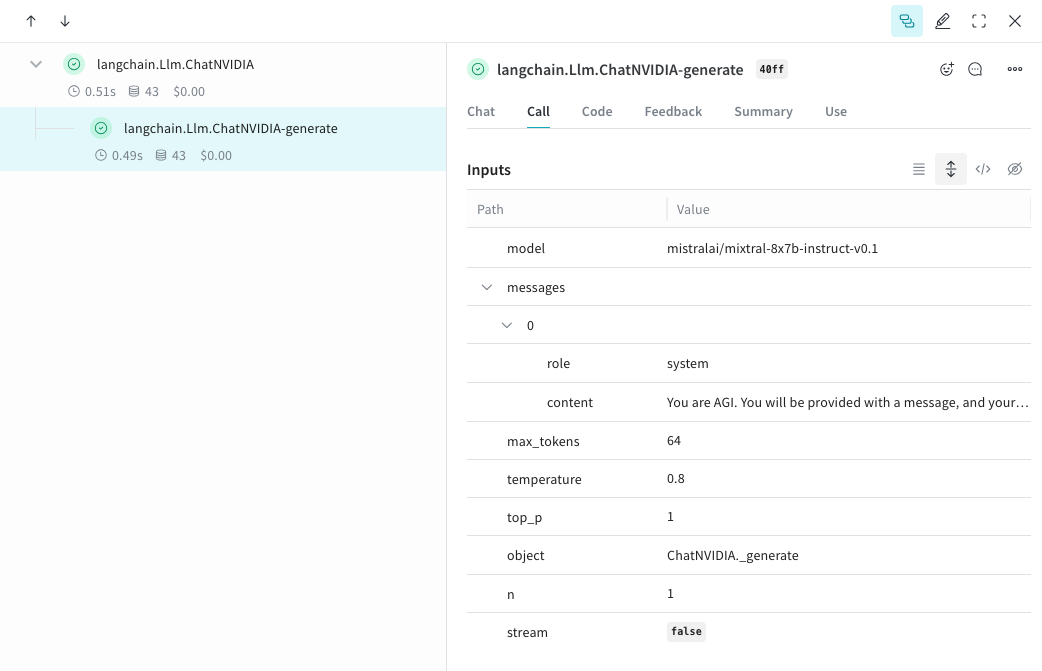
自分の op をトラッキングする
- Python
- TypeScript
関数を Weave を開き、UI で
@weave.op でラップすると、入力、出力、アプリのロジックがキャプチャされるようになり、データがアプリ内をどのように流れているかをデバッグできるようになります。op は深くネストでき、トラッキングしたい関数のツリーを構築できます。また、実験しながら、git にコミットしていないアドホックな詳細も含めてコードが自動的にバージョン管理されます。@weave.op でデコレートし、ChatNVIDIA python library を呼び出す関数を作成するだけです。次の例では、2 つの関数を op でラップしています。これにより、RAG アプリにおけるリトリーバルステップのような中間ステップが、アプリの挙動にどのように影響しているかを確認できます。get_pokemon_data をクリックすると、そのステップの入力と出力を確認できます。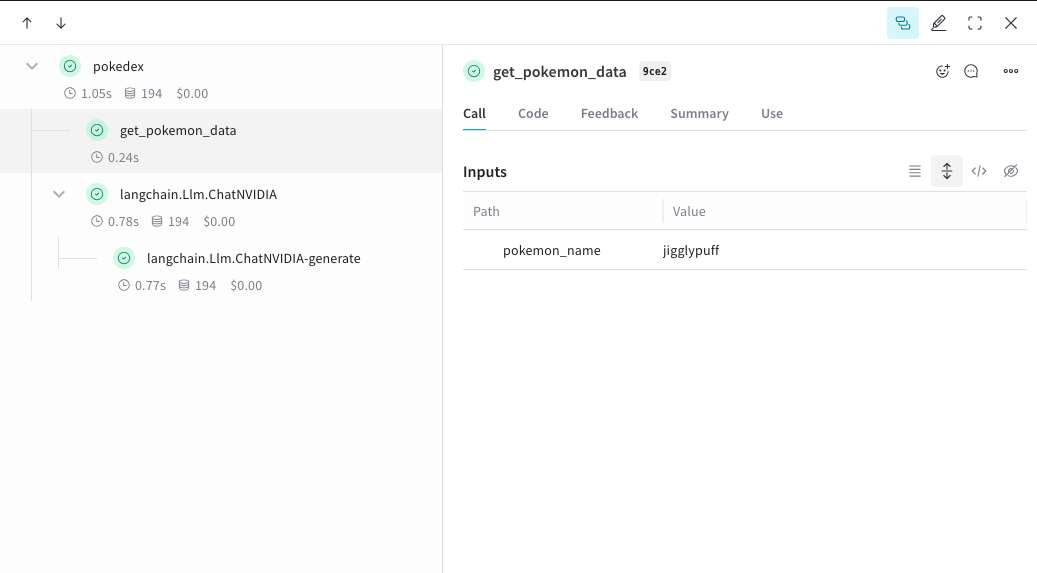
実験をより簡単にするために Model を作成する
- Python
- TypeScript
多くの要素が関わっていると、実験を整理するのは難しくなります。
Model クラスを使うと、システムプロンプトや使用しているモデルなど、アプリの実験に関する詳細を記録して整理できます。これにより、アプリのさまざまな反復バージョンを整理して比較しやすくなります。コードのバージョニングと入出力の記録に加えて、Model はアプリケーションの挙動を制御する構造化されたパラメータも記録するため、どのパラメータが最もうまく機能したかを簡単に見つけられます。Weave の Model は、serve や Evaluation と組み合わせて使うこともできます。以下の例では、model と system_message を変更して試すことができます。これらのいずれかを変更するたびに、GrammarCorrectorModel の新しい バージョン が作成されます。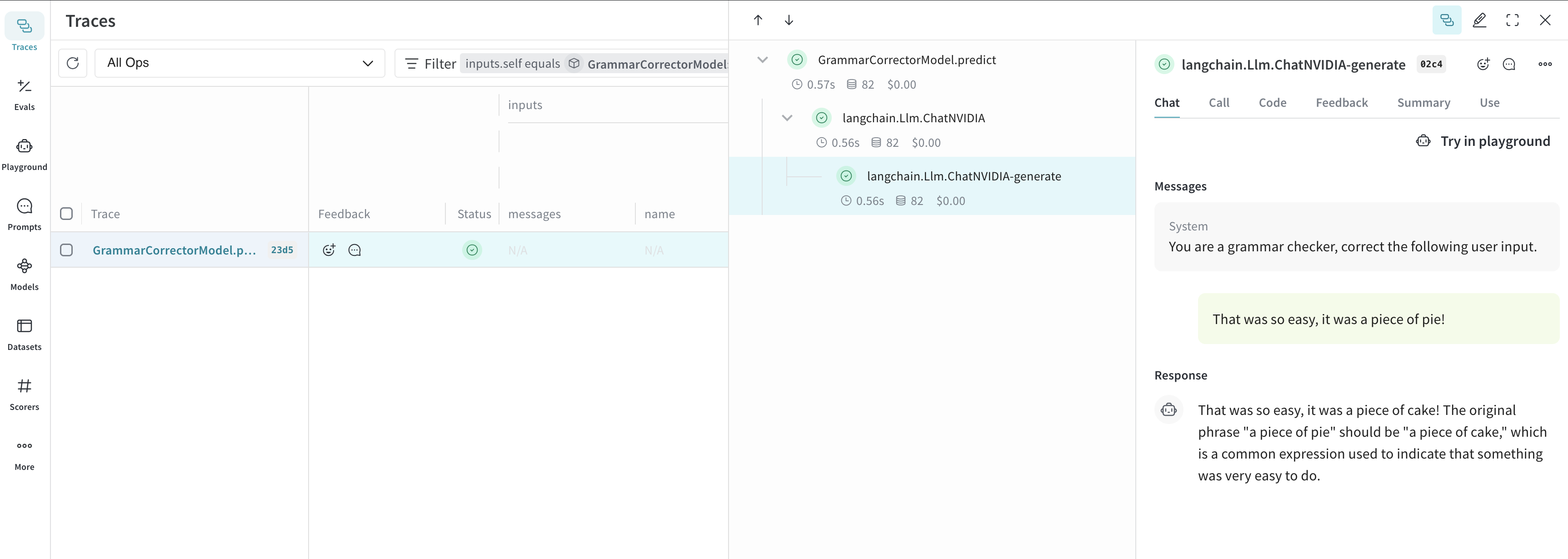
使用方法
invoke、stream およびそれらの非同期版をサポートします。ツールの利用にも対応しています。
ChatNVIDIA はさまざまな種類のモデルでの利用を想定しているため、function calling には対応していません。