- Python
- TypeScript
Weave では、ワークフローの中核となるのは
Evaluation オブジェクト であり、これは次の内容を定義します。Evaluation を定義したら、Model オブジェクトや、LLM アプリケーションロジックを含む任意のカスタム関数に対して実行できます。.evaluate() を呼び出すたびに evaluation run がトリガーされます。Evaluation オブジェクトは設計図であり、各 run はそのセットアップの下でアプリケーションがどのように動作するかを測定するものと考えてください。1. Evaluation オブジェクトを作成する
Evaluation オブジェクトの作成は、評価設定を行う最初のステップです。Evaluation はサンプルデータ、スコアリングロジック、および任意の前処理から構成されます。このオブジェクトを使用して、後で 1 回以上評価を実行します。
Weave は各サンプルをアプリケーションに通し、その出力に対して複数のカスタムスコアリング関数を使ってスコアを付けます。これにより、アプリケーションのパフォーマンスを把握でき、個々の出力やスコアを詳細に確認できるリッチな UI を利用できます。
(オプション)カスタム名の設定
- Python
- TypeScript
評価フローでは、カスタマイズ可能な名前が 2 種類あります。
- Evaluation オブジェクト名 (
evaluation_name): 設定済みのEvaluationオブジェクトに対する永続的なラベル。 - Evaluation run 表示名 (
__weave["display_name"]): 特定の評価実行に対するラベルで、UI に表示されます。
Evaluation オブジェクトに名前を付ける
Evaluation オブジェクト自体に名前を付けるには、Evaluation クラスに evaluation_name パラメータを渡します。この名前によって、コードや UI の一覧で Evaluation を識別しやすくなります。個々の evaluation run に名前を付ける
特定の evaluation run(evaluate() の呼び出し)に名前を付けるには、display_name を指定した __weave 辞書を使用します。この設定は、その run が UI 上でどのように表示されるかに影響します。2. テスト例のデータセットを定義する
- Python
- TypeScript
次の例では、データセットを辞書のリストとして定義しています。
3. スコアリング関数を定義する
Dataset 内の各サンプルをスコア付けするために使用します。
- Python
- TypeScript
各スコアリング関数は必ず (オプション)カスタム
いくつかのアプリケーションでは、カスタムの
output パラメータを持ち、スコアを含む辞書を返す必要があります。必要に応じて、例から他の入力を含めることもできます。スコアリング関数は output キーワード引数を持つ必要がありますが、それ以外の引数はユーザー定義であり、データセット中の各例から取得されます。関数は、引数名に対応する辞書キーを使って必要なキーだけを取得します。次のサンプルのスコアラー関数 match_score1 は、examples 辞書の expected 値をスコア付けに使用します。(オプション)カスタム Scorer クラスを定義する
いくつかのアプリケーションでは、カスタムの Scorer クラスを作成したい場合があります。たとえば、特定のパラメータ(チャットモデルやプロンプトなど)、各行に対する特定のスコアリング方法、および集約スコアの特定の計算方法を備えた標準化された LLMJudge クラスを作成するケースです。詳細については、Model-Based Evaluation of RAG applications にある Scorer クラスの定義に関するチュートリアルを参照してください。4. 評価するモデルまたは関数を定義する
- Python
- TypeScript
Model を評価するには、Evaluation を使ってその evaluate を呼び出します。Models は、Weave で実験し記録したいパラメータがある場合に使用します。predict が実行され、各スコアリング関数で出力がスコアリングされます。(オプション)評価する関数を定義する
代わりに、@weave.op() でトラッキングされるカスタム関数を評価することもできます。5. 評価を実行する
Evaluation オブジェクトに対して .evaluate() を呼び出します。
- Python
- TypeScript
evaluation という名前の Evaluation オブジェクトと、評価対象の model オブジェクトがあると仮定すると、次のコードで評価用の run が作成されます。(オプション)複数回の試行を実行する
各サンプルを複数回評価するには、Evaluation オブジェクトの trials パラメータを設定します。評価コードの完全な例
- Python
- TypeScript
次のコードサンプルは、評価を最初から最後まで実行する完全な例です。
examples 辞書は、prompt の値が与えられた MyModel と、カスタム関数 function_to_evaluate を評価するために、スコアリング関数 match_score1 および match_score2 によって使用されます。Model と関数の両方に対する評価は、それぞれ asyncio.run(evaluation.evaluate(...)) で実行されます。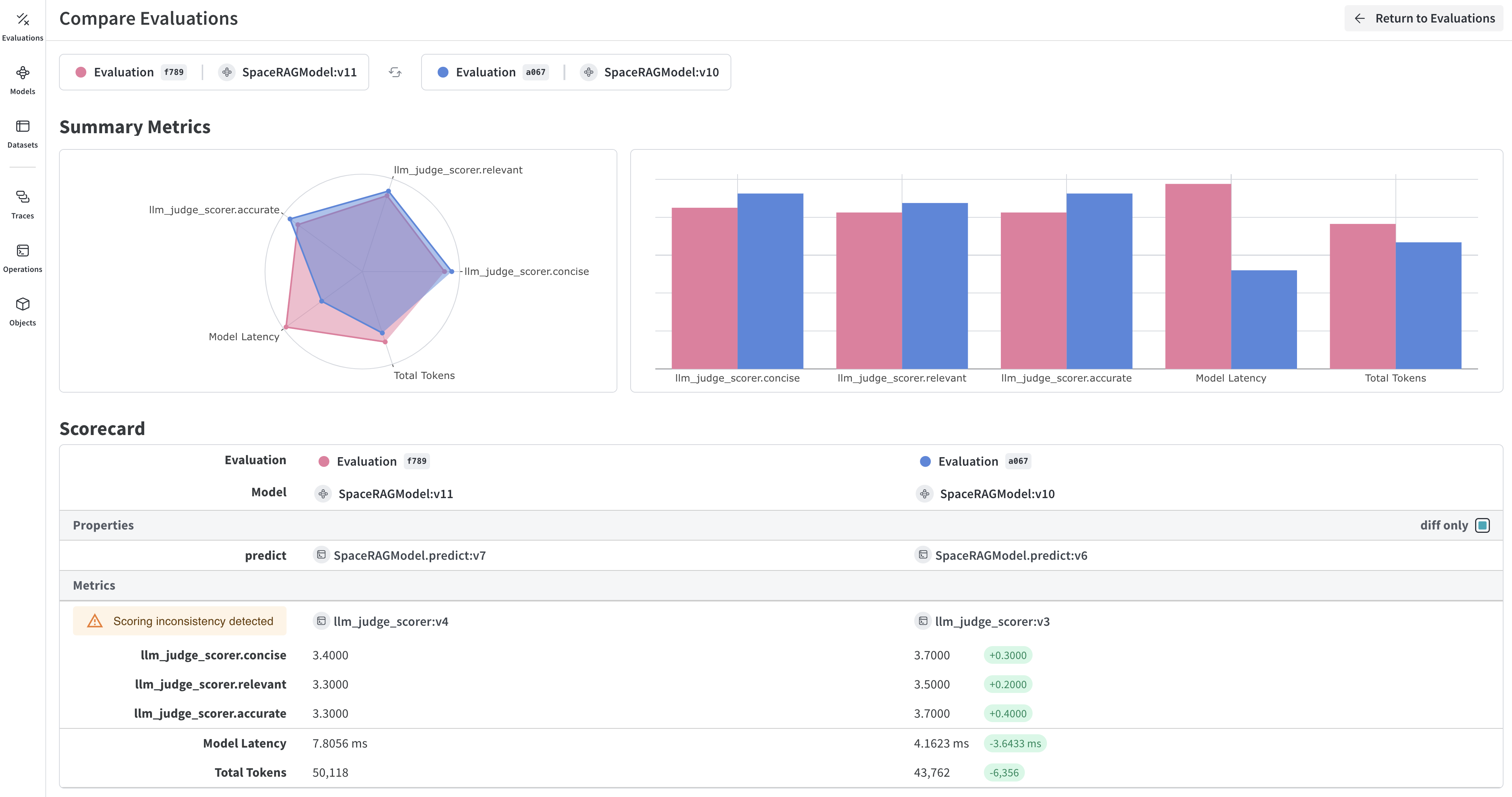
高度な評価の活用方法
評価の前にデータセットの行を前処理する
- Python
- TypeScript
preprocess_model_input パラメータを使用すると、評価関数に渡す前にデータセットの各例を変換できます。これは次のような場合に有用です:- フィールド名を変更して、モデルが期待する入力名に合わせる
- データを正しいフォーマットに変換する
- フィールドを追加・削除する
- 各例ごとに追加のデータを読み込む
preprocess_model_input を使ってフィールド名を変更する方法を示しています:input_text フィールドがありますが、評価関数は question というパラメータを期待しています。preprocess_example 関数はフィールド名を変更して各例を変換し、評価が正しく動作するようにします。前処理関数は次のように動作します:- データセットから生の例を受け取る
- モデルが期待するフィールドを持つ辞書を返す
- 各例が評価関数に渡される前に適用される
評価で HuggingFace Datasets を使う
- Python
- TypeScript
サードパーティのサービスやライブラリとのインテグレーションは、継続的に強化しています。よりシームレスなインテグレーションが整うまでは、暫定的なワークアラウンドとして、Weave の評価で HuggingFace Datasets を利用する際に
preprocess_model_input を使用できます。現在のアプローチについては、Using HuggingFace datasets in evaluations cookbook を参照してください。保存済みビュー
命令型の評価 (EvaluationLogger)
EvaluationLogger を検討してください。EvaluationLogger は Python と TypeScript の両方で利用でき、複雑なワークフローに対してより高い柔軟性を提供します。一方で、標準的な評価フレームワークは、より明確な構造と指針を提供します。