Cerebras Cloud SDK 経由で行われる LLM 呼び出しを Weave でトレースしてログに記録する
import os import weave from cerebras.cloud.sdk import Cerebras # weave プロジェクトを初期化する weave.init("cerebras_speedster") # Cerebras SDK を通常通り使用する api_key = os.environ["CEREBRAS_API_KEY"] model = "llama3.1-8b" # Cerebras モデル client = Cerebras(api_key=api_key) response = client.chat.completions.create( model=model, messages=[{"role": "user", "content": "What's the fastest land animal?"}], ) print(response.choices[0].message.content)
import os import weave from cerebras.cloud.sdk import Cerebras # Weaveプロジェクトを初期化する weave.init("cerebras_speedster") client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"]) # Weaveはこの関数の入力、出力、コードを追跡します @weave.op def animal_speedster(animal: str, model: str) -> str: "Find out how fast an animal can run" response = client.chat.completions.create( model=model, messages=[{"role": "user", "content": f"How fast can a {animal} run?"}], ) return response.choices[0].message.content animal_speedster("cheetah", "llama3.1-8b") animal_speedster("ostrich", "llama3.1-8b") animal_speedster("human", "llama3.1-8b")
Model
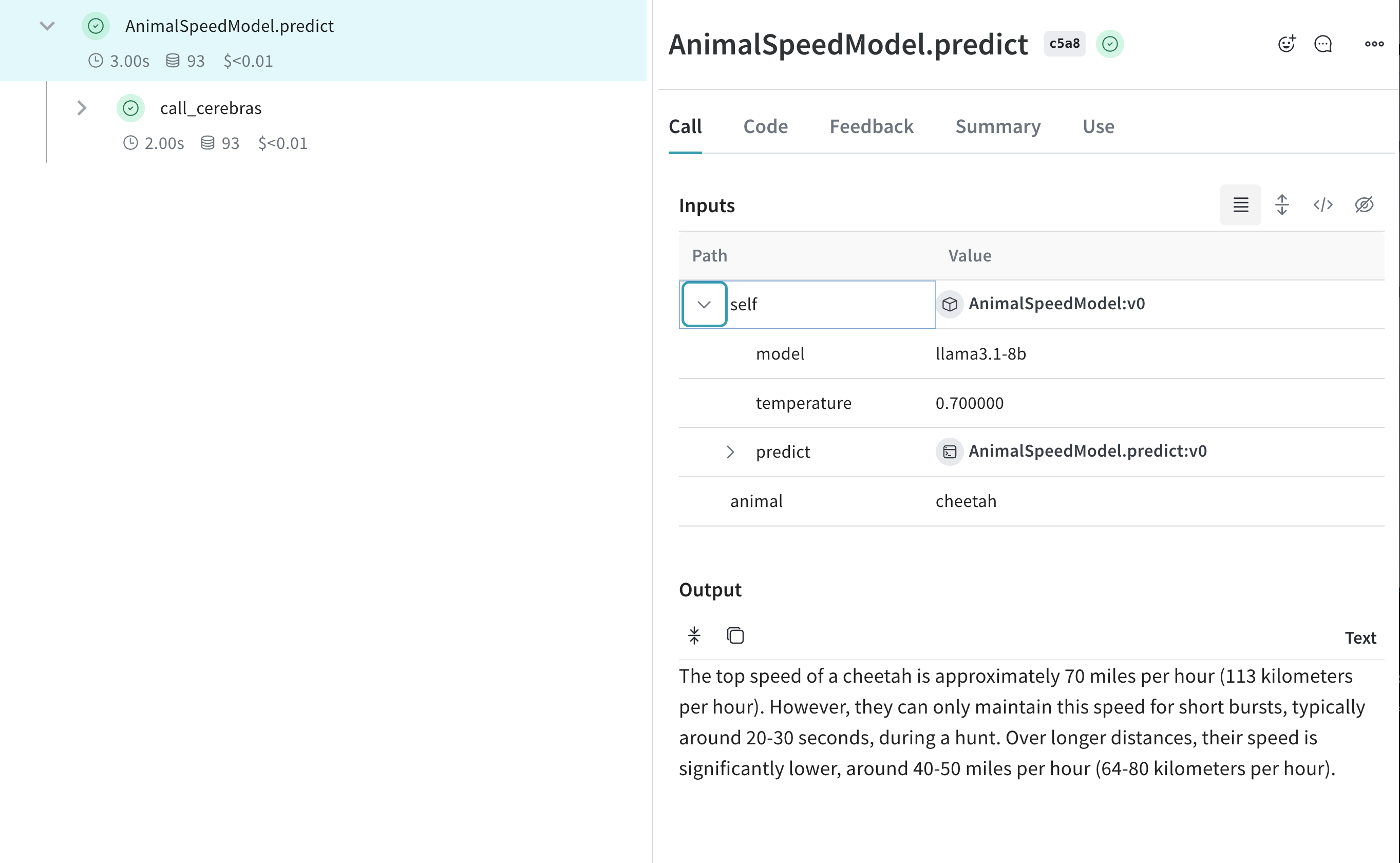
import os import weave from cerebras.cloud.sdk import Cerebras # weave プロジェクトを初期化する weave.init("cerebras_speedster") client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"]) class AnimalSpeedModel(weave.Model): model: str temperature: float @weave.op def predict(self, animal: str) -> str: "動物の最高速度を予測する" response = client.chat.completions.create( model=self.model, messages=[{"role": "user", "content": f"What's the top speed of a {animal}?"}], temperature=self.temperature ) return response.choices[0].message.content speed_model = AnimalSpeedModel( model="llama3.1-8b", temperature=0.7 ) result = speed_model.predict(animal="cheetah") print(result)
このページは役に立ちましたか?