- Python
- TypeScript
Scorers は評価時に
weave.Evaluation オブジェクトへ渡されます。Weave には 2 種類の Scorers があります:- 関数ベースの Scorers:
@weave.opでデコレートされたシンプルな Python 関数。 - クラスベースの Scorers: より複雑な評価のために
weave.Scorerを継承する Python クラス。
独自の Scorer を作成する
関数ベースのスコアラー
- Python
- TypeScript
これらは 評価を実行すると、
@weave.op デコレータを付けた関数で、辞書を返します。次のようなシンプルな評価に適しています。evaluate_uppercase はテキストがすべて大文字かどうかをチェックします。クラスベースの Scorer
- Python
- TypeScript
追加の Scorer メタデータを保持したい場合、LLM 評価用に異なるプロンプトを試したい場合、または関数を複数回呼び出したい場合など、より高度な評価には このクラスは、要約を元のテキストと比較することで、その要約の品質を評価します。
Scorer クラスを使用できます。要件:weave.Scorerを継承する。@weave.opデコレータを付けたscoreメソッドを定義する。scoreメソッドは辞書を返さなければならない。
Scorer の動作
Scorer のキーワード引数
- Python
- TypeScript
Scorer は、AI システムからの出力と、データセット行からの入力データの両方にアクセスできます。Weave の
これで、
- Input: Scorer でデータセット行のデータ(たとえば
"label"や"target"列)を使いたい場合は、scorer の定義にlabelやtargetというキーワード引数を追加するだけで、簡単に scorer から参照できるようにできます。
"label" という列を使いたい場合、scorer 関数(または score クラスメソッド)は次のような引数リストを持ちます:Evaluation が実行されると、AI システムの出力は output 引数に渡されます。Evaluation は、追加の scorer の引数名をデータセット列名に自動的にマッチさせようとします。Scorer の引数やデータセット列名をカスタマイズするのが難しい場合は、列マッピングを使用できます(詳細は後述)。- Output: AI システムの出力にアクセスするには、scorer 関数のシグネチャに
output引数を含めてください。
column_map による列名のマッピング
score メソッドの引数名が、データセット内の列名と一致しない場合があります。このような場合は、column_map を使って対応できます。クラスベースの scorer を使う場合は、scorer クラスを初期化する際に、Scorer の column_map 属性に辞書を渡します。この辞書は、score メソッドの引数名をデータセットの列名に対応付けます。形式は {scorer_keyword_argument: dataset_column_name} です。例:score メソッド内の text 引数には、news_article データセット列からのデータが渡されるようになります。補足:- 列をマッピングする別の同等の方法として、
Scorerを継承し、scoreメソッドをオーバーロードして列を明示的にマッピングすることもできます。
スコアリング用プロンプトから op の変数にアクセスする
| Variable | Description |
|---|---|
{article} | 入力引数 article の値 |
{max_length} | 入力引数 max_length の値 |
{inputs} | すべての入力引数を含む JSON 辞書 |
{output} | あなたの op が返す値 |
スコアラーの最終サマリー
- Python
- TypeScript
評価中、スコアラーはデータセットの各行に対して計算されます。評価全体の最終スコアを出すために、出力の返り値の型に応じて動作する
auto_summarize を用意しています。- 数値列に対しては平均値を計算
- 真偽値列に対しては件数と割合を計算
- その他の列タイプは無視されます
Scorer クラスの summarize メソッドをオーバーライドして、最終スコアの計算方法を独自に定義できます。summarize 関数は次のような引数を想定しています:- 単一のパラメータ
score_rows: これは辞書のリストであり、それぞれの辞書には、データセットの単一行に対してscoreメソッドが返したスコアが含まれます。 - サマリー(集約)済みスコアを含む辞書を返す必要があります。
この例では、デフォルトの auto_summarize は True の件数と割合を返したはずです。
さらに詳しく知りたい場合は、CorrectnessLLMJudge の実装を参照してください。Call への scorer の適用
.call() メソッドを使用します。これにより、scorer の結果を Weave のデータベース内の特定の call と関連付けることができます。
.call() メソッドの使い方の詳細については、Calling Ops ガイドを参照してください。
- Python
- TypeScript
基本的な例を次に示します。同じ call に複数の scorer を適用することもできます。注意:
- scorer の結果は自動的に Weave のデータベースに保存されます
- scorer はメインのオペレーションが完了した後に非同期で実行されます
- UI で scorer の結果を確認するか、API 経由でクエリできます
preprocess_model_input を使用する
preprocess_model_input パラメータを使用できます。
使い方と例については、評価前にデータセットの行を整形するための preprocess_model_input の使用 を参照してください。
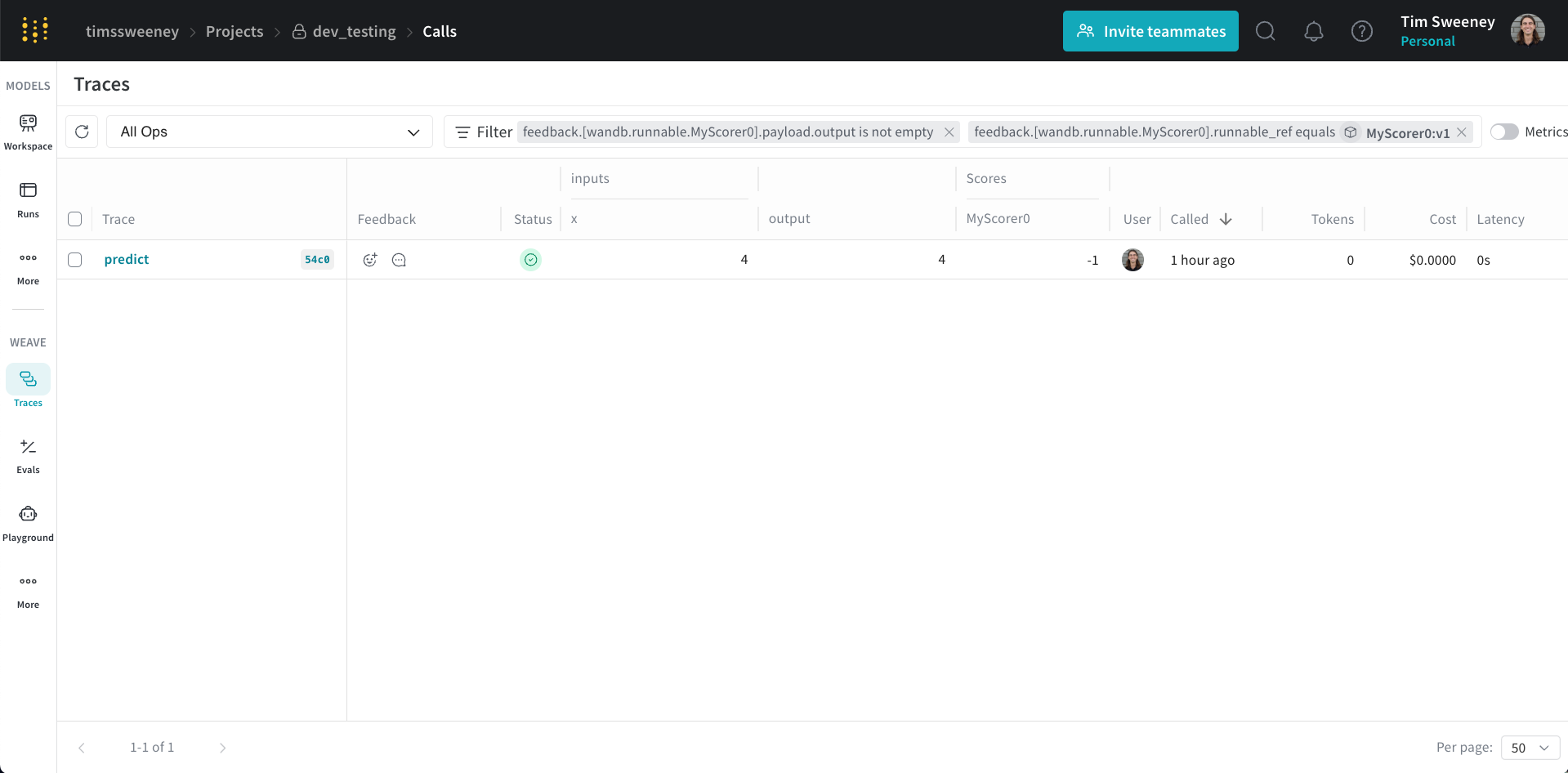
スコア分析
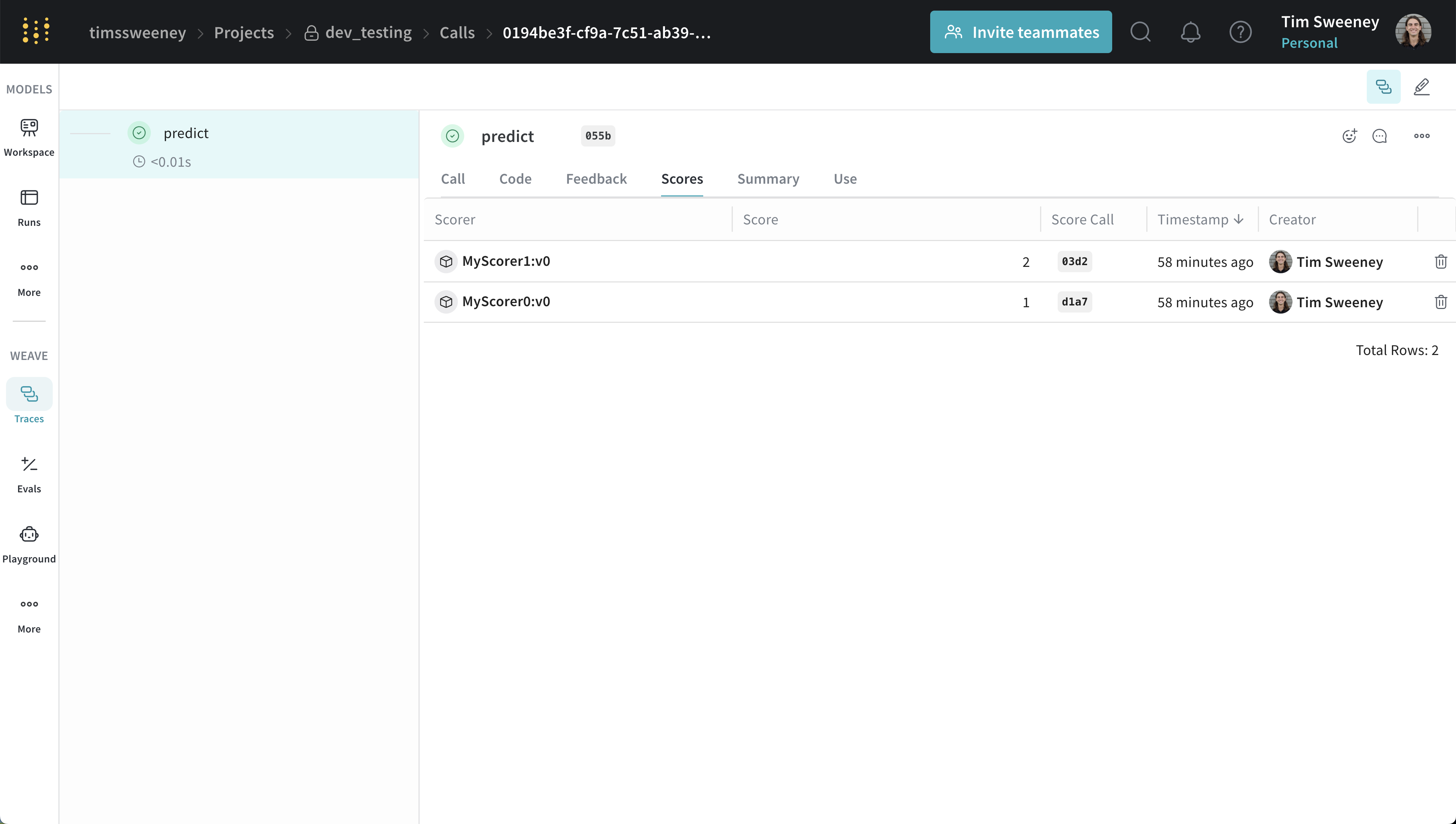
単一の Call のスコアを分析する
単一 Call の API
get_call メソッドを使用します。
単一 Call の UI
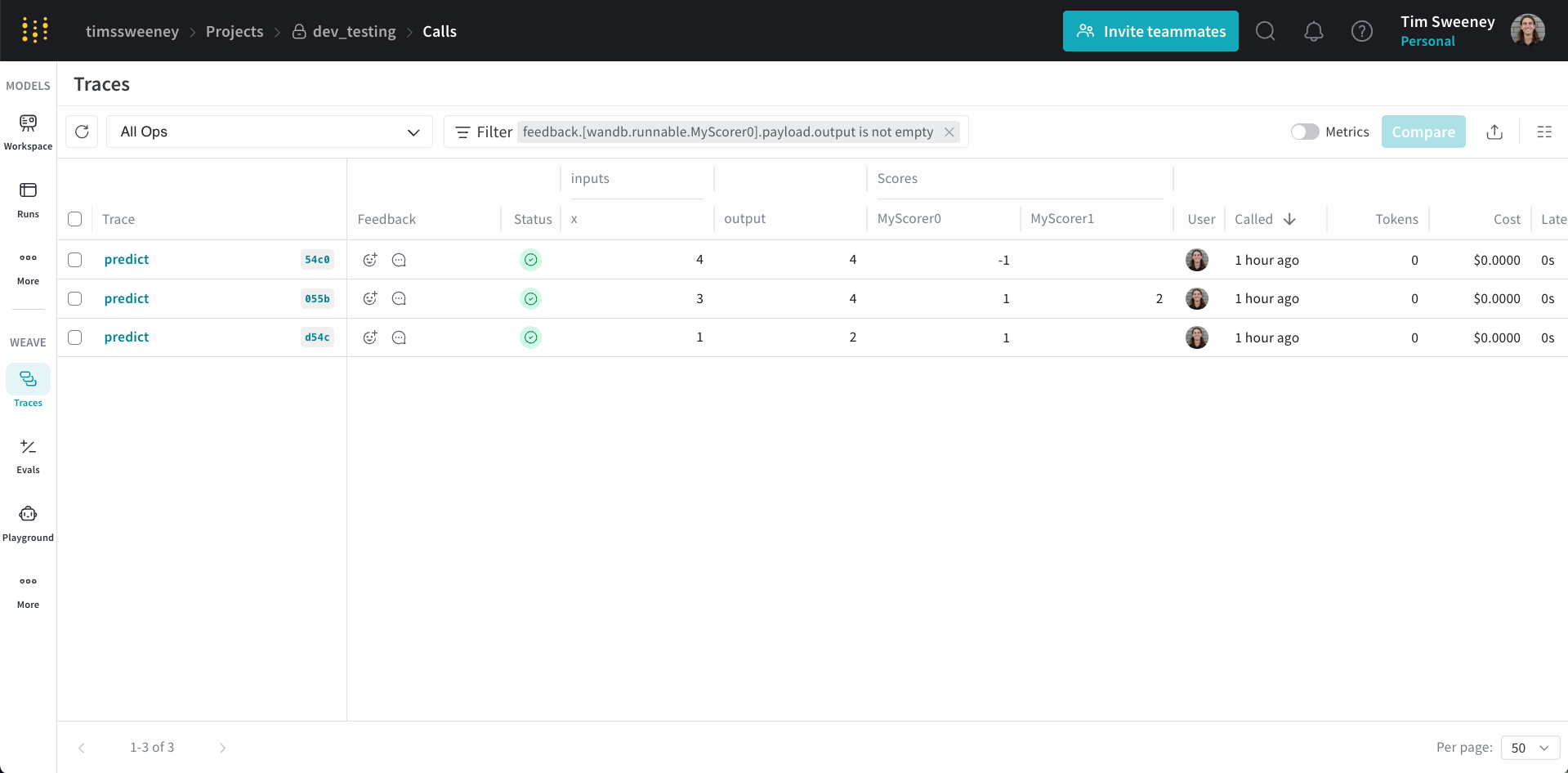
複数の Call のスコアを分析する
複数 Call API
get_calls メソッドを使用します。
複数 Call 用 UI
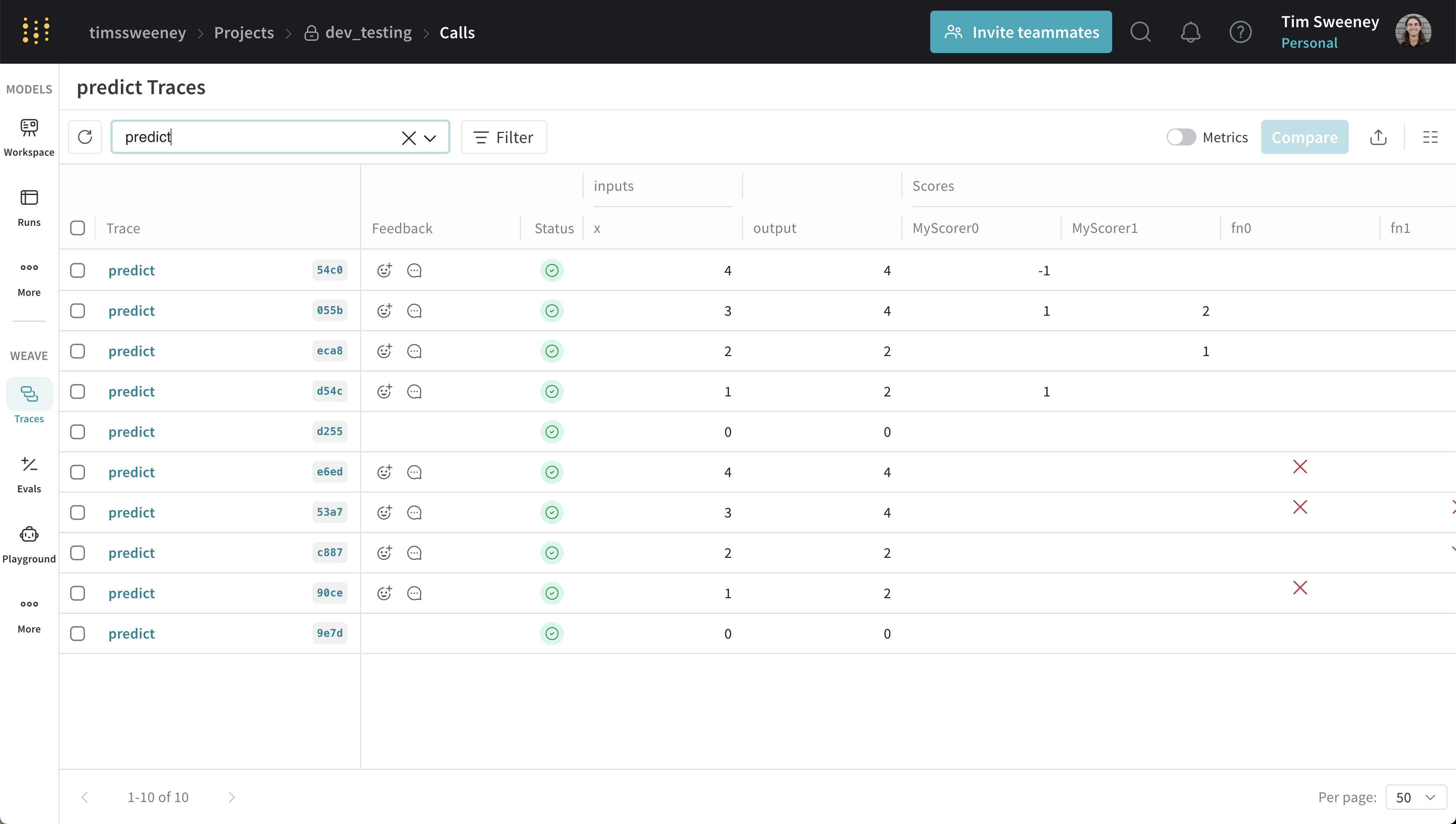
特定の Scorer がスコアリングしたすべての Call を分析する
特定の Scorer がスコアリングしたすべての Call(API)
get_calls メソッドを使用します。
Scorer ごとのすべての Call を UI で確認する
Scores セクションの下にある View Traces ボタンをクリックして、その Scorer によってスコア付けされたすべての Call を表示します。