Weave でモニターを作成する方法
- W&B UI を開き、対象の Weave プロジェクトを開きます。
- Weave のサイドナビから Monitors を選択し、+ New Monitor ボタンを選択します。Create new monitor モーダルダイアログが開きます。
-
Create new monitor メニューで、次のフィールドを設定します:
- Name: 先頭は英字または数字である必要があります。英字、数字、ハイフン、アンダースコアを含めることができます。
- Description (任意): モニターが何を行うかを説明します。
- Active monitor トグル: モニターを有効または無効にします。
- Calls to monitor:
- Operations: 監視する 1 つ以上の
@weave.opを選択します。利用可能な op の一覧に表示されるには、その op を使用するトレースを少なくとも 1 回はログに記録しておく必要があります。 - Filter (任意): 対象とする呼び出しを絞り込みます(例:
max_tokensやtop_pなど)。 - Sampling rate: スコアリングする呼び出しの割合 (0% ~ 100%)。
- Operations: 監視する 1 つ以上の
- LLM-as-a-judge configuration:
- Scorer name: 先頭は英字または数字である必要があります。英字、数字、ハイフン、アンダースコアを含めることができます。
- Score Audio: 利用可能な LLM モデルをオーディオ対応モデルのみに絞り込み、Media Scoring JSON Paths フィールドを表示します。
- Score Images: 利用可能な LLM モデルを画像対応モデルのみに絞り込み、Media Scoring JSON Paths フィールドを表示します。
- Judge model: ops をスコアリングするモデルを選択します。メニューには、自分の W&B アカウントで設定済みの商用 LLM モデルおよび W&B Inference models が含まれます。オーディオ対応モデルには名前の横に Audio Input ラベルが付きます。選択したモデルについて、次の設定を行います:
- Configuration name: このモデル設定の名前。
- System prompt: 判定用モデルの役割とペルソナを定義します(例: “You are an impartial AI judge.”)。
- Response format: ジャッジがレスポンスを出力する形式(
json_objectやプレーンなtextなど)。 - Scoring prompt: ops をスコアリングするための評価タスクです。スコアリングプロンプト内で、ops からの prompt variables を参照できます。例: “Evaluate whether
{output}is accurate based on{ground_truth}.”
- Media Scoring JSON Paths: トレースデータからメディアを抽出するための JSONPath 式 (RFC 9535) を指定します。パスを指定しない場合、ユーザーからのメッセージに含まれるスコア可能なメディアはすべて含まれます。このフィールドは Score Audio または Score Images を有効にしたときに表示されます。
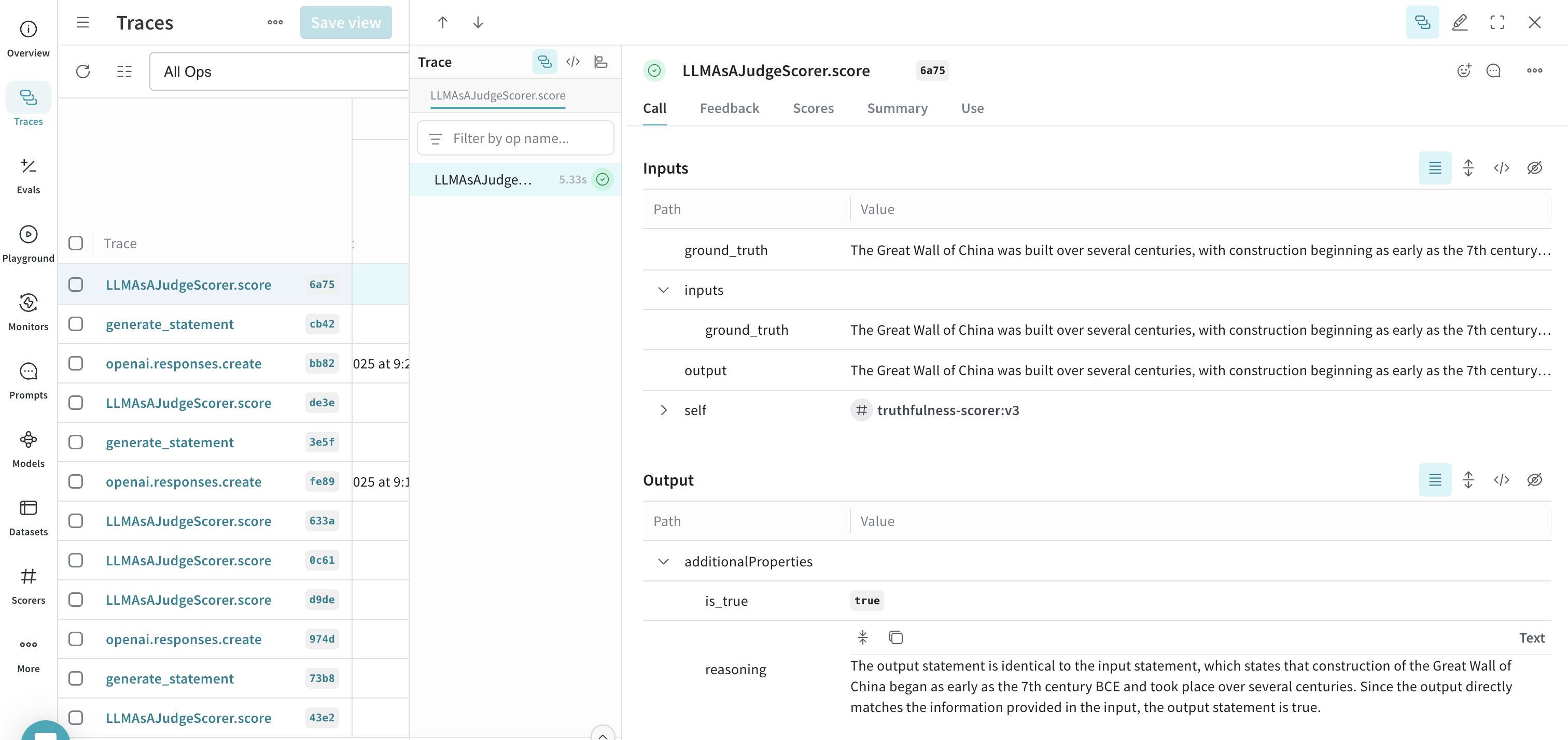
- モニターの各フィールドを設定したら、Create monitor をクリックします。これでモニターが Weave プロジェクトに追加されます。コードがトレースの生成を開始すると、Traces タブでモニター名を選択し、表示されたパネル内のデータを確認することでスコアを確認できます。
feedback フィールドに自動的に保存します。
例: truthfulness モニターを作成する
- 文を生成する関数を定義します。一部の文は真実であり、そうでないものもあります:
- Python
- TypeScript
- 関数を少なくとも 1 回実行して、プロジェクトにトレースを記録します。これにより、W&B UI でこの op をモニタリングに利用できるようになります。
- W&B UI で Weave プロジェクトを開き、サイドナビゲーションから Monitors を選択します。次に New Monitor を選択します。
-
Create new monitor メニューで、次の値を使ってフィールドを設定します:
- Name:
truthfulness-monitor - Description:
生成された文の真偽を評価します。 - Active monitor: on に切り替えます。
- Operations:
generate_statementを選択します。 - Sampling rate: すべての呼び出しをスコアリングするために
100%に設定します。 - Scorer name:
truthfulness-scorer - Judge model:
o3-mini-2025-01-31 - System prompt:
You are an impartial AI judge. Your task is to evaluate the truthfulness of statements. - Response format:
json_object - Scoring prompt:
- Name:
- Create Monitor をクリックします。これでモニターが Weave プロジェクトに追加されます。
- スクリプト内で、真偽の度合いが異なる文を使って関数を呼び出し、スコアリング関数をテストします:
- Python
- TypeScript
- 複数の異なる文でスクリプトを実行した後、W&B UI を開き、Traces タブに移動します。任意の LLMAsAJudgeScorer.score トレースを選択して結果を確認します。