W&B Report および Workspace API は Public Preview です。
レポートをプログラムから編集する場合は、W&B Python SDK に加えて W&B Report および Workspace API wandb-workspaces がインストールされていることを確認してください:pip install wandb wandb-workspaces
W&B App
Report and Workspace API
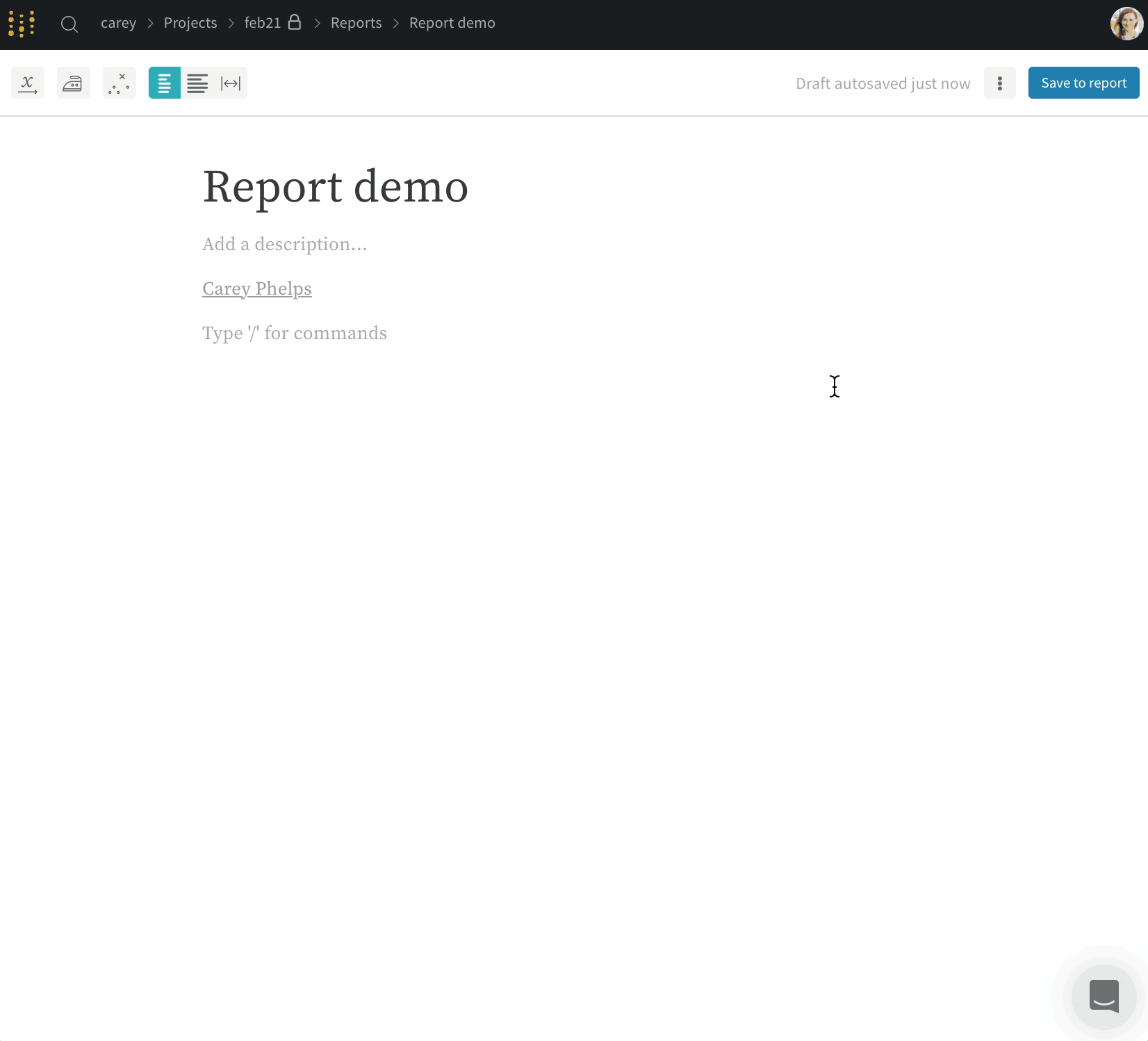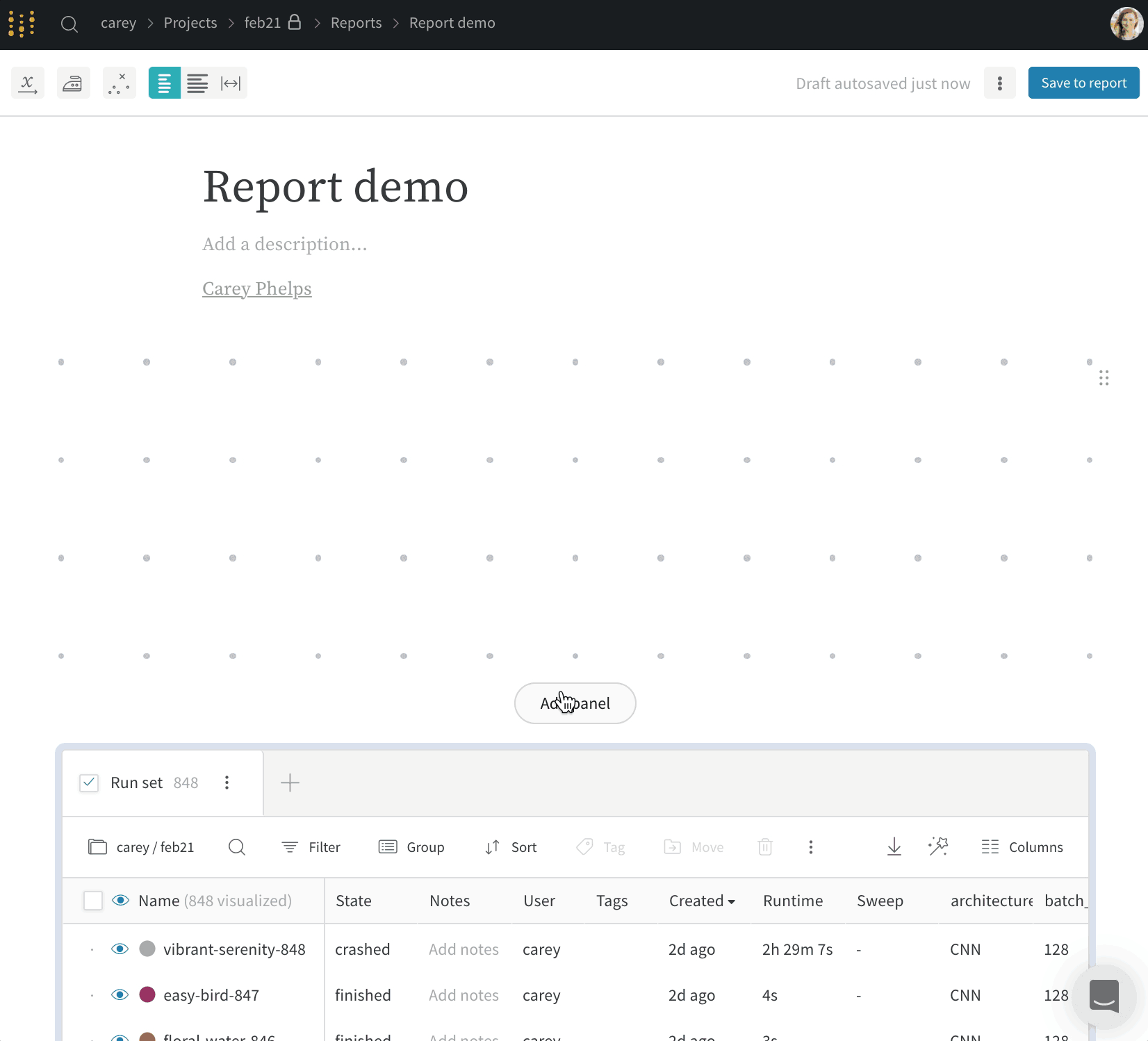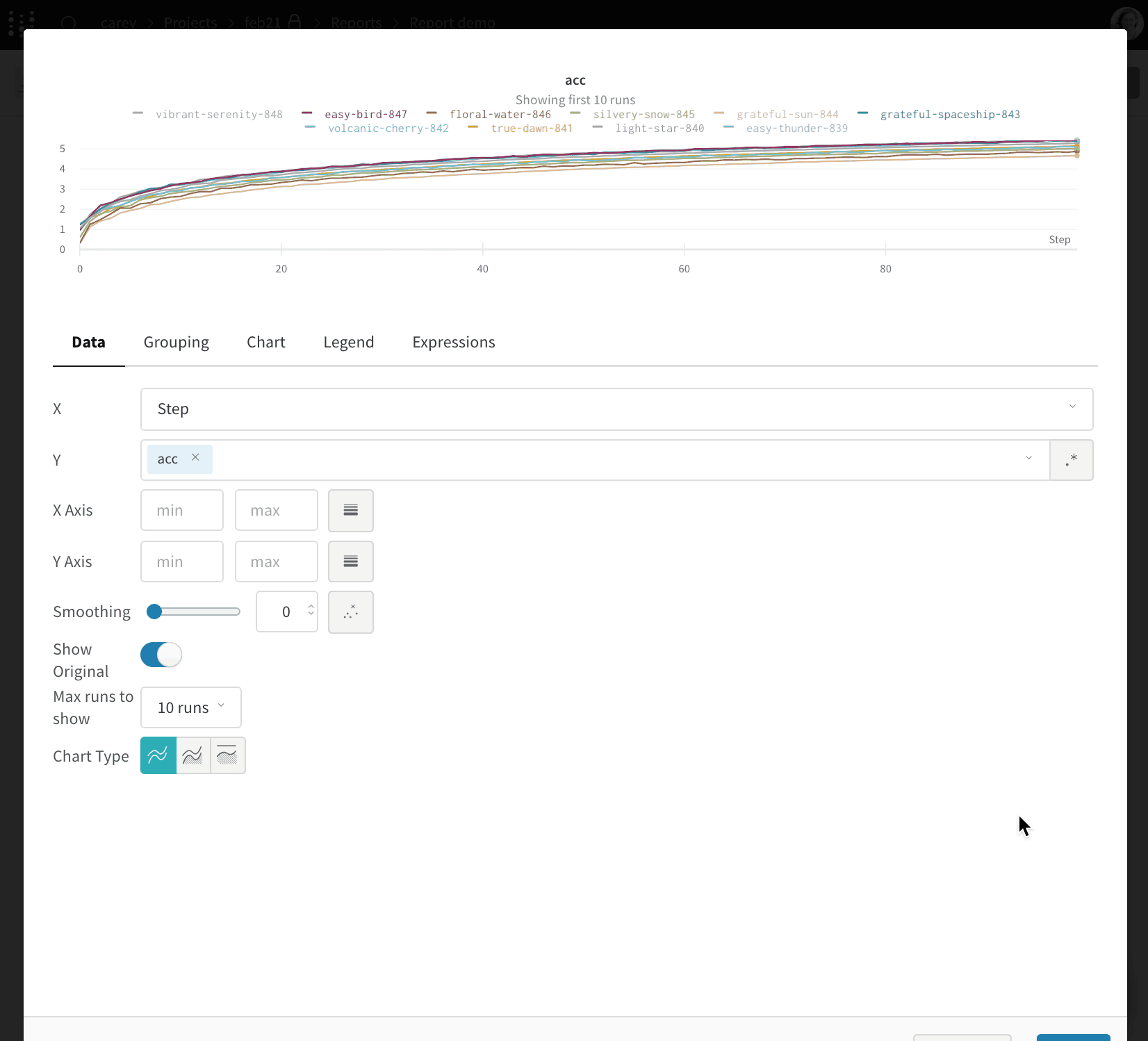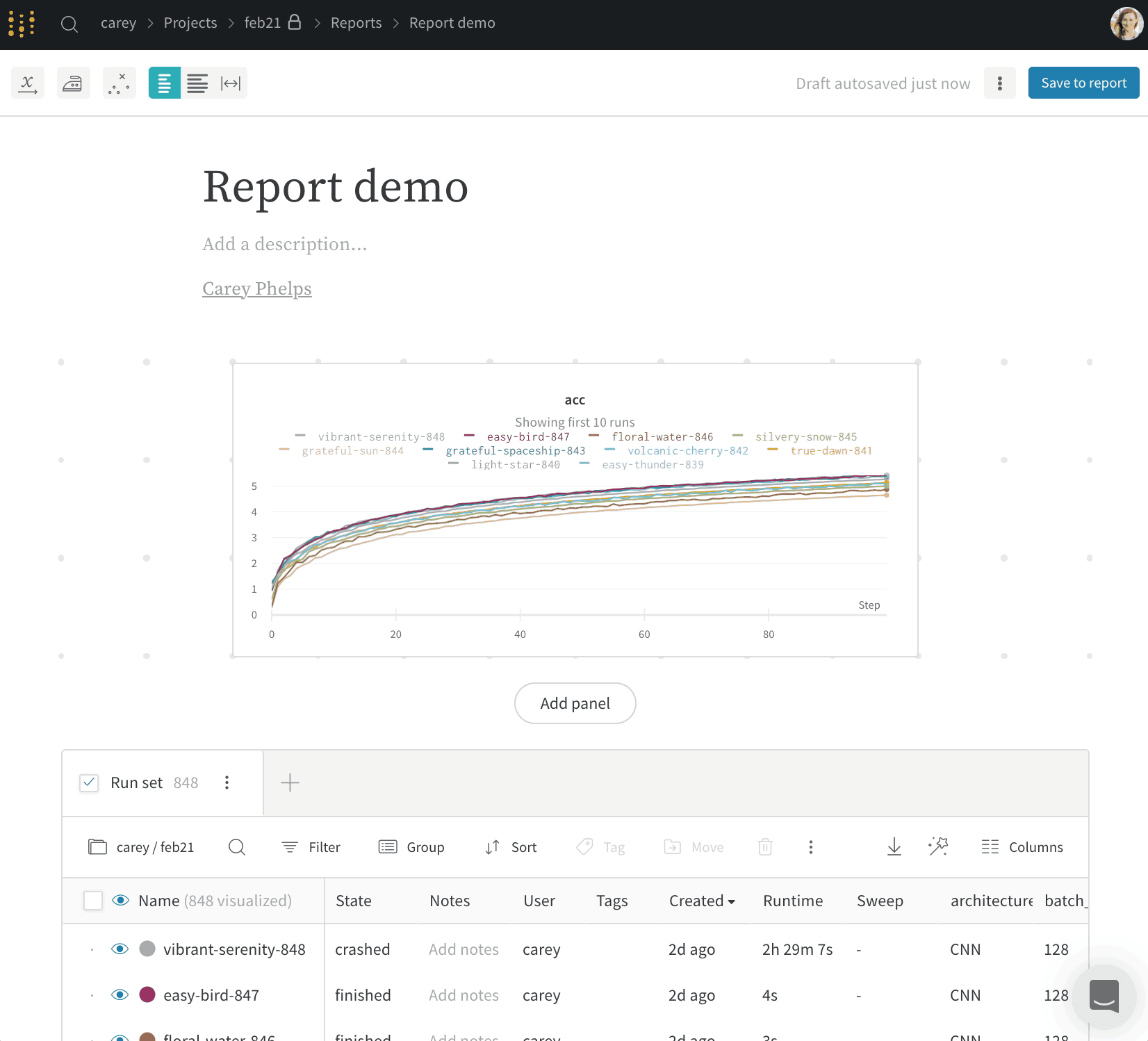
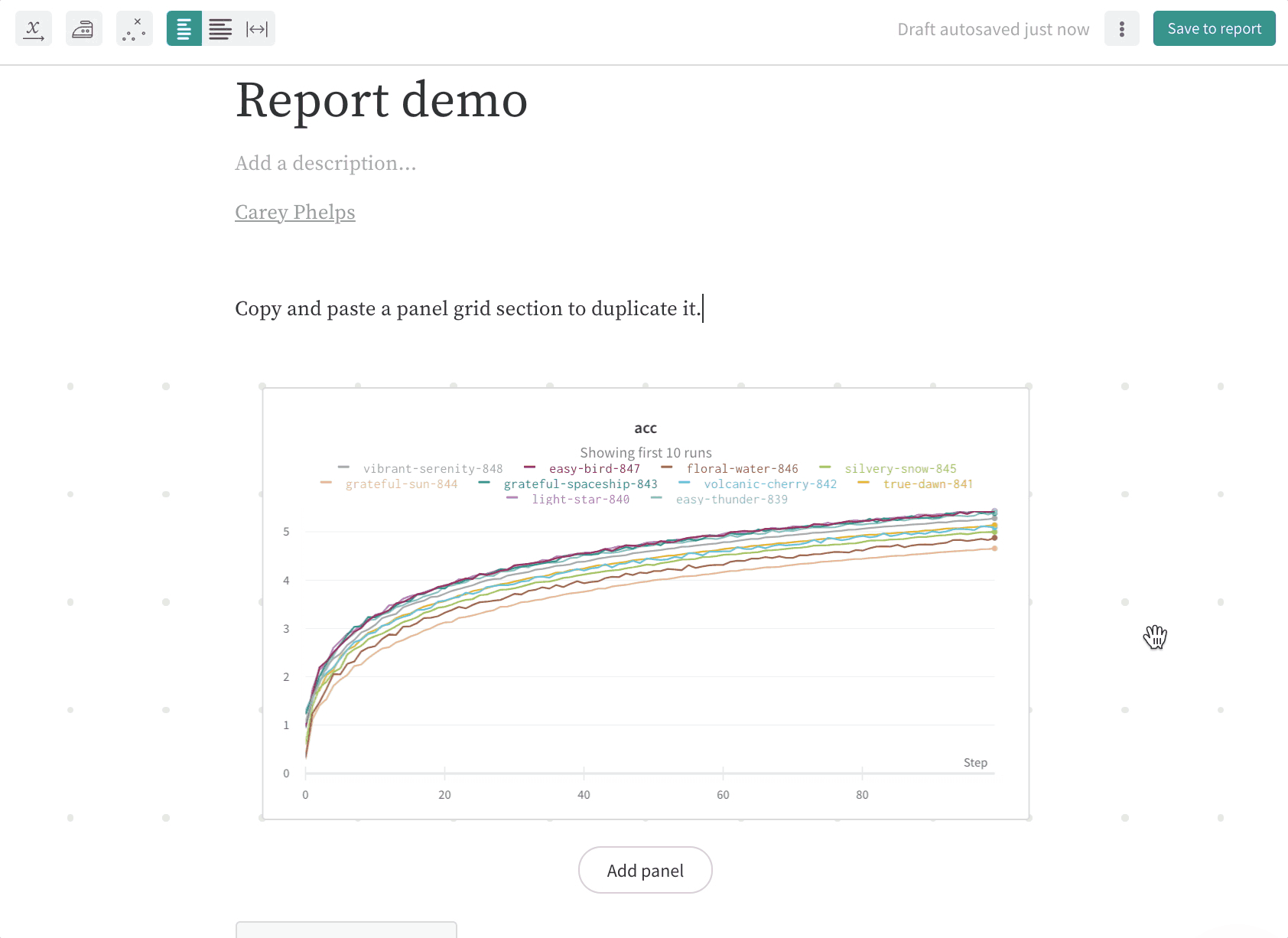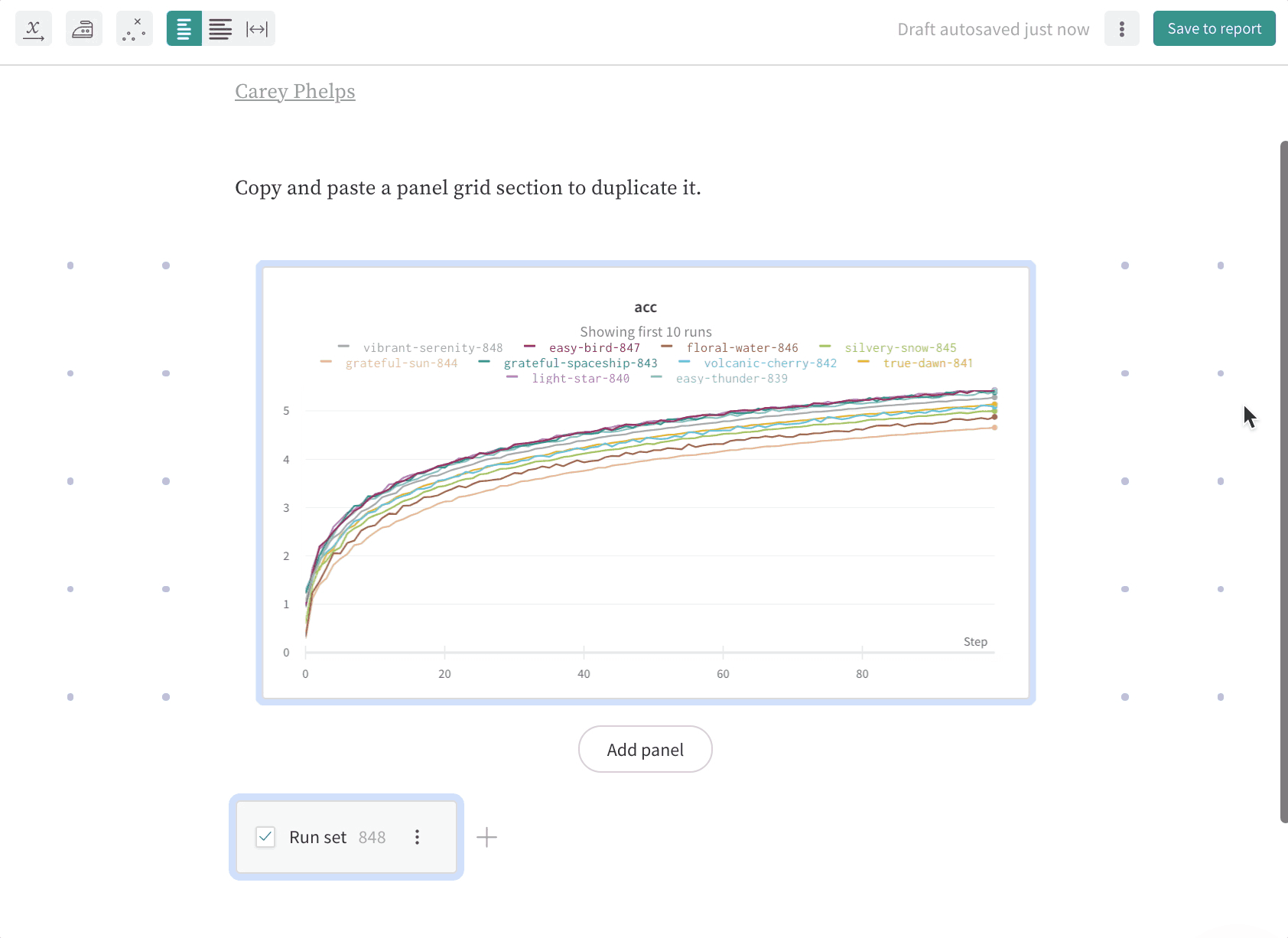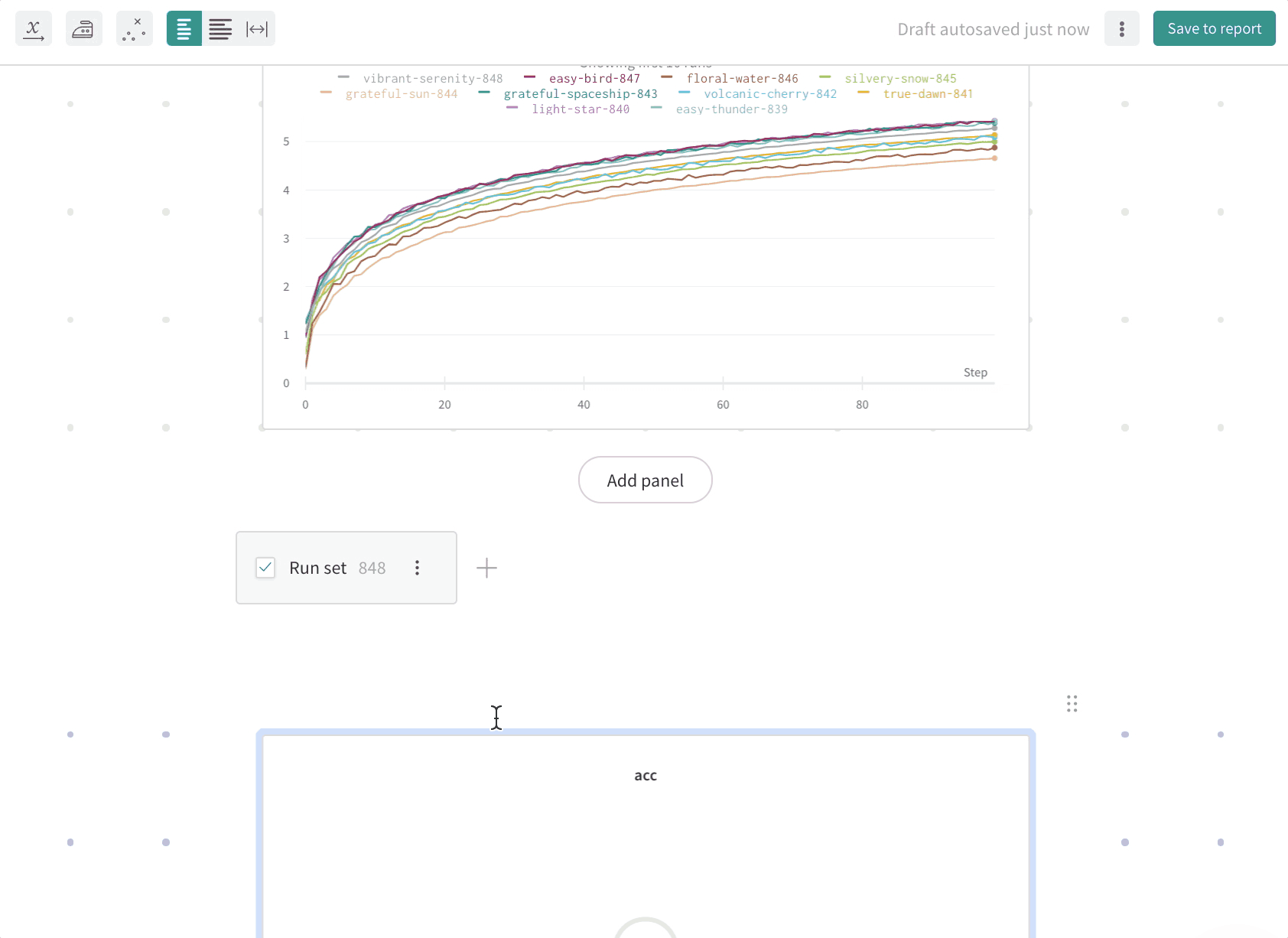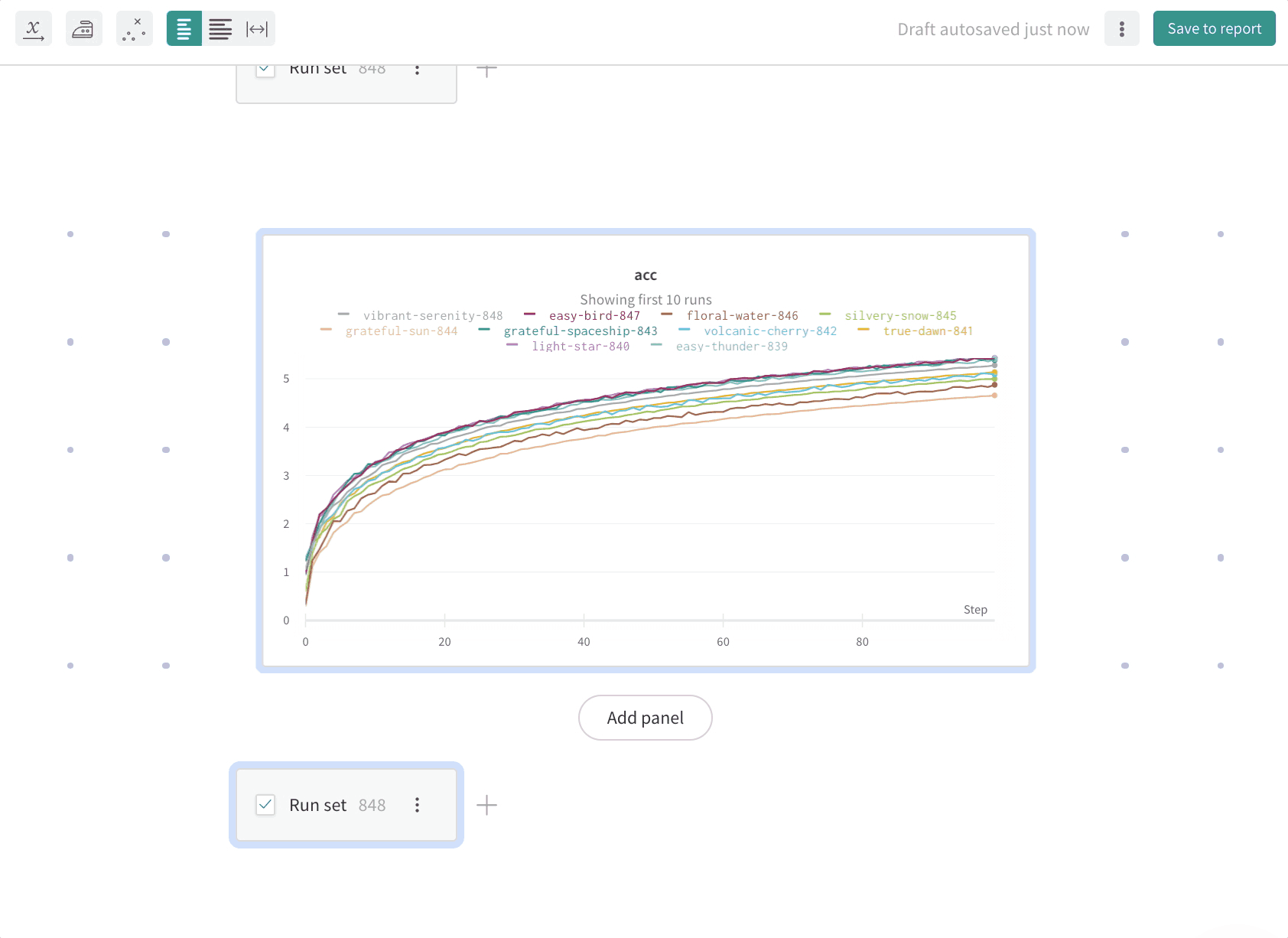
レポート内でスラッシュ(/)を入力するとドロップダウンメニューが表示されます。Add panel を選択してパネルを追加します。線グラフ、散布図、パラレルコーディネートチャートなど、W&B がサポートする任意のパネルを追加できます。 SDK を使ってプログラムからレポートにプロットを追加します。PanelGrid の Public API クラスの panels パラメータに、1 つ以上のプロットまたはチャートオブジェクトのリストを渡します。対応する Python クラスを使ってプロットまたはチャートオブジェクトを作成します。次の例は、線グラフと散布図を作成する方法を示しています。import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(
project="report-editing",
title="An amazing title",
description="A descriptive description.",
)
blocks = [
wr.PanelGrid(
panels=[
wr.LinePlot(x="time", y="velocity"),
wr.ScatterPlot(x="time", y="acceleration"),
]
)
]
report.blocks = blocks
report.save()
wr.panels を参照してください。 W&B App
Report and Workspace API
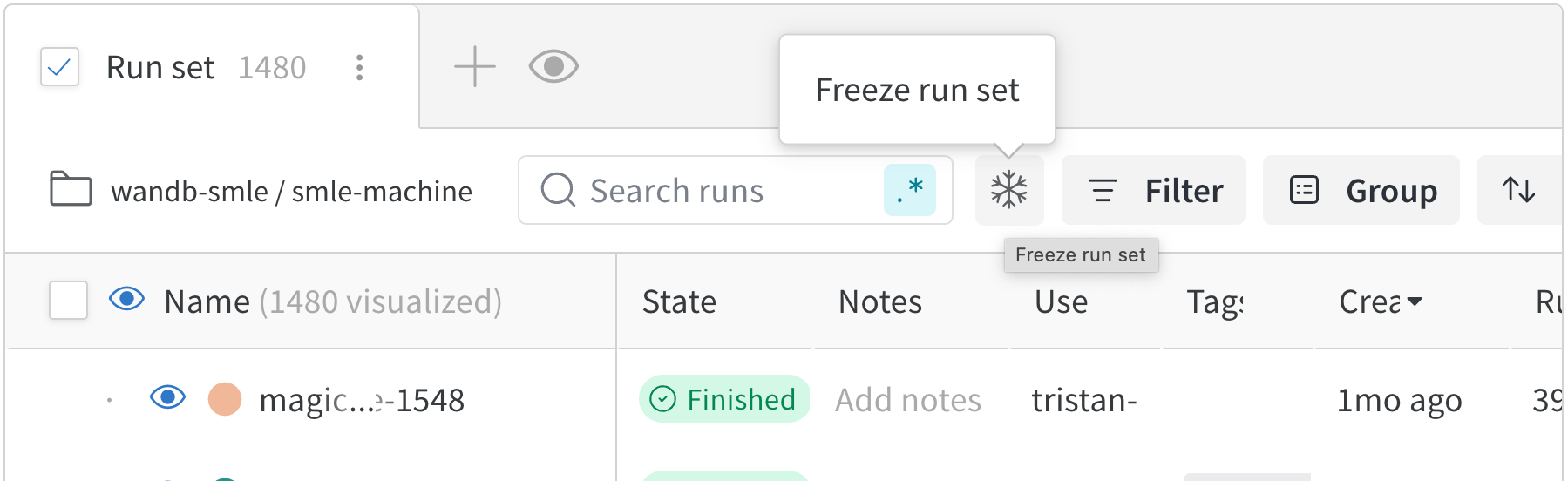
レポート内でスラッシュ(/)を入力するとドロップダウンメニューが表示されます。ドロップダウンから Panel Grid を選択します。これにより、そのレポートが作成されたプロジェクトから run セットが自動的にインポートされます。パネルをレポートにインポートすると、run 名はプロジェクトから継承されます。レポート内で、読者により多くのコンテキストを与えるために、任意でrun の名前を変更できます。run の名前が変更されるのは、その個々のパネル内だけです。同じレポート内でパネルをクローンした場合、クローンしたパネル内でも run の名前は変更されます。
-
レポート内で、鉛筆アイコンをクリックしてレポートエディタを開きます。
-
run セット内で、名前を変更する run を探します。その run 名にカーソルを合わせ、縦の三点リーダーをクリックします。次のいずれかを選択し、フォームを送信します。
- Rename run for project: プロジェクト全体で run の名前を変更します。新しいランダム名を生成するには、フィールドを空のままにします。
- Rename run for panel grid: 他のコンテキストでの既存の名前を保持したまま、レポート内でのみ run の名前を変更します。新しいランダム名の生成はサポートされていません。
-
Publish report をクリックします。
wr.Runset() と wr.PanelGrid クラスを使ってプロジェクトから run セットを追加します。以下の手順では runset の追加方法を説明します。
wr.Runset() オブジェクトインスタンスを作成します。project 引数には run セットを含むプロジェクト名を、entity 引数にはそのプロジェクトを所有するエンティティを指定します。wr.PanelGrid() オブジェクトインスタンスを作成します。1 つ以上の runset オブジェクトのリストを run sets パラメータに渡します。- 1 つ以上の
wr.PanelGrid() オブジェクトインスタンスをリストに格納します。
- レポートインスタンスの
blocks 属性を、その PanelGrid インスタンスのリストで更新します。
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(
project="report-editing",
title="An amazing title",
description="A descriptive description.",
)
panel_grids = wr.PanelGrid(
runsets=[wr.RunSet(project="<project-name>", entity="<entity-name>")]
)
report.blocks = [panel_grids]
report.save()
import wandb
report = wr.Report(
project="report-editing",
title="An amazing title",
description="A descriptive description.",
)
panel_grids = wr.PanelGrid(
panels=[
wr.LinePlot(
title="line title",
x="x",
y=["y"],
range_x=[0, 100],
range_y=[0, 100],
log_x=True,
log_y=True,
title_x="x axis title",
title_y="y axis title",
ignore_outliers=True,
groupby="hyperparam1",
groupby_aggfunc="mean",
groupby_rangefunc="minmax",
smoothing_factor=0.5,
smoothing_type="gaussian",
smoothing_show_original=True,
max_runs_to_show=10,
plot_type="stacked-area",
font_size="large",
legend_position="west",
),
wr.ScatterPlot(
title="scatter title",
x="y",
y="y",
# z='x',
range_x=[0, 0.0005],
range_y=[0, 0.0005],
# range_z=[0,1],
log_x=False,
log_y=False,
# log_z=True,
running_ymin=True,
running_ymean=True,
running_ymax=True,
font_size="small",
regression=True,
),
],
runsets=[wr.RunSet(project="<project-name>", entity="<entity-name>")],
)
report.blocks = [panel_grids]
report.save()
| グループ化方法 | 説明 | 利用可能なキー |
|---|
| Config values | config の値でrunをグループ化する | wandb.init(config=) の config パラメータで指定した値 |
| Run metadata | runメタデータでrunをグループ化する | State、Name、JobType |
| Summary metrics | サマリーメトリクスでrunをグループ化する | wandb.Run.log() を使って run にログした値 |
(wandb.init(config=)) で指定するパラメータです。run を config 値でグループ化するには、config.<key> 構文を使用します。ここで <key> は、グループ化に使用したい config 値の名前です。
たとえば、次のコードスニペットでは、まず group 用の config 値を持つ run を初期化し、その後、group の config 値に基づいてレポート内の run をグループ化します。<entity> と <project> の値は、ご自身の W&B の entity 名とプロジェクト名に置き換えてください。
import wandb
import wandb_workspaces.reports.v2 as wr
entity = "<entity>"
project = "<project>"
for group in ["control", "experiment_a", "experiment_b"]:
for i in range(3):
with wandb.init(entity=entity, project=project, group=group, config={"group": group, "run": i}, name=f"{group}_run_{i}") as run:
# 学習をシミュレートする
for step in range(100):
run.log({
"acc": 0.5 + (step / 100) * 0.3 + (i * 0.05),
"loss": 1.0 - (step / 100) * 0.5
})
config.group の値ごとに run をグループ化できます。
runset = wr.Runset(
project=project,
entity=entity,
groupby=["config.group"] # "group" config値でグループ化
)
report = wr.Report(
entity=entity,
project=project,
title="Grouped Runs Example",
)
report.blocks = [
wr.PanelGrid(
runsets=[runset],
)
]
report.save()
Name)、状態(State)、またはジョブタイプ(JobType)ごとに runs をグループ化できます。
前の例に続き、次のコードスニペットで runs を名前ごとにグループ化できます。
runset = wr.Runset(
project=project,
entity=entity,
groupby=["Name"] # run名でグループ化
)
run の名前は、wandb.init(name=) パラメータで指定した名前です。名前を指定しない場合、W&B が run に対してランダムな名前を生成します。run の名前は、W&B App の該当 run の Overview ページから、またはプログラムから Api.runs().run.name を使って確認できます。
wandb.Run.log() を使って run にログする値です。run をログした後、W&B App の該当する run の Overview ページ内の Summary セクションで、サマリーメトリクスの名前を確認できます。
サマリーメトリクスで run をグループ化するための構文は summary.<key> です。ここで <key> は、グループ化に使用したいサマリーメトリクスの名前です。
たとえば、acc という名前のサマリーメトリクスをログする場合を考えます。
import wandb
import wandb_workspaces.reports.v2 as wr
entity = "<entity>"
project = "<project>"
for group in ["control", "experiment_a", "experiment_b"]:
for i in range(3):
with wandb.init(entity=entity, project=project, group=group, config={"group": group, "run": i}, name=f"{group}_run_{i}") as run:
# 学習をシミュレート
for step in range(100):
run.log({
"acc": 0.5 + (step / 100) * 0.3 + (i * 0.05),
"loss": 1.0 - (step / 100) * 0.5
})
summary.acc というサマリーメトリクスで run をグループ化できます。
runset = wr.Runset(
project=project,
entity=entity,
groupby=["summary.acc"] # サマリー値でグループ化
)
Filter('key') operation <value>
key はフィルタの名前、operation は比較演算子(例: >, <, ==, in, not in, or, and)、<value> は比較対象の値です。Filter は、適用したいフィルタの種類を表すプレースホルダです。利用可能なフィルタとその説明は、次の表のとおりです。
| Filter | Description | Available keys |
|---|
Config('key') | config の値でフィルタする | wandb.init(config=) の config パラメータで指定した値。 |
SummaryMetric('key') | サマリーメトリクスでフィルタする | wandb.Run.log() を使って run にログした値。 |
Tags('key') | タグでフィルタする | run に追加したタグ値(プログラムから、または W&B App から追加したもの)。 |
Metric('key') | run のプロパティでフィルタする | tags, state, displayName, jobType |
wr.PanelGrid(runsets=) に渡せます。レポートにさまざまな要素をプログラムから追加する方法については、このページ全体にある Report and Workspace API タブを参照してください。
次の例では、レポート内で run セットをフィルタする方法を示します。<> で囲まれた値は、自分の値に置き換えてください。
1つ以上の config 値で runset をフィルタします。config 値は、run の設定 (wandb.init(config=)) で指定するパラメータです。
たとえば、次のコードスニペットでは、まず learning_rate と batch_size の config 値を指定して run を初期化し、その後 learning_rate の config 値に基づいてレポート内の runs をフィルタします。
import wandb
config = {
"learning_rate": 0.01,
"batch_size": 32,
}
with wandb.init(project="<project>", entity="<entity>", config=config) as run:
# 学習コードをここに記述
pass
0.01 より大きい run をプログラムから絞り込むことができます。
import wandb_workspaces.reports.v2 as wr
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Config('learning_rate') > 0.01"
)
and 演算子を使うと、複数の config 値を指定してフィルタリングすることもできます。
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Config('learning_rate') > 0.01 and Config('batch_size') == 32"
)
report = wr.Report(
entity="<entity>",
project="<project>",
title="My Report"
)
report.blocks = [
wr.PanelGrid(
runsets=[runset],
panels=[
wr.LinePlot(
x="Step",
y=["accuracy"],
)
]
)
]
report.save()
tags)、run の状態 (state)、run 名 (displayName)、またはジョブタイプ (jobType) に基づいて run セットをフィルタリングします。
Metric フィルターは異なる構文を使用します。値はリストとして渡してください。Metric('key') operation [<value>]
import wandb
with wandb.init(project="<project>", entity="<entity>") as run:
for i in range(3):
run.name = f"run{i+1}"
# 学習コードをここに記述
pass
run1、run2、run3 の run を絞り込むには、次のコードを使用します。
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('displayName') in ['run1', 'run2', 'run3']"
)
run の名前は、W&B App の各 run の Overview ページ、またはプログラムで Api.runs().run.name を使って取得できます。
finished、crashed、running)で runset をフィルタリングする方法を示します。
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('state') in ['finished']"
)
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('state') not in ['crashed']"
)
wandb.Run.log() を使って run にログする値です。run をログした後は、W&B App の各 run の Overview ページにある Summary セクションで、サマリーメトリクスの名前を確認できます。
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="SummaryMetric('accuracy') > 0.9"
)
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('state') in ['finished'] and SummaryMetric('train/train_loss') < 0.5"
)
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Tags('training') == 'training'"
)
App UI
Report と Workspace API
レポート内でスラッシュ(/)を入力すると、ドロップダウンメニューが表示されます。ドロップダウンから Code を選択します。コードブロックの右側に表示されるプログラミング言語名を選択します。ドロップダウンが展開されるので、その中から使用するプログラミング言語の構文を選択します。JavaScript、Python、CSS、JSON、HTML、Markdown、YAML から選択できます。
wr.CodeBlock クラスを使用して、コードブロックをプログラムから作成します。language パラメーターと code パラメーターに、それぞれ言語名と表示したいコードを指定します。たとえば、次のコード例では YAML ファイル内のリストを示しています:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.CodeBlock(
code=["this:", "- is", "- a", "cool:", "- yaml", "- file"], language="yaml"
)
]
report.save()
this:
- is
- a
cool:
- yaml
- file
report = wr.Report(project="report-editing")
report.blocks = [wr.CodeBlock(code=["Hello, World!"], language="python")]
report.save()
App UI
レポートと Workspace API
レポート内でスラッシュ(/)を入力するとドロップダウンメニューが表示されます。ドロップダウンから Markdown を選択します。
wandb.apis.reports.MarkdownBlock クラスを使用して、プログラムでマークダウンブロックを作成します。文字列を text パラメータに渡します:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.MarkdownBlock(text="Markdown cell with *italics* and **bold** and $e=mc^2$")
]
アプリ UI
Report と Workspace API
レポート内でスラッシュ(/)を入力すると、ドロップダウンメニューが表示されます。ドロップダウンからテキストブロックの種類を選択します。たとえば、H2 見出しブロックを作成するには、Heading 2 オプションを選択します。
1 つ以上の HTML 要素のリストを wandb.apis.reports.blocks 属性に渡します。次の例は、H1、H2、箇条書きリストを作成する方法を示しています:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.H1(text="How Programmatic Reports work"),
wr.H2(text="Heading 2"),
wr.UnorderedList(items=["Bullet 1", "Bullet 2"]),
]
report.save()
App UI
Report と Workspace API
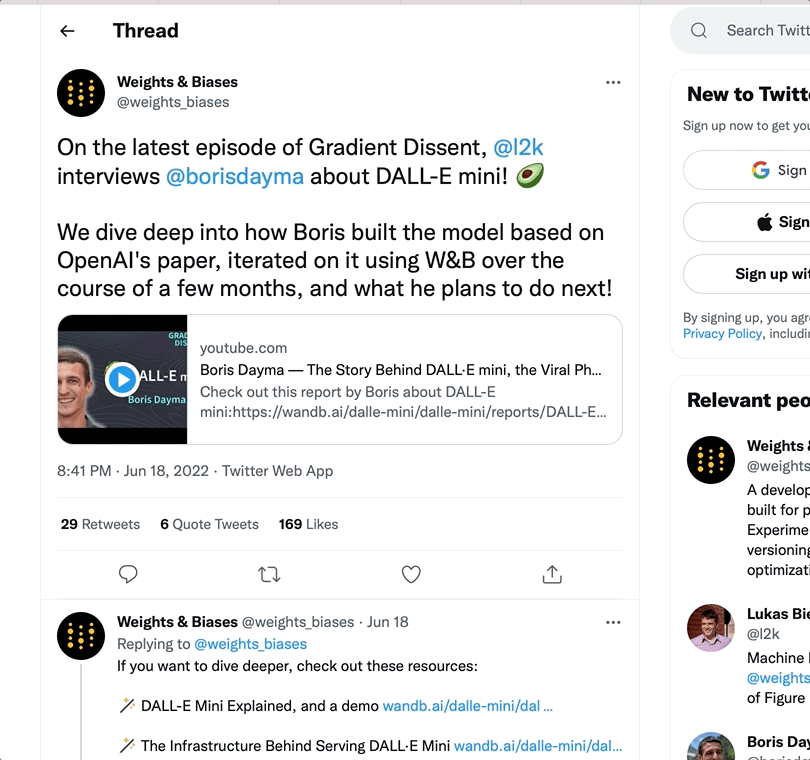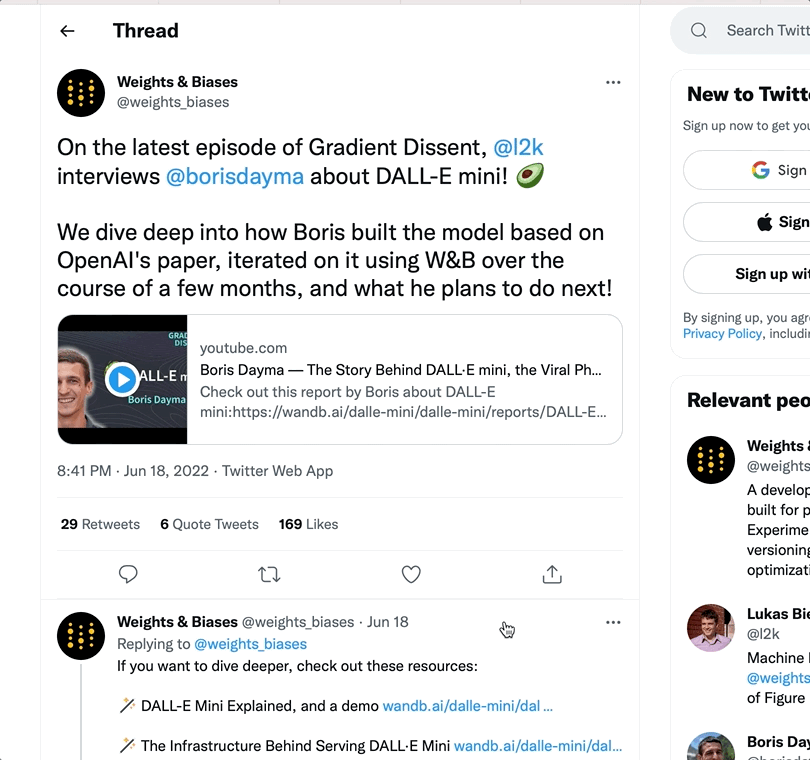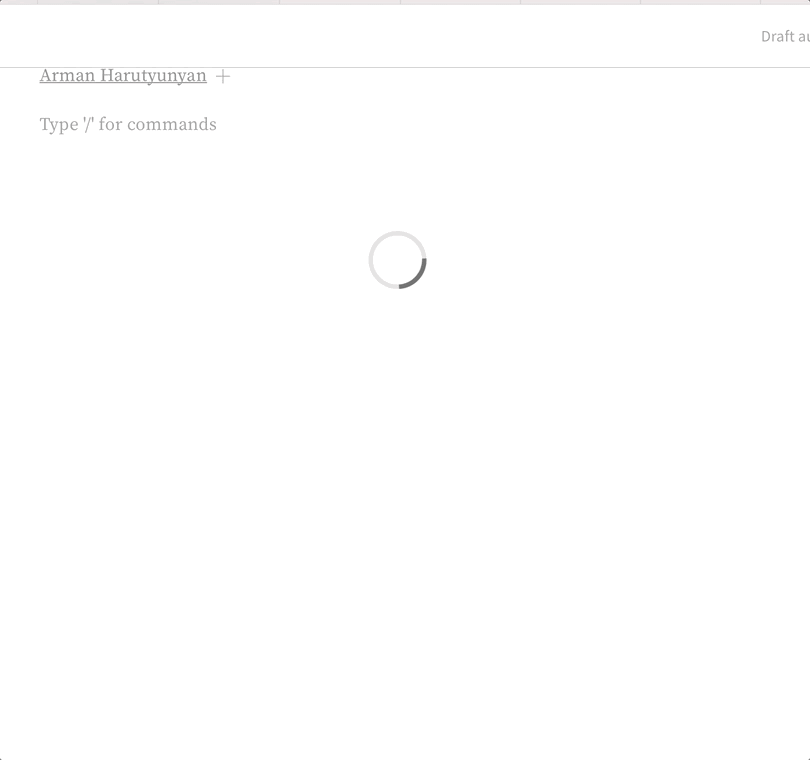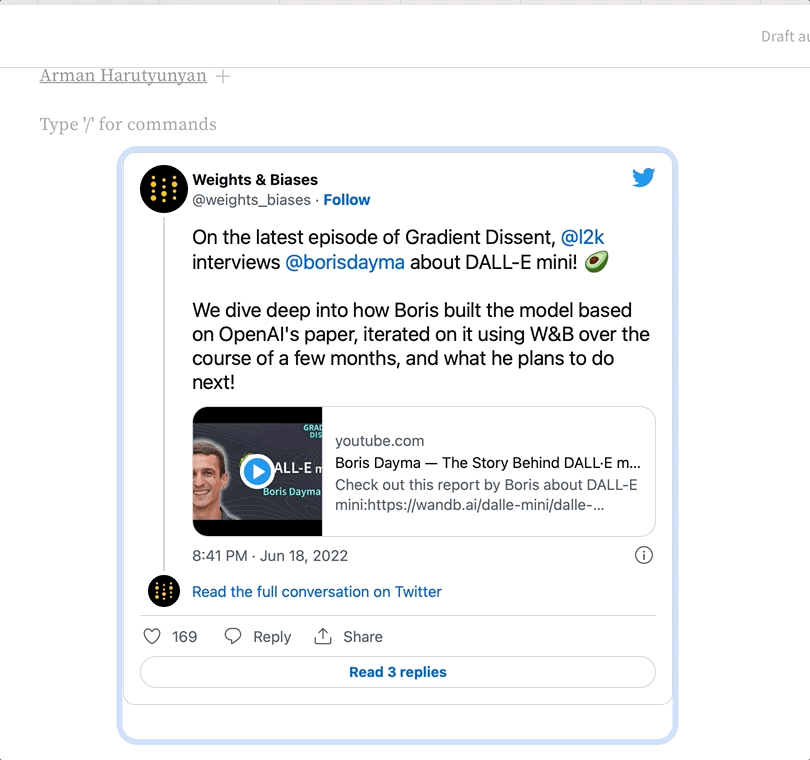
レポートに URL をコピーして貼り付けることで、レポート内にリッチメディアを埋め込めます。以下のアニメーションは、Twitter、YouTube、SoundCloud から URL をコピーして貼り付ける方法を示しています。ツイートのリンク URL をレポートにコピーして貼り付けると、レポート内でそのツイートを表示できます。Youtube
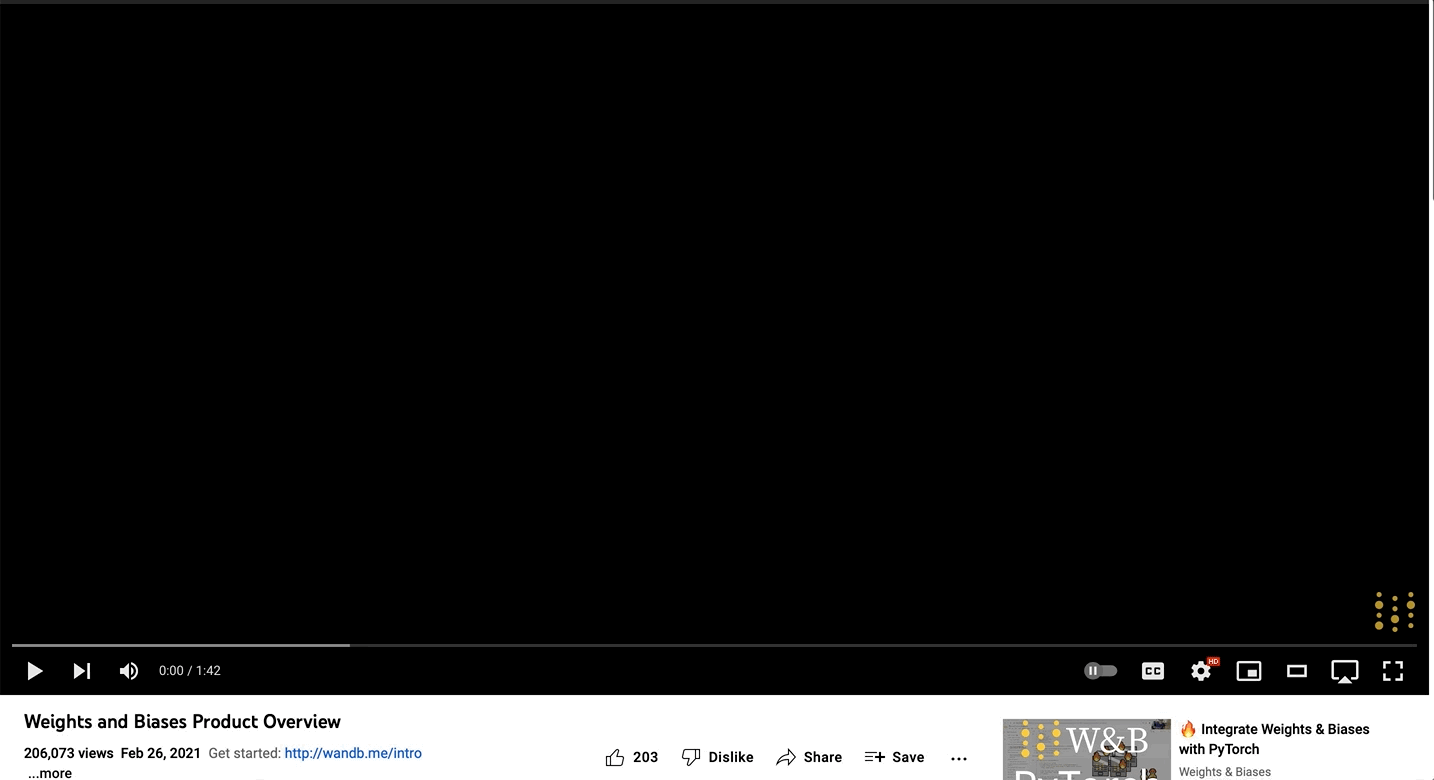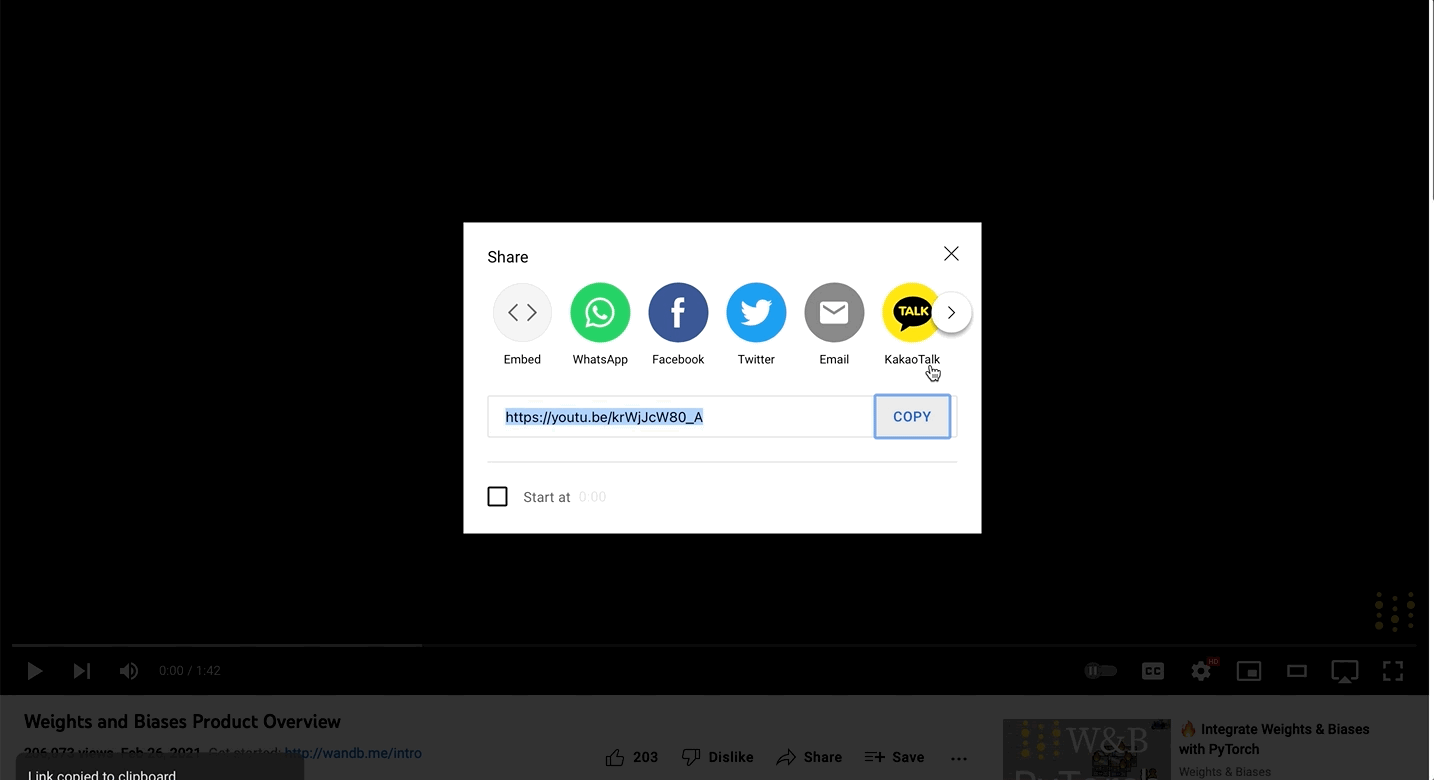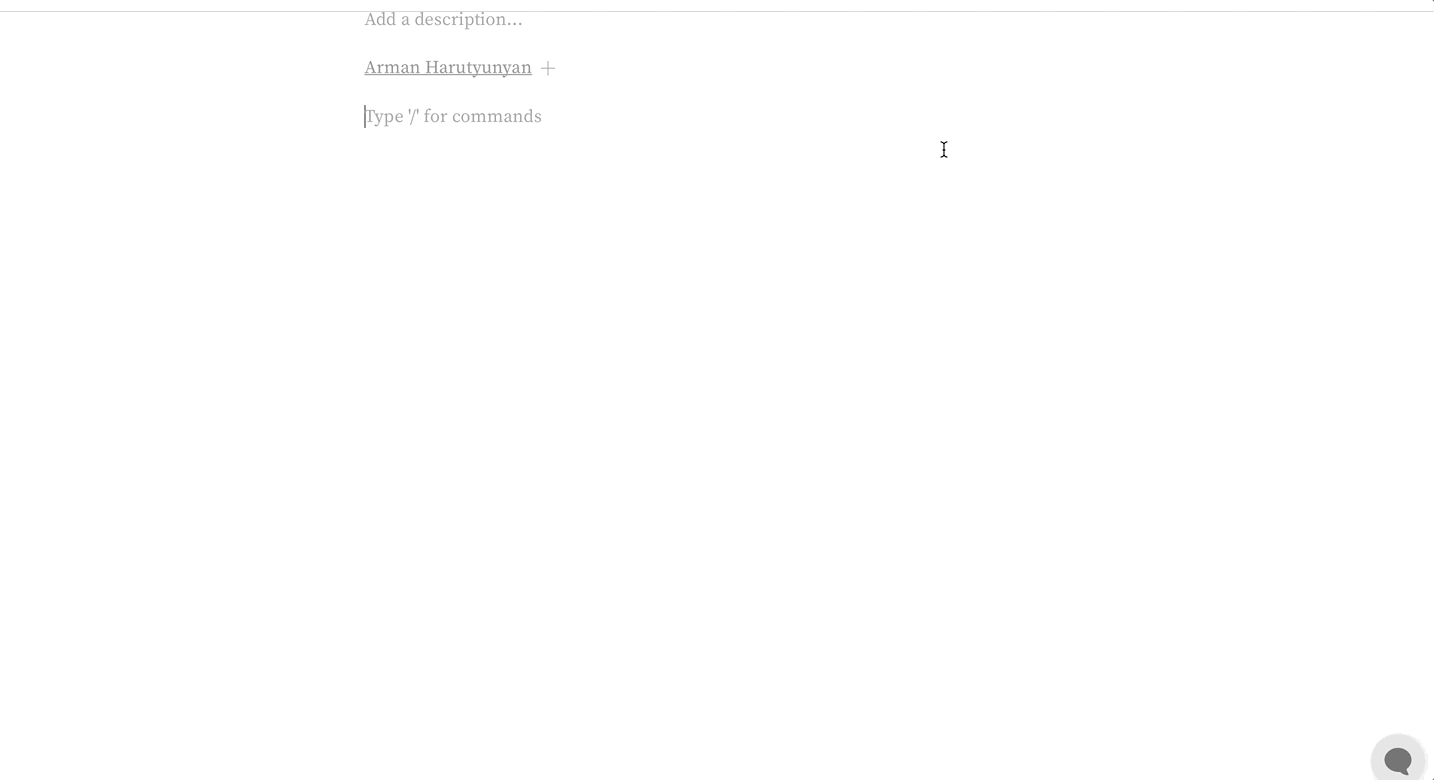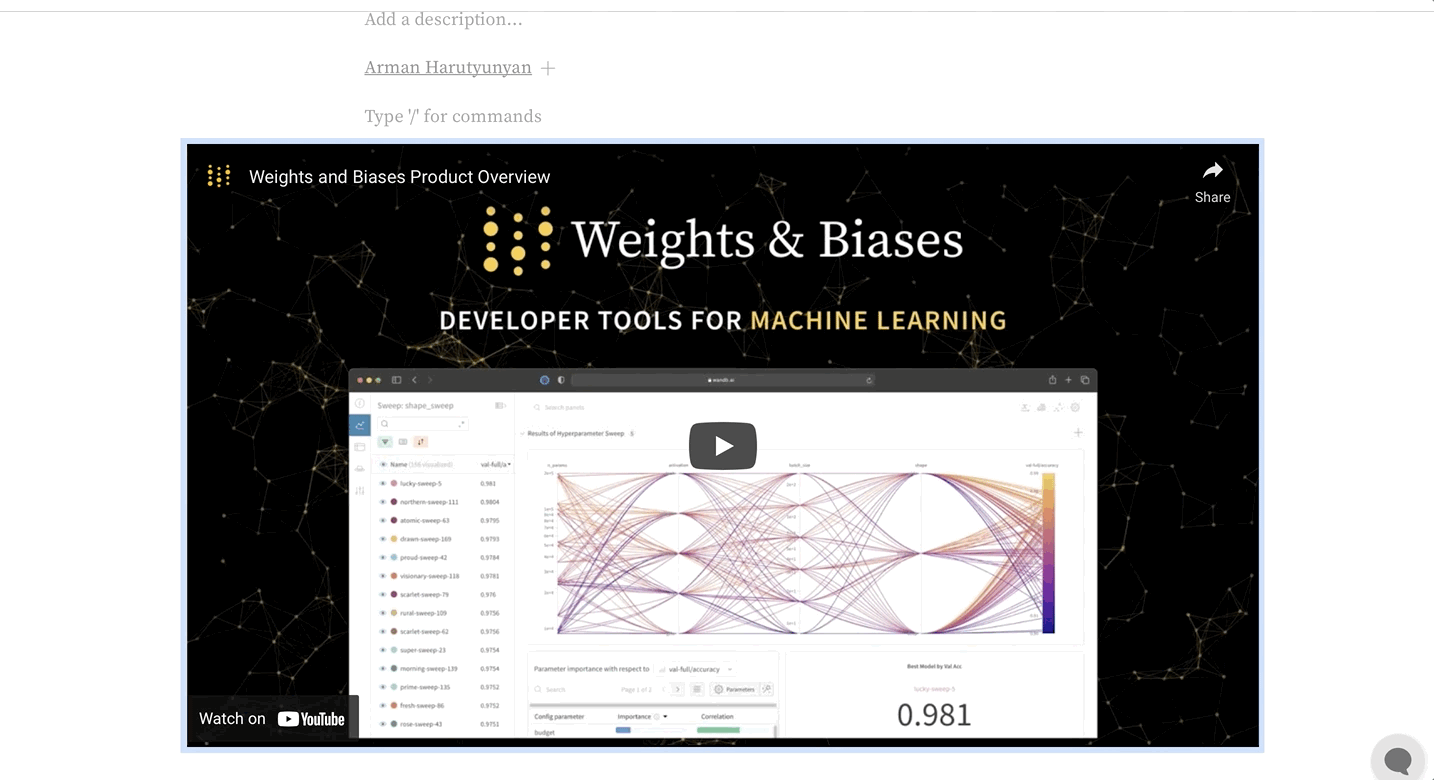
YouTube 動画の URL リンクをコピーして貼り付けると、レポート内に動画を埋め込めます。SoundCloud
SoundCloud のリンクをコピーして貼り付けると、レポートに音声ファイルを埋め込めます。 1 つ以上の埋め込みメディアオブジェクトのリストを wandb.apis.reports.blocks 属性に渡します。次の例は、動画と Twitter メディアをレポートに埋め込む方法を示しています。import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.Video(url="https://www.youtube.com/embed/6riDJMI-Y8U"),
wr.Twitter(
embed_html='<blockquote class="twitter-tweet"><p lang="en" dir="ltr">The voice of an angel, truly. <a href="https://twitter.com/hashtag/MassEffect?src=hash&ref_src=twsrc%5Etfw">#MassEffect</a> <a href="https://t.co/nMev97Uw7F">pic.twitter.com/nMev97Uw7F</a></p>— Mass Effect (@masseffect) <a href="https://twitter.com/masseffect/status/1428748886655569924?ref_src=twsrc%5Etfw">August 20, 2021</a></blockquote>\n'
),
]
report.save()
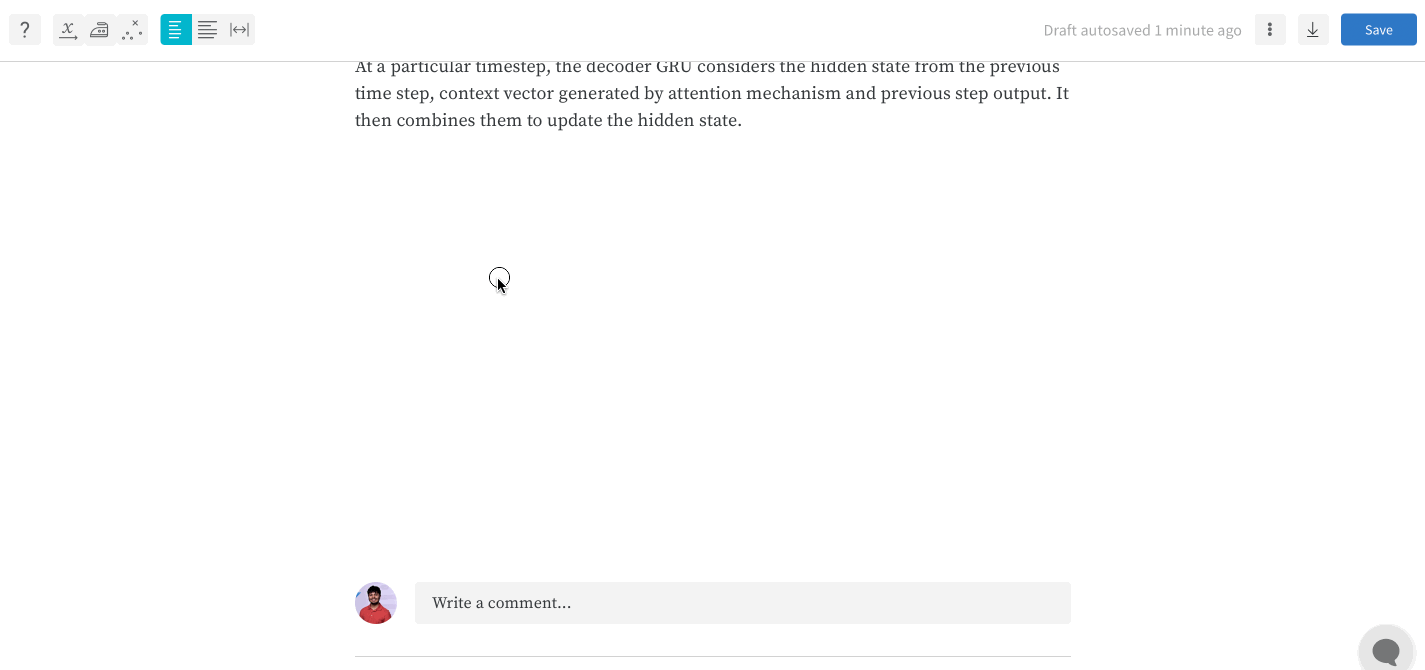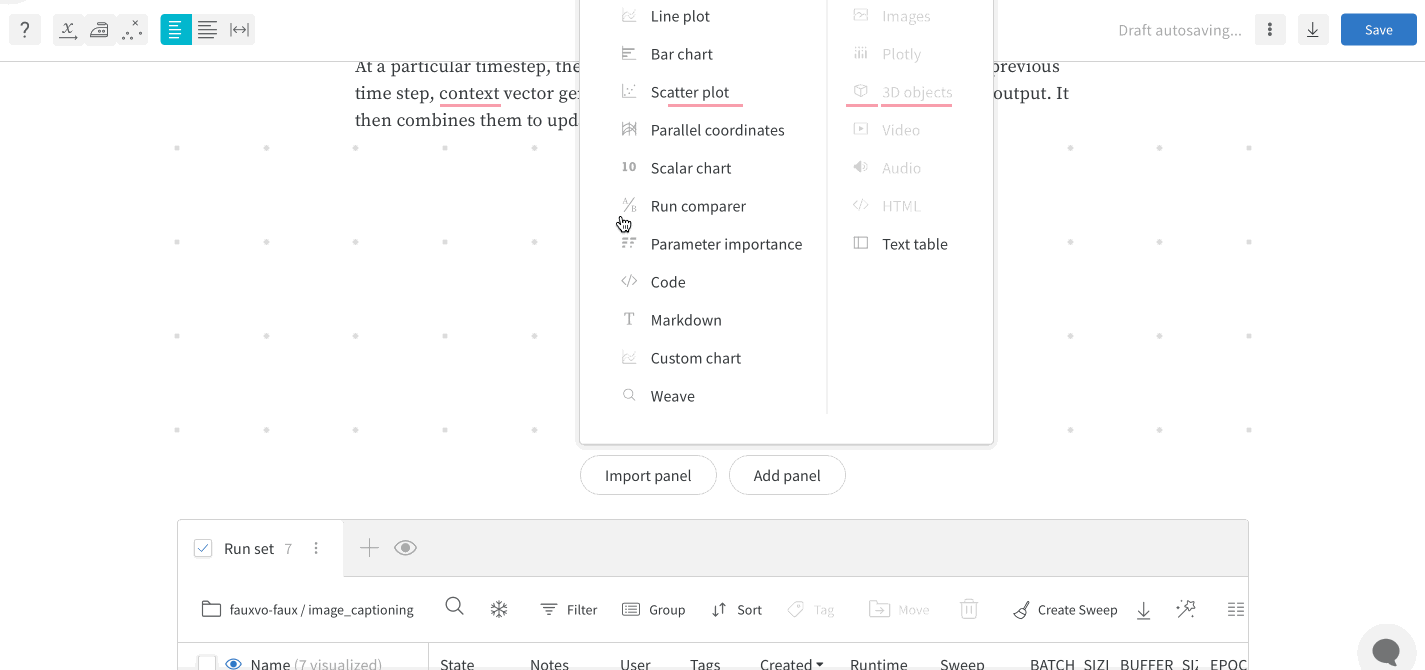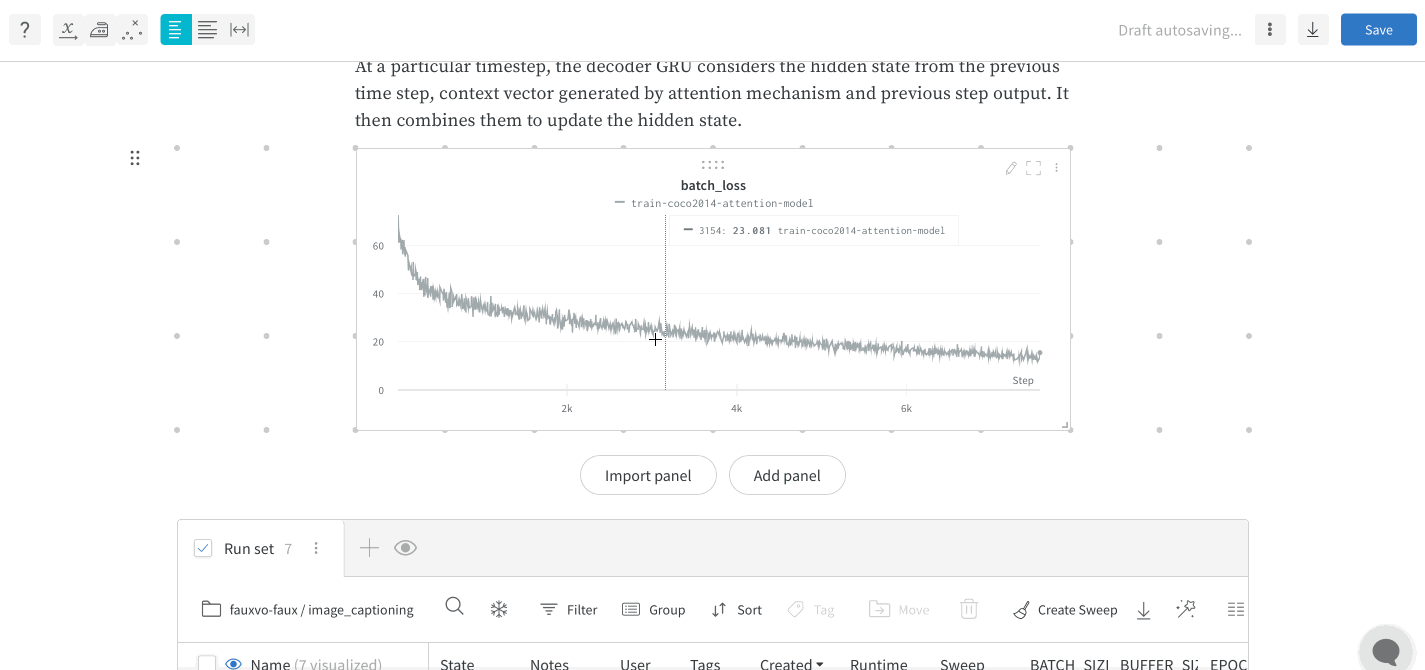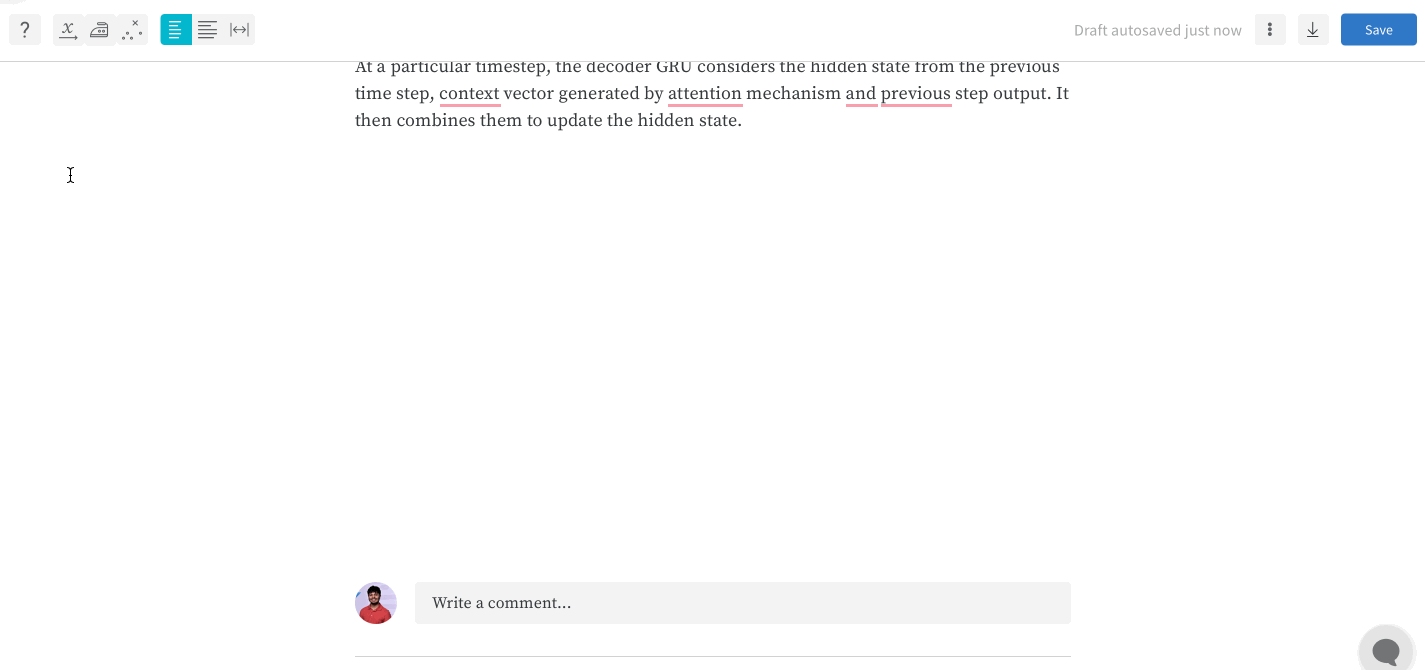
delete を押すと、パネルグリッドを削除できます。
レポート内のテキストブロックでは、ヘッダーを折りたたんで、その配下のコンテンツを非表示にできます。レポートが読み込まれたときには、展開されているヘッダーのコンテンツのみが表示されます。レポートでヘッダーを折りたたむと、コンテンツを整理し、不要なデータの読み込みを防ぐのに役立ちます。以下の GIF はこの手順を示しています。
複数の次元にまたがる関係を効果的に可視化するには、変数の1つを色のグラデーションで表現します。これにより視認性が高まり、パターンを解釈しやすくなります。
- 色のグラデーションで表現する変数を1つ選択します(例: ペナルティスコア、学習率など)。これにより、学習時間(x軸)に対して、ペナルティ(色)が報酬/副作用(y軸)とどのように相互作用するかを、より明確に理解できます。
- 重要なトレンドを強調します。特定の run グループにカーソルを合わせると、そのグループが可視化内でハイライト表示されます。