このガイドでは、Python ライブラリに Weights & Biases (W&B) を統合する方法を説明します。
学習フレームワーク、SDK、再利用可能なライブラリなどの複雑なコードベースに W&B を統合する場合は、ここで紹介する推奨事項に従ってください。
ここでは、単一の Python 学習スクリプトや Jupyter Notebook よりも複雑なコードベースで作業している場合の、主なヒントとベストプラクティスを紹介します。
ユーザーが W&B をどのようにインストールするかを決める
wandb) を追加してください。
torch==1.8.0
...
wandb==0.13.*
wandb を条件付きでインポートするか、pyproject.toml でオプションの依存関係として宣言します。
wandb が利用可能かどうかを検出し、ユーザーが W&B 機能を有効にしているのにインストールしていない場合は、明確なエラーを送出します:try:
import wandb
_WANDB_AVAILABLE = True
except ImportError:
_WANDB_AVAILABLE = False
wandb を pyproject.toml ファイルのオプション依存関係として宣言します:[project]
name = "my_awesome_lib"
version = "0.1.0"
dependencies = [
"torch",
"sklearn"
]
[project.optional-dependencies]
dev = [
"wandb"
]
よりシンプルに行うには、User Settings に直接アクセスしてAPIキーを作成してください。作成したばかりのAPIキーをすぐにコピーし、パスワードマネージャーなどの安全な場所に保管してください。
- 画面右上のユーザープロフィールアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
ローカル環境に wandb ライブラリをインストールしてログインするには、次の手順を実行します。
コマンドライン
Python
Python ノートブック
-
WANDB_API_KEY 環境変数 を自身の APIキー に設定します。
export WANDB_API_KEY=<your_api_key>
-
wandb ライブラリをインストールしてログインします。
pip install wandb
wandb login
-
ターミナルを開き、Python SDK をインストールします。
-
Python スクリプトまたはノートブックから W&B にログインします。APIキー の入力を求められます。
import wandb
wandb.login()
次のコードスニペットを Jupyter ノートブックのセルにコピーして貼り付け、実行します。APIキー の入力を求められます。!pip install wandb
import wandb
wandb.login()
wandb.init() で run を初期化し、プロジェクト名と team entity(チーム名)を指定します。プロジェクトを指定しない場合、W&B は run を「uncategorized」というデフォルトのプロジェクトに保存します。:
with wandb.init(project="<project_name>", entity="<entity>") as run:
...
run.finish() を呼び出して run を終了し、すべてのデータを W&B にログする必要があります。
wandb.init を呼び出すタイミング可能な限り早いタイミングで wandb.init() を呼び出してください。W&B は stdout、stderr、エラーメッセージを捕捉するため、デバッグが容易になります。すべての関連情報が run に記録されるように、wandb.init のコンテキストマネージャー内に学習ループ全体をラップしてください。これには、デバッグに重要となり得るあらゆるエラーメッセージも含まれます。
wandb をオプション扱いにしたい場合、次のいずれかの方法を選べます。
trainer = my_trainer(..., use_wandb=True)
python train.py ... --use-wandb
- または、
wandb.init で wandb を disabled に設定する:
wandb.init(mode="disabled")
export WANDB_MODE=disabled
- または、
wandb をオフラインモードに設定する — この場合も wandb は実行されますが、インターネット経由で W&B と通信しようとしません:
Environment Variable
Bash
export WANDB_MODE=offline
os.environ['WANDB_MODE'] = 'offline'
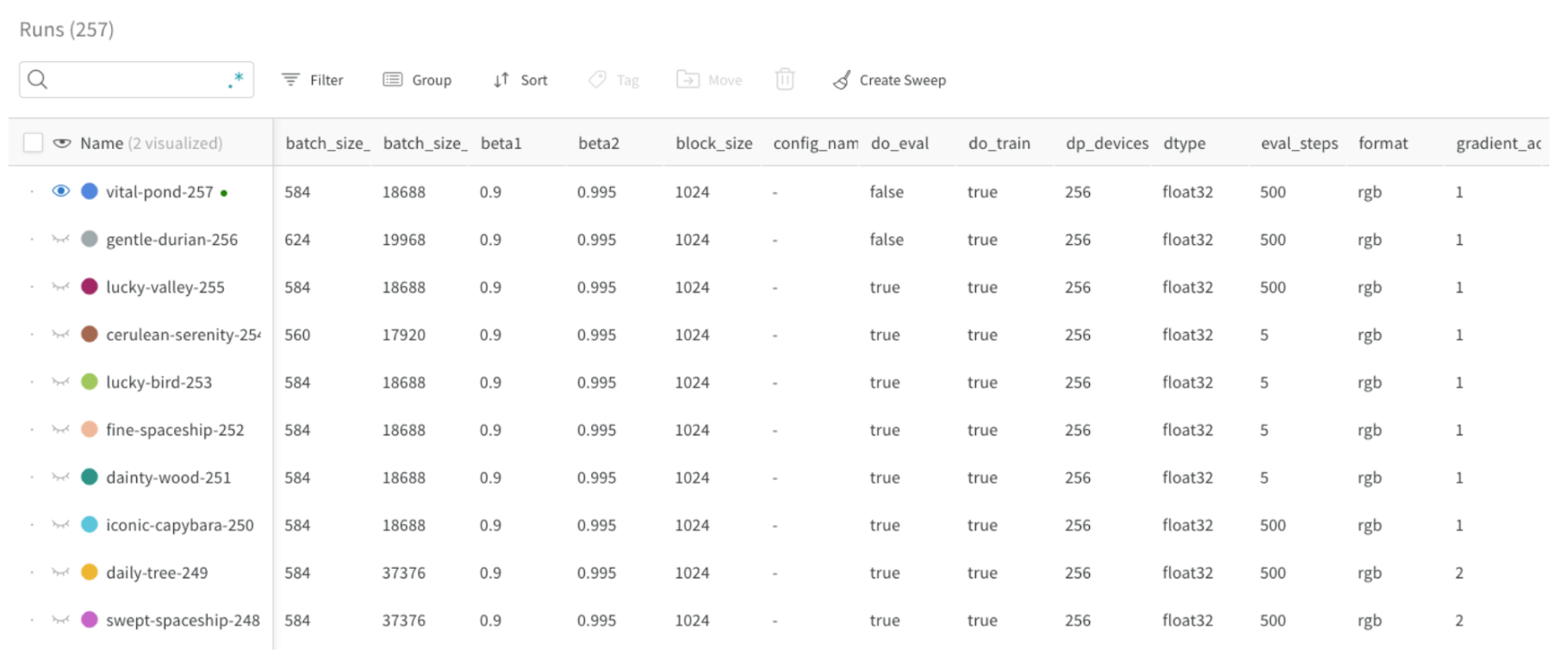
bathch_size) が config パラメータとして定義されており、Runs テーブルの 1 列目に表示されています。これにより、ユーザーはバッチサイズに基づいて runs をフィルタリングおよび比較できます:
代表的な config パラメータの値としては、次のようなものがあります:
- モデル名、バージョン、アーキテクチャのパラメータ、およびハイパーパラメータ。
- データセット名、バージョン、学習用または検証用サンプル数。
- 学習率、バッチサイズ、オプティマイザなどの学習パラメータ。
次のコードスニペットは、config をログする方法を示しています:
config = {"batch_size": 32, ...}
with wandb.init(..., config=config) as run:
...
wandb.Run.config.update メソッドを使って config を更新します。たとえば、モデルをインスタンス化した後に、そのモデルのパラメータを追加したい場合などです。
with wandb.init(...) as run:
model = MyModel(...)
run.config.update({"model_parameters": 3500})
wandb.Run.log() に渡して、W&B にログを記録します。
NUM_EPOCHS = 10
for epoch in range(NUM_EPOCHS):
for input, ground_truth in data:
prediction = model(input)
loss = loss_fn(prediction, ground_truth)
metrics = { "loss": loss }
run.log(metrics)
train/ と val/ がありますが、ユースケースに応じて任意のプレフィックスを使用できます。
これにより、プロジェクトのワークスペース内で、学習用メトリクスと検証用メトリクス、あるいは分けて管理したいその他のメトリクスタイプごとに、別々のセクションが作成されます。
with wandb.init(...) as run:
metrics = {
"train/loss": 0.4,
"train/learning_rate": 0.4,
"val/loss": 0.5,
"val/accuracy": 0.7
}
run.log(metrics)
wandb.Run.log() を参照してください。
同じ学習ステップに対して wandb.Run.log() を複数回呼び出すと、wandb SDK は wandb.Run.log() の呼び出しごとに内部のステップカウンタをインクリメントします。このカウンタは、学習ループ内の学習ステップと一致しない場合があります。
この状況を避けるには、wandb.init を呼び出した直後に一度だけ、run.define_metric を使って x 軸ステップを明示的に定義します。
with wandb.init(...) as run:
run.define_metric("*", step_metric="global_step")
* は、チャートの x 軸としてすべてのメトリクスに global_step を使用することを意味します。特定のメトリクスだけを global_step に対してログしたい場合は、それらを個別に指定できます。
run.define_metric("train/loss", step_metric="global_step")
wandb.Run.log() を呼び出すたびに、メトリクスと step メトリクス、global_step をログに記録します。
for step, (input, ground_truth) in enumerate(data):
...
run.log({"global_step": step, "train/loss": 0.1})
run.log({"global_step": step, "eval/loss": 0.2})
- メトリクスはどのくらいの頻度で記録するべきか?任意にするべきか?
- どのような種類のデータが可視化に役立つか?
- 画像の場合、サンプル予測やセグメンテーションマスクなどをログし、時間経過に伴う変化を確認できます。
- テキストの場合、後から分析できるようにサンプル予測をまとめたテーブルをログできます。
例については、オブジェクトとメディアのログを参照してください。
分散環境に対応しているフレームワークの場合、次のいずれかのワークフローを利用できます。
- メインプロセスからのみログを送信する(推奨)。
- すべてのプロセスからログを送信し、共有の
group 名を使用して run をグループ化する。
詳細については Log Distributed Training Experiments を参照してください。
W&B Artifacts を使用して、モデルとデータセットを追跡し、バージョン管理します。アーティファクトは機械学習用の資産の保存とバージョン管理を提供し、データとモデルの関係を示す系譜(リネージ)を自動的に追跡します。
ライブラリにアーティファクトを組み込む際は、次の点を検討してください:
- モデルのチェックポイントやデータセットをアーティファクトとしてログするかどうか(任意機能にしたい場合など)。
- アーティファクトの入力参照(例:
entity/project/artifact)。
- モデルのチェックポイントやデータセットをログする頻度。たとえば、エポックごと、500 ステップごとなど。
モデルのチェックポイントを W&B にログとして記録します。一般的な方法としては、W&B が生成する一意の run ID をアーティファクト名に含め、そのチェックポイントをアーティファクトとしてログに記録します。
metadata = {"eval/accuracy": 0.8, "train/steps": 800}
artifact = wandb.Artifact(
name=f"model-{run.id}",
metadata=metadata,
type="model"
)
artifact.add_dir("output_model") # モデルの重みが保存されているローカルディレクトリ
aliases = ["best", "epoch_10"]
run.log_artifact(artifact, aliases=aliases)
dataset = wandb.Artifact(name="flowers", type="dataset")
dataset.add_file("flowers.npy")
run.use_artifact(dataset)
run.use_artifact() を使って現在のrunに紐付けます。これにより、そのrunで使用されたデータセットの来歴をW&Bが追跡できるようになります。
すでに W&B にログされたアーティファクトをダウンロードして、学習または推論コードで使用できます。
run コンテキストがある場合は、wandb.Run.use_artifact() を使用して W&B 内のアーティファクトを参照し、その後 wandb.Artifact.download() を呼び出してローカルディレクトリにダウンロードします。
with wandb.init(...) as run:
artifact = run.use_artifact("user/project/artifact:latest")
local_path = artifact.download()
import wandb
artifact = wandb.Api().artifact("user/project/artifact:latest")
local_path = artifact.download()