Embeddings は、オブジェクト(人、画像、投稿、単語など)を数値のリスト(ベクトル と呼ばれることもあります)で表現するために使用されます。機械学習やデータサイエンスのユースケースでは、埋め込みはさまざまなアプリケーションにおいて、さまざまな手法を用いて生成できます。このページでは、読者が埋め込みについての基本的な知識を持ち、W&B 内でそれらを視覚的に分析することに関心があることを前提としています。
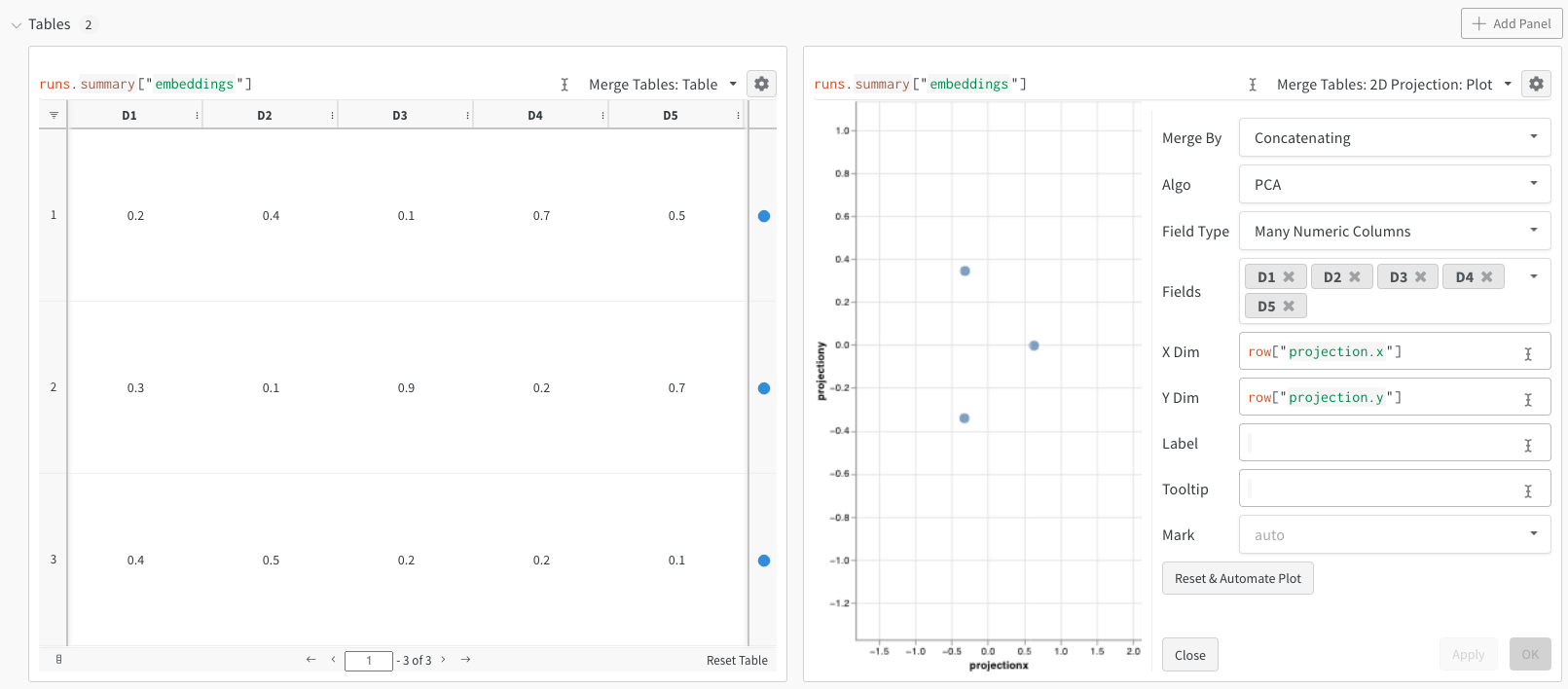
W&B を使用すると、wandb.Table クラスを使って埋め込みをログできます。次の例では、5 次元の埋め込みが 3 つあります。
import wandb
with wandb.init(project="embedding_tutorial") as run:
embeddings = [
# D1 D2 D3 D4 D5
[0.2, 0.4, 0.1, 0.7, 0.5], # embedding 1
[0.3, 0.1, 0.9, 0.2, 0.7], # embedding 2
[0.4, 0.5, 0.2, 0.2, 0.1], # embedding 3
]
run.log(
{"embeddings": wandb.Table(columns=["D1", "D2", "D3", "D4", "D5"], data=embeddings)}
)
run.finish()
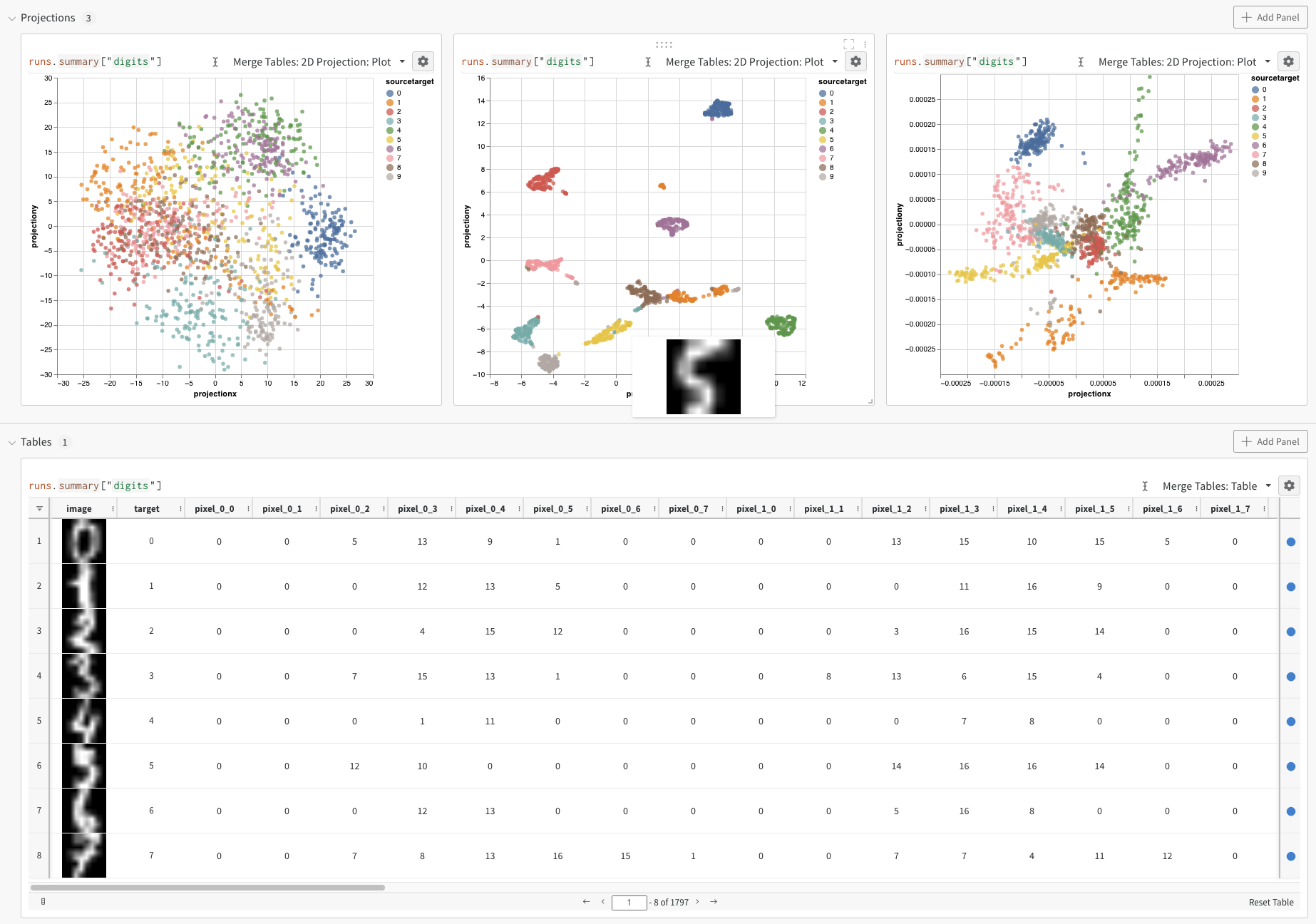
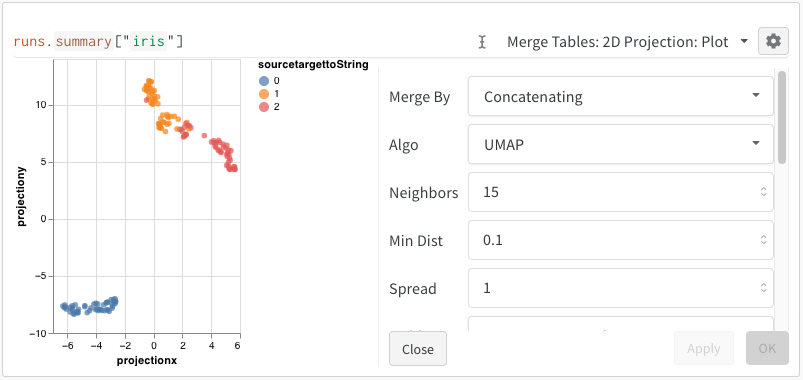
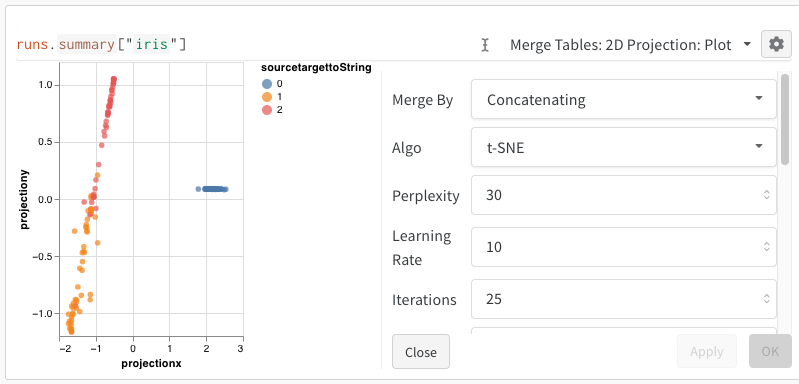
2D Projection を選択すると、埋め込みを 2 次元でプロットできます。スマートデフォルトが自動的に選択されますが、歯車アイコンをクリックして開く設定メニューから簡単に変更できます。この例では、利用可能な 5 つの数値次元をすべて自動的に使用します。
上記の例では埋め込みをロギングするための基本的な仕組みを示しましたが、通常ははるかに多くの次元とサンプルを扱います。ここでは SciKit-Learn から利用できる MNIST Digits データセット(UCI ML hand-written digits datasets)を考えてみましょう。このデータセットには 1797 件のレコードがあり、それぞれ 64 次元の特徴量を持ちます。この問題は 10 クラスの分類タスクです。可視化のために、入力データを画像に変換することもできます。
import wandb
from sklearn.datasets import load_digits
with wandb.init(project="embedding_tutorial") as run:
# データセットを読み込む
ds = load_digits(as_frame=True)
df = ds.data
# "target" 列を作成する
df["target"] = ds.target.astype(str)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
# "image" 列を作成する
df["image"] = df.apply(
lambda row: wandb.Image(row[1:].values.reshape(8, 8) / 16.0), axis=1
)
cols = df.columns.tolist()
df = df[cols[-1:] + cols[:-1]]
run.log({"digits": df})
2D Projection を選択すると、埋め込みの定義、色付け、アルゴリズム(PCA、UMAP、t-SNE)、アルゴリズムのパラメーター、さらにはオーバーレイ(この例では、ポイントにカーソルを合わせると画像を表示)まで設定できます。今回のケースでは、これらはすべて「スマートなデフォルト」になっており、2D Projection をワンクリックするだけで、ほぼ同じものが表示されるはずです。(この埋め込みチュートリアルの例を操作してみてください)。
埋め込みはさまざまな形式でログできます:
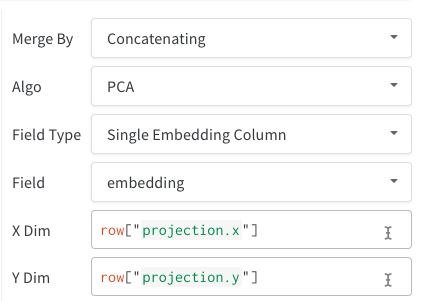
- 単一埋め込みカラム: 多くの場合、データはすでに「行列」形式になっています。この場合、セル値のデータ型を
list[int]、list[float]、または np.ndarray とする単一の埋め込みカラムを作成できます。
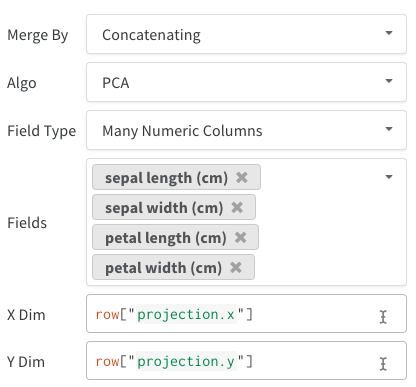
- 複数の数値カラム: 上記 2 つの例ではこの方法を使用しており、各次元に対応するカラムを作成します。セルとして受け付けるのは、現在のところ Python の
int または float です。
さらに、他のすべてのテーブルと同様に、テーブルの構築方法には多くのオプションがあります:
wandb.Table(dataframe=df) を使って dataframe から直接 作成するwandb.Table(data=[...], columns=[...]) を使って データのリストから直接 作成する- テーブルを 1 行ずつインクリメンタルに構築する(コード内にループがある場合に便利です)。
table.add_data(...) を使ってテーブルに行を追加します
- テーブルに 埋め込みカラムを追加する(埋め込み形式の予測値リストがある場合に便利です):
table.add_col("col_name", ...)
- 計算カラムを追加する(テーブル上の各行に適用したい関数やモデルがある場合に便利です):
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
2D Projection を選択した後、歯車アイコンをクリックしてレンダリング設定を編集できます。上記のように目的の列を選択できるほか、関心のあるアルゴリズム(および希望するパラメータ)も選択できます。以下に、UMAP と t-SNE の各パラメータを示します。
Note: 現在、3 つすべてのアルゴリズムで、行を 1000 行・次元を 50 次元のランダムなサブセットにダウンサンプリングしています。