- Suivre un seul processus : suivez un processus de rang 0 (également appelé « leader » ou « coordinateur ») avec W&B. Il s’agit d’une solution courante pour consigner des expériences d’entraînement distribué avec la classe PyTorch Distributed Data Parallel (DDP).
- Suivre plusieurs processus : pour plusieurs processus, vous pouvez soit :
- Suivre chaque processus séparément en utilisant un run par processus. Vous pouvez aussi, si vous le souhaitez, les regrouper dans W&B App UI.
- Suivre tous les processus dans un seul run.
Suivre un seul processus
wandb.init() et enregistrez les expériences (wandb.log) dans ce run.
L’exemple de script Python (log-ddp.py) suivant montre une façon de suivre des métriques sur deux GPU d’une même machine à l’aide de PyTorch DDP. PyTorch DDP (DistributedDataParallel dans torch.nn) est une bibliothèque populaire pour l’entraînement distribué. Les principes de base s’appliquent à toute configuration d’entraînement distribué, mais l’implémentation peut varier.
Le script Python :
- Démarre plusieurs processus avec
torch.distributed.launch. - Vérifie le rang avec l’argument de ligne de commande
--local_rank. - Si le rang est défini sur 0, configure conditionnellement la journalisation avec
wandbdans la fonctiontrain().
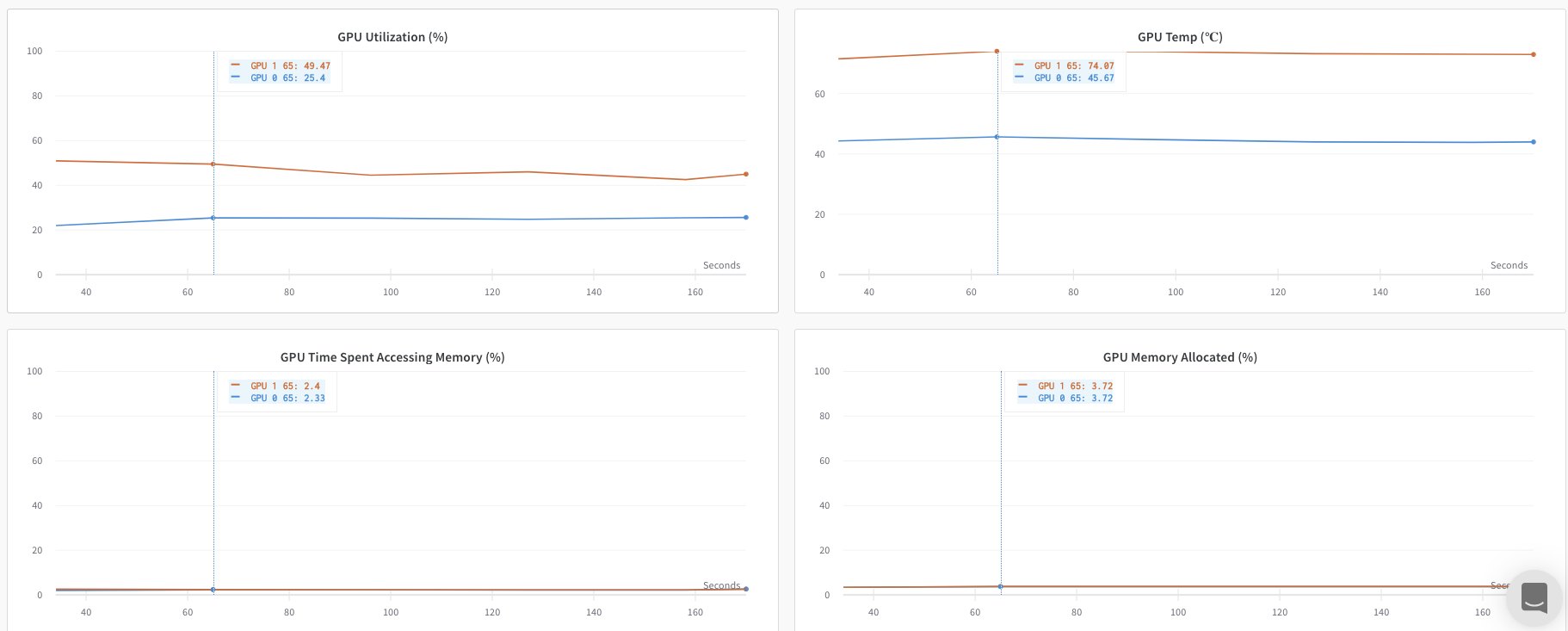
Suivre plusieurs processus
- Suivre chaque processus séparément en créant un run pour chaque processus.
- Suivre tous les processus dans un seul run.
Suivre chaque processus séparément
wandb.Run.finish() à la fin de l’entraînement pour indiquer que le run est terminé, afin que tous les processus se ferment correctement.
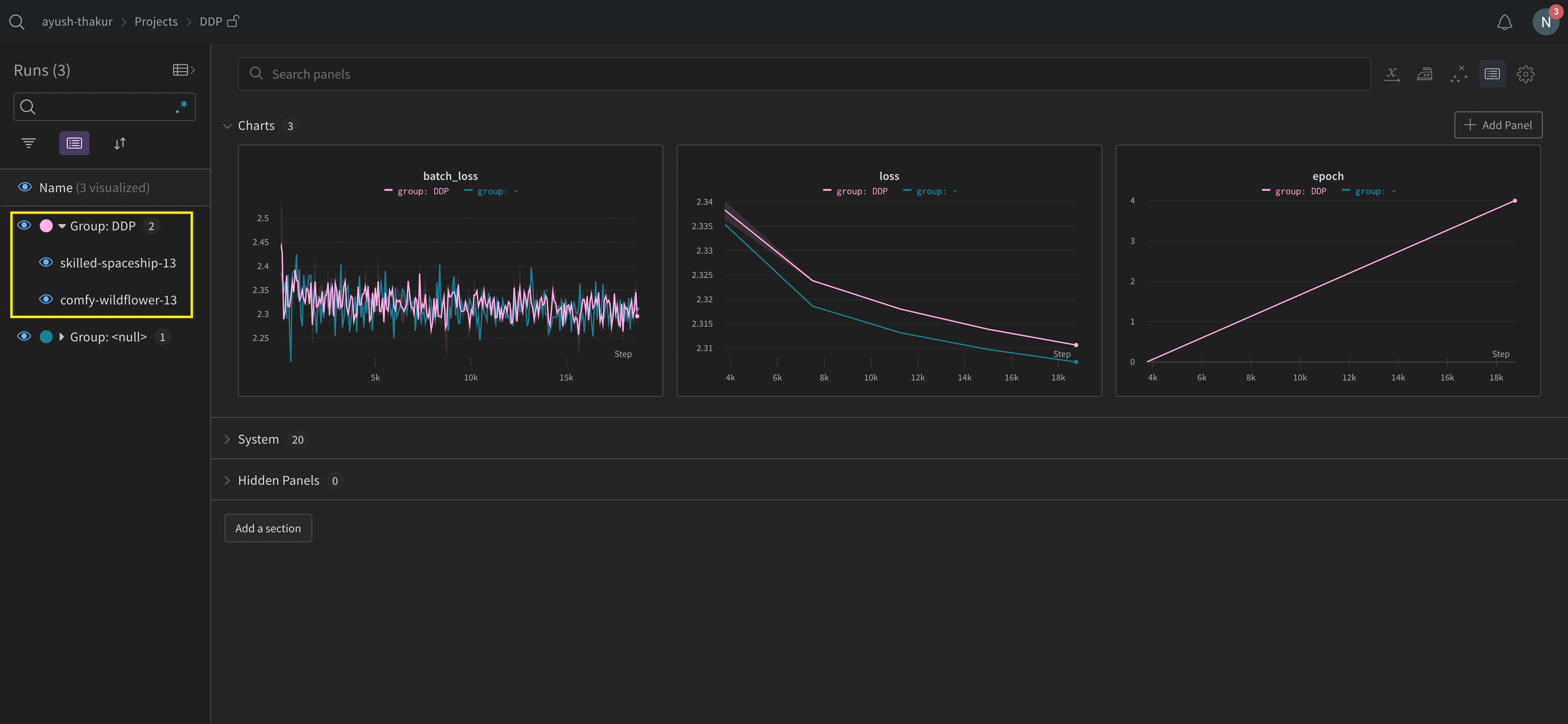
Il peut être difficile de suivre les runs dans plusieurs expériences. Pour y remédier, fournissez une valeur au paramètre group lorsque vous initialisez W&B (wandb.init(group='group-name')) afin d’identifier à quelle expérience appartient chaque run. Pour plus d’informations sur le suivi des Runs W&B d’entraînement et d’évaluation dans les expériences, voir Group Runs.
Utilisez cette approche si vous souhaitez suivre les métriques de chaque processus individuellement. Les exemples typiques incluent les données et les prédictions sur chaque nœud (pour déboguer la distribution des données), ainsi que les métriques sur des lots individuels en dehors du nœud principal. Cette approche n’est pas nécessaire pour obtenir les métriques système de tous les nœuds ni les statistiques récapitulatives disponibles sur le nœud principal.
group lorsque vous initialisez W&B :
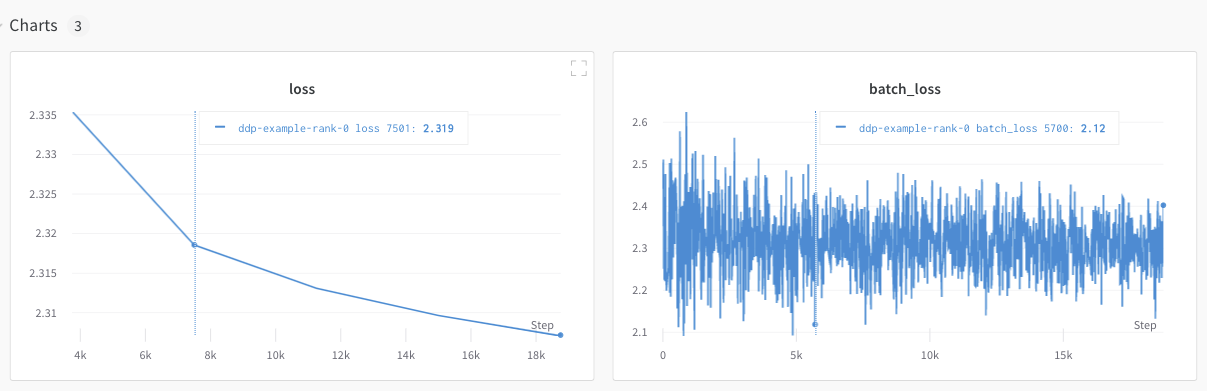
Organiser les runs distribués
job_type lors de l’initialisation de W&B (wandb.init(job_type='type-name')) afin de classer vos nœuds selon leur rôle. Par exemple, vous pouvez avoir un nœud coordinateur principal et plusieurs nœuds workers chargés du reporting. Vous pouvez définir job_type sur main pour le nœud coordinateur principal et sur worker pour les nœuds workers chargés du reporting :
job_type pour vos nœuds, vous pouvez créer des vues enregistrées dans votre Workspace pour organiser vos runs. Cliquez sur le menu d’action … en haut à droite, puis sur Enregistrer comme nouvelle vue.
Par exemple, vous pourriez créer les vues enregistrées suivantes :
- Vue par défaut : Masquer les nœuds worker pour réduire le bruit
-
Cliquez sur Filtre, puis définissez Job Type sur
worker. - Affiche uniquement vos nœuds de reporting
-
Vue de débogage : Se concentrer sur les nœuds worker pour le dépannage
- Cliquez sur Filtre, puis définissez Job Type sur
==workeret State surINcrashed. - Affiche uniquement les nœuds worker qui ont planté ou sont dans des états d’erreur
- Cliquez sur Filtre, puis définissez Job Type sur
-
Vue de tous les nœuds : Tout voir en un seul endroit
- Aucun filtre
- Utile pour une surveillance complète
-
Cliquez sur Filtre, puis définissez Job Type sur
Suivre tous les processus dans un même run
PrérequisPour suivre plusieurs processus dans un même run, vous devez disposer de :
-
la version
v0.19.9ou ultérieure du W&B Python SDK. - de W&B Server v0.68 ou ultérieure.
wandb.init(). Passez un objet wandb.Settings au paramètre settings (wandb.init(settings=wandb.Settings()) avec les éléments suivants :
- Le paramètre
modedéfini sur"shared"pour activer le mode partagé. - Un libellé unique pour
x_label. La valeur spécifiée pourx_labelpermet d’identifier de quel nœud proviennent les données dans les journaux et les métriques système de la W&B App UI. S’il n’est pas spécifié, W&B crée un libellé à partir du nom d’hôte et d’un hachage aléatoire. - Définissez le paramètre
x_primarysurTruepour indiquer qu’il s’agit du nœud principal. - Vous pouvez éventuellement fournir une liste d’index GPU ([0,1,2]) à
x_stats_gpu_device_idspour préciser les GPU dont W&B doit suivre les métriques. Si vous ne fournissez pas de liste, W&B suit les métriques de tous les GPU de la machine.
x_primary=True permet de distinguer un nœud principal des nœuds workers. Les nœuds principaux sont les seuls à téléverser les fichiers partagés entre les nœuds, comme les fichiers de configuration, la télémétrie, etc. Les nœuds workers ne téléversent pas ces fichiers.wandb.init() et fournissez les éléments suivants :
- Un objet
wandb.Settingsau paramètresettings(wandb.init(settings=wandb.Settings()) avec :- Le paramètre
modedéfini sur"shared"pour activer le mode partagé. - Un libellé unique pour
x_label. La valeur spécifiée pourx_labelpermet d’identifier de quel nœud proviennent les données dans les journaux et les métriques système de la W&B App UI. S’il n’est pas spécifié, W&B crée un libellé à partir du nom d’hôte et d’un hachage aléatoire. - Définissez le paramètre
x_primarysurFalsepour indiquer qu’il s’agit d’un nœud worker.
- Le paramètre
- Passez l’ID du run du nœud principal au paramètre
id. - Définissez éventuellement
x_update_finish_statesurFalse. Cela empêche les nœuds non principaux de mettre prématurément à jour l’état du run versfinished, afin de garantir que l’état du run reste cohérent et géré par le nœud principal.
- Utilisez la même entité et le même projet pour tous les nœuds. Cela permet de s’assurer que le bon ID de run est trouvé.
- Vous pouvez envisager de définir une variable d’environnement sur chaque nœud worker pour définir l’ID du run du nœud principal.
Voir le Reports Distributed Training with Shared Mode pour un exemple de bout en bout montrant comment entraîner un modèle sur un cluster Kubernetes multi-nœud et multi-GPU dans GKE.
- Accédez au projet qui contient le run.
- Cliquez sur l’onglet Runs dans la barre latérale du projet.
- Cliquez sur le run que vous souhaitez afficher.
- Cliquez sur l’onglet Logs dans la barre latérale du projet.
x_label dans la barre de recherche de l’UI située en haut de la page des journaux de console. Par exemple, l’image suivante montre les options disponibles pour filtrer le journal de console si les valeurs rank0, rank1, rank2, rank3, rank4, rank5 et rank6 sont fournies à x_label.
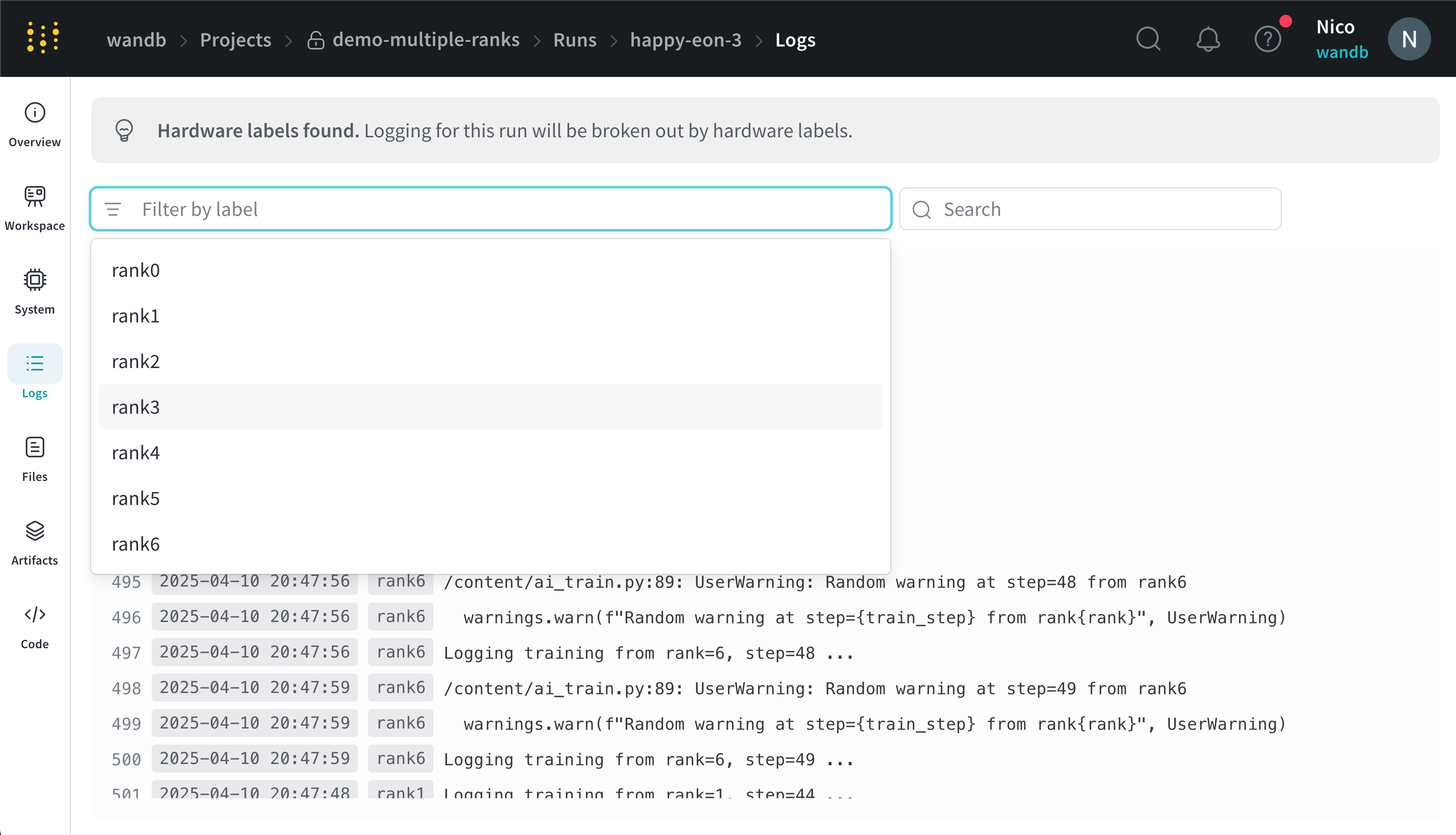
rank_0, rank_1, rank_2) que vous spécifiez dans le paramètre x_label.
Exemples de cas d’utilisation
Processus enfant
wandb.setup() dans votre fonction principale si vous lancez un run dans un processus enfant :
Dépannage
- Blocage au début de l’entraînement - Un processus
wandbpeut se bloquer si le multiprocessing dewandbinterfère avec celui de l’entraînement distribué. - Blocage à la fin de l’entraînement - Une tâche d’entraînement peut se bloquer si le processus
wandbne sait pas quand il doit s’arrêter. Appelez l’APIwandb.Run.finish()à la fin de votre script Python pour indiquer à W&B que le run est terminé. L’APIwandb.Run.finish()terminera l’envoi des données et entraînera l’arrêt de W&B. W&B recommande d’utiliser la commandewandb servicepour améliorer la fiabilité de vos jobs distribués. Ces deux problèmes d’entraînement surviennent fréquemment dans les versions du SDK W&B oùwandb servicen’est pas disponible.
Activer W&B Service
SDK W&B 0.13.0 et versions ultérieures
0.13.0 du SDK W&B.
W&B SDK 0.12.5 et versions ultérieures
wandb.require et transmettez la chaîne "service" dans votre fonction principale :
WANDB_START_METHOD sur "thread" pour utiliser le multithreading à la place.