Pour en savoir plus, consultez la référence des types de données.
Pour plus de détails, consultez un rapport de démonstration sur la visualisation des prédictions d’un modèle ou regardez un guide pas à pas en vidéo.
Prérequis
Images

Nous vous recommandons de journaliser moins de 50 images par étape afin d’éviter que la journalisation ne devienne un goulot d’étranglement pendant l’entraînement et que le chargement des images ne ralentisse la consultation des résultats.
- Journaliser des tableaux comme images
- Journaliser des images PIL
- Journaliser des images depuis des fichiers
Fournissez directement les tableaux lors de la création manuelle d’images, par exemple avec Nous supposons que l’image est en niveaux de gris si la dernière dimension vaut 1, en RGB si elle vaut 3, et en RGBA si elle vaut 4. Si le tableau contient des nombres à virgule flottante, nous les convertissons en entiers entre
make_grid de torchvision.Les tableaux sont convertis en PNG à l’aide de Pillow.0 et 255. Si vous souhaitez normaliser vos images autrement, vous pouvez spécifier manuellement le mode ou simplement fournir une PIL.Image, comme décrit dans l’onglet « Journaliser des images PIL » de ce panneau.Superpositions d’images
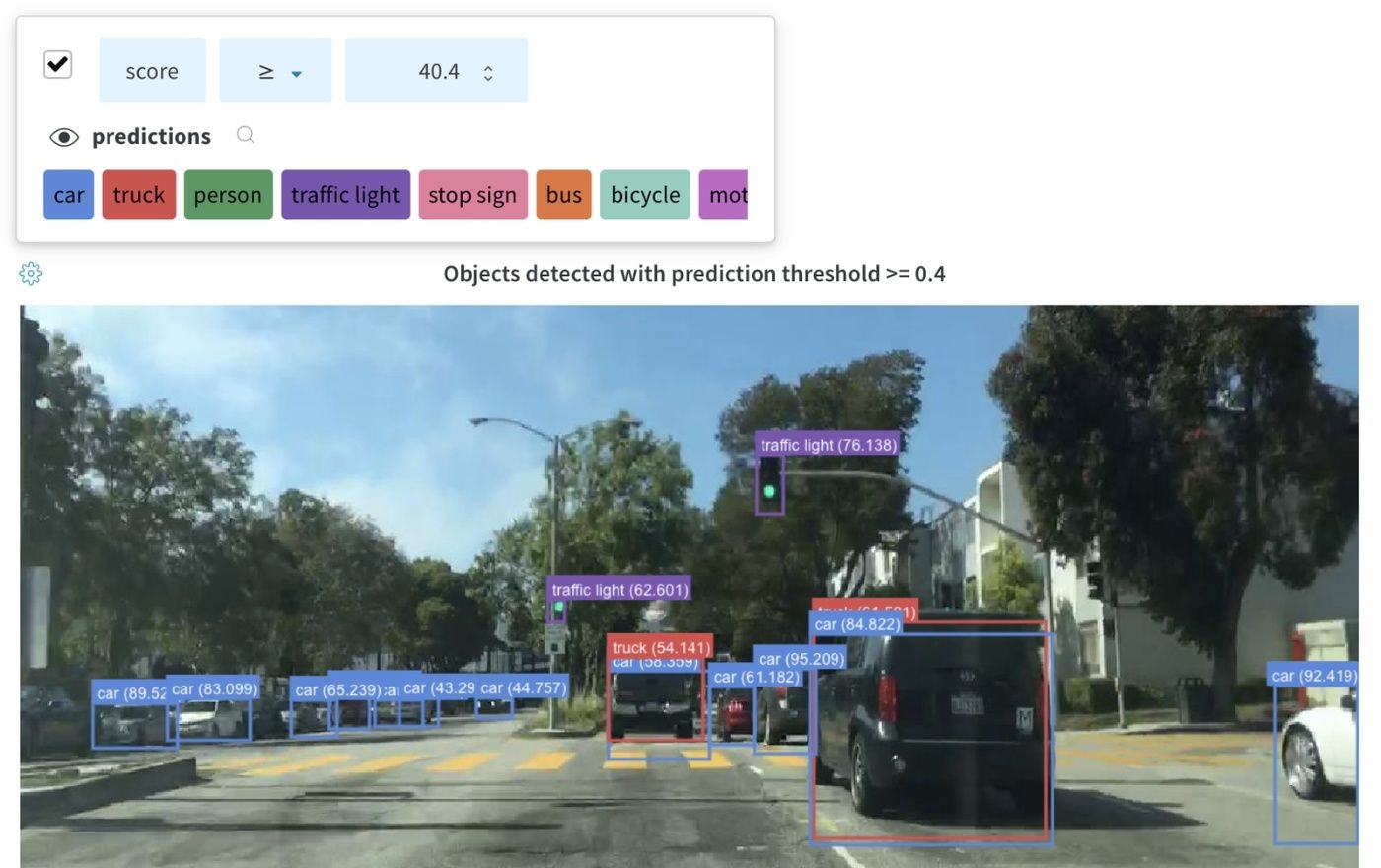
- Masques de segmentation
- Boîtes englobantes
Consignez des masques de segmentation sémantique et interagissez avec eux (en modifiant l’opacité, en visualisant les changements au fil du temps, etc.) via l’interface W&B.
masks de wandb.Image :- l’une des deux clés représentant le masque de l’image :
"mask_data": un tableau NumPy 2D contenant une étiquette de classe entière pour chaque pixel"path": (string) le chemin vers un fichier de masque d’image enregistré
"class_labels": (facultatif) un dictionnaire associant les étiquettes de classe entières du masque de l’image à des noms de classe lisibles
run.log()).- Si différentes étapes fournissent des valeurs différentes pour une même clé de masque, seule la valeur la plus récente de cette clé est appliquée à l’image.
- Si différentes étapes fournissent des clés de masque différentes, toutes les valeurs de chaque clé sont affichées, mais seules celles définies dans l’étape actuellement affichée sont appliquées à l’image. Activer ou désactiver la visibilité des masques non définis dans cette étape ne modifie pas l’image.
Superpositions d’images dans Tables
- Masques de segmentation
- Boîtes englobantes
wandb.Image pour chaque ligne du tableau.Un exemple est fourni dans l’extrait de code ci-dessous :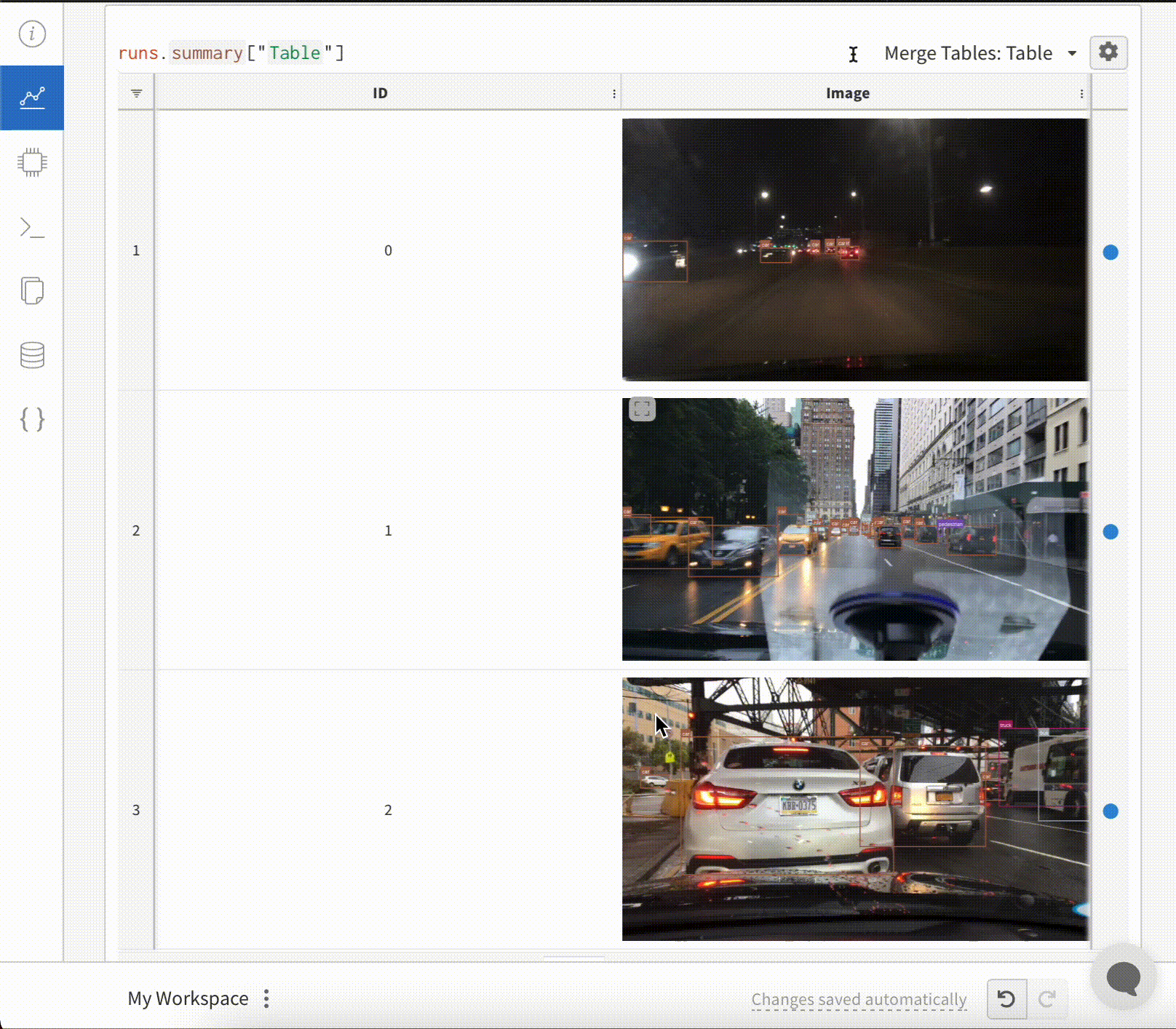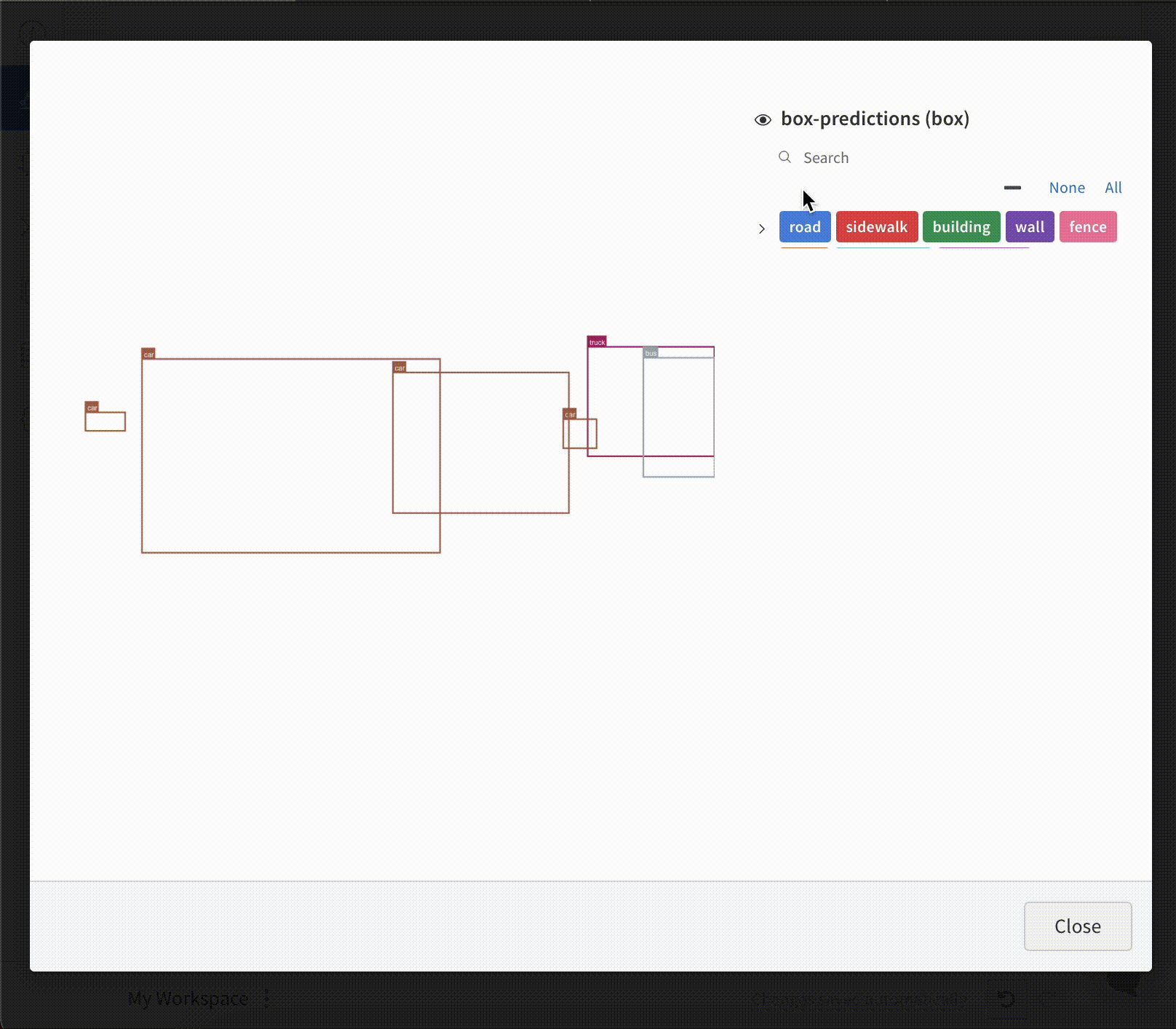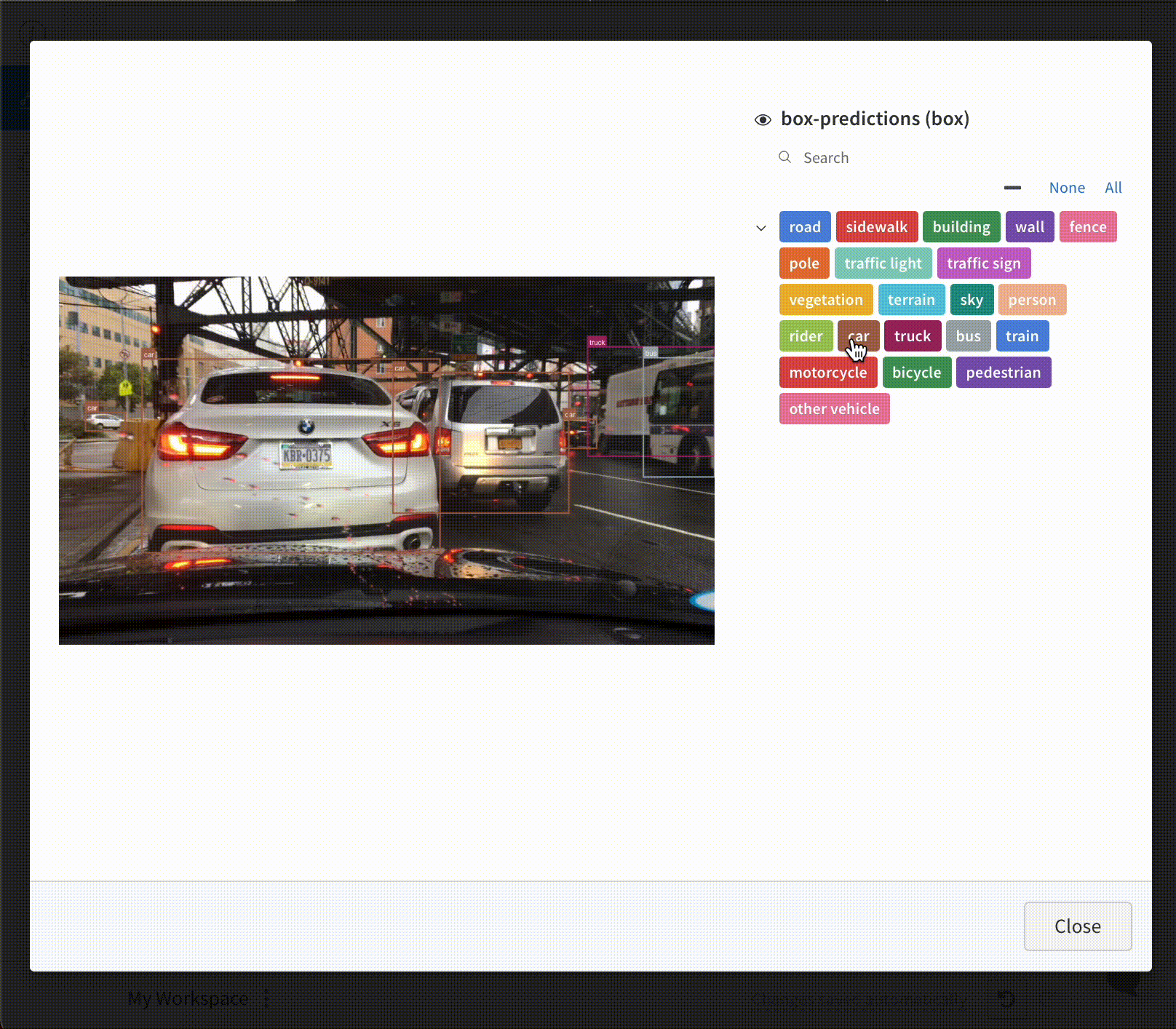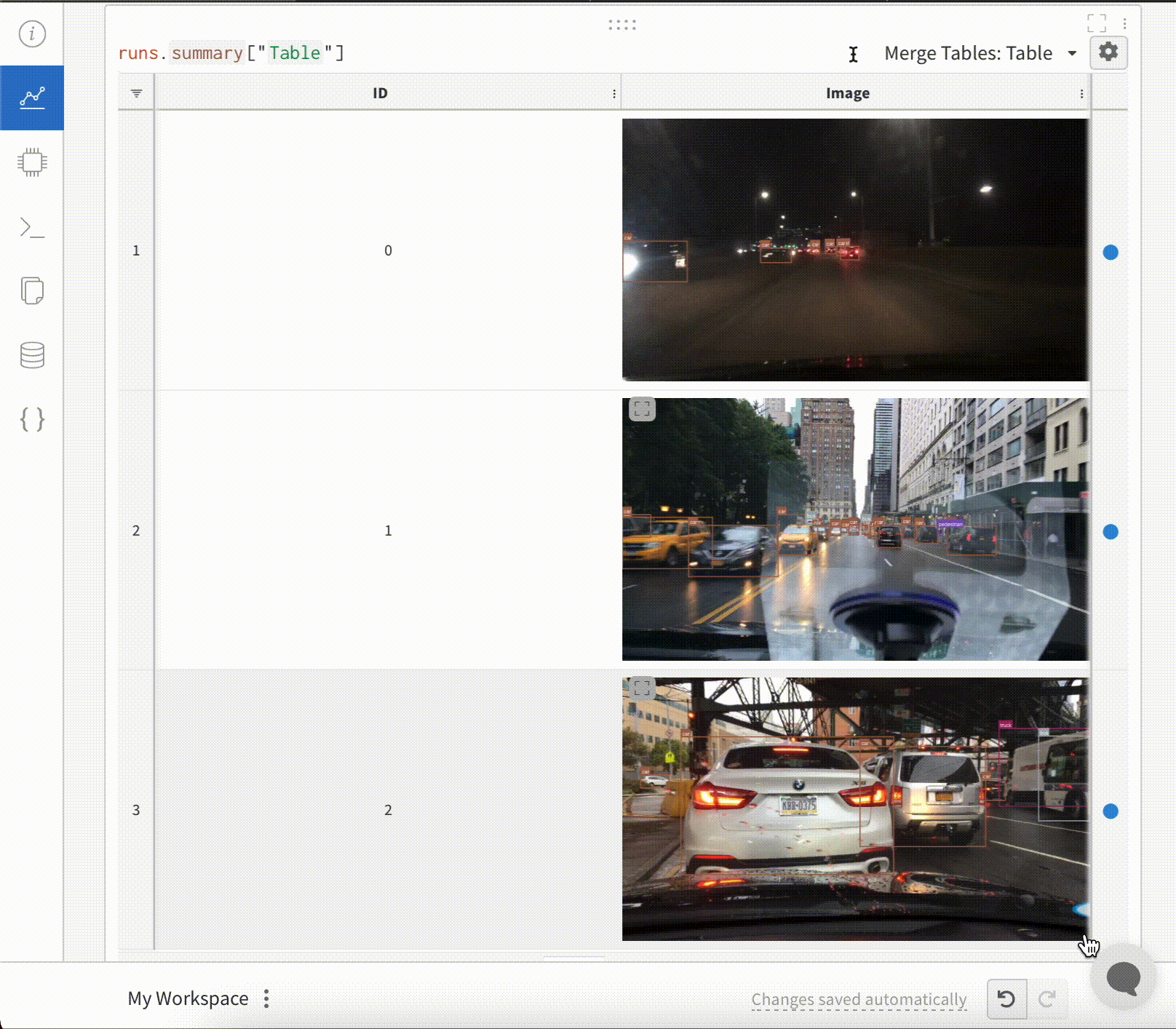
Histogrammes
- Journalisation basique des histogrammes
- Journalisation flexible des histogrammes
Si une séquence de nombres, comme une liste, un tableau ou un tenseur, est fournie comme premier argument, nous créons automatiquement l’histogramme en appelant 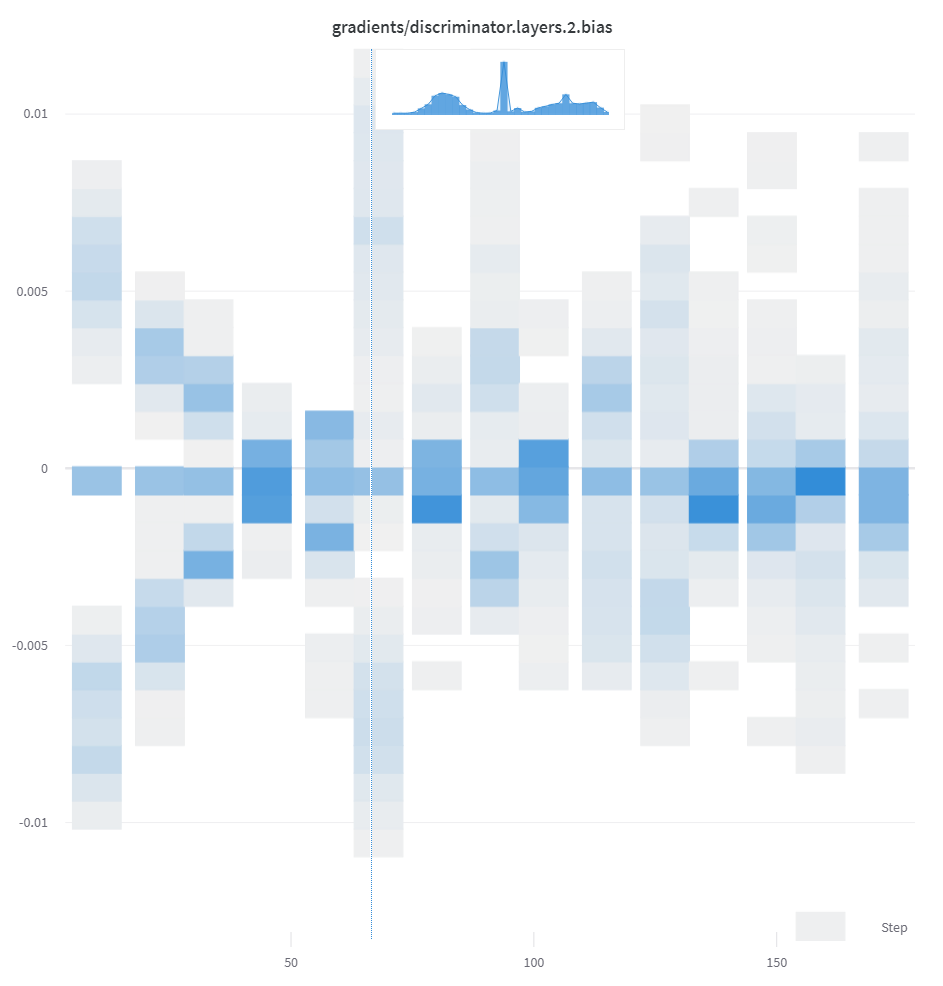
np.histogram. Tous les tableaux/tenseurs sont aplatis. Vous pouvez utiliser l’argument mot-clé facultatif num_bins pour remplacer la valeur par défaut de 64 bins. Le nombre maximal de bins pris en charge est de 512.Dans l’interface utilisateur, les histogrammes sont tracés avec l’étape d’entraînement sur l’axe des x, la valeur de la métrique sur l’axe des y, et le nombre représenté par la couleur, afin de faciliter la comparaison des histogrammes enregistrés tout au long de l’entraînement. Voir l’onglet « Histogrammes dans le summary » de ce panneau pour plus de détails sur la journalisation d’histogrammes ponctuels.Visualisations 3D
L’UI de W&B tronque les données au-delà de 300 000 points.
Formats de tableaux NumPy
[[x, y, z], ...]nx3[[x, y, z, c], ...]nx4| c est une catégoriedans l’intervalle[1, 14](utile pour la segmentation)[[x, y, z, r, g, b], ...]nx6 | r,g,bsont des valeurs dans l’intervalle[0,255]pour les canaux de couleur rouge, vert et bleu.
Objet Python
from_point_cloud.
pointsest un tableau NumPy contenant les coordonnées et les couleurs des points à afficher, en utilisant les mêmes formats que ceux du rendu simple de nuage de points présenté ci-dessus.boxesest un tableau NumPy de dictionnaires Python avec les attributs suivants :corners- une liste de huit sommetslabel- une chaîne représentant l’étiquette à afficher sur la boîte (facultatif)color- des valeurs RGB représentant la couleur de la boîtescore- une valeur numérique affichée sur la boîte englobante, qui peut être utilisée pour filtrer les boîtes englobantes affichées (par exemple, pour afficher uniquement les boîtes englobantes oùscore>0.75). (facultatif)
typeest une chaîne représentant le type de scène à afficher. Actuellement, la seule valeur prise en charge estlidar/beta
Fichiers de nuages de points
from_file pour charger un fichier JSON contenant des données de nuages de points.
Tableaux NumPy
numpy avec la méthode from_numpy pour définir un nuage de points.
pdb, pqr, mmcif, mcif, cif, sdf, sd, gro, mol2 ou mmtf.
W&B prend également en charge la journalisation de données moléculaires à partir de chaînes SMILES, de fichiers mol de rdkit et d’objets rdkit.Chem.rdchem.Mol.
Image PNG
wandb.Image convertit par défaut les tableaux numpy ou les instances de PILImage en fichiers PNG.
Vidéo
wandb.Video :
Vue 2D d’une molécule
wandb.Image et de rdkit :
Autres médias
Audio
audio-file.
Vidéo
ffmpeg et la bibliothèque Python moviepy sont requis lors du passage d’objets numpy). Les formats pris en charge sont "gif", "mp4", "webm" et "ogg". Si vous passez une chaîne à wandb.Video, nous vérifions que le fichier existe et qu’il est dans un format pris en charge avant de le téléverser sur wandb. Le passage d’un objet BytesIO crée un fichier temporaire avec le format spécifié comme extension.
Sur les pages W&B Run et projet, vous verrez vos vidéos dans la section Média.
Pour plus d’informations sur l’utilisation, voir video-file.
Texte
wandb.Table pour journaliser du texte dans des tableaux afin de l’afficher dans l’UI. Par défaut, les en-têtes de colonne sont ["Input", "Output", "Expected"]. Pour des performances optimales de l’UI, le nombre maximal de lignes par défaut est fixé à 10 000. Cependant, vous pouvez explicitement redéfinir ce maximum avec wandb.Table.MAX_ROWS = {DESIRED_MAX}.
DataFrame pandas.
string.
HTML
inject=False.
html-file.