Découvrez quand et comment utiliser W&B pour suivre, partager et gérer les artifacts de modèle dans vos flux de travail de machine learning. Cette page explique comment enregistrer des expériences, générer des rapports et accéder aux données enregistrées à l’aide de l’API W&B appropriée pour chaque tâche.
Ce tutoriel utilise les éléments suivants :
- W&B Python SDK (
wandb.sdk) : pour enregistrer et surveiller les expériences pendant l’entraînement.
- API publique W&B (
wandb.apis.public) : pour interroger et analyser les données d’expérience enregistrées.
- API W&B Reports and Workspaces (
wandb.wandb-workspaces) : pour créer un rapport afin de résumer les résultats.
Inscrivez-vous et créez une clé API
Installer et importer des packages
TEAM_ENTITY = "<Team_Entity>" # Remplacez par votre entité d'équipe
PROJECT = "my-awesome-project"
wandb.sdk) pour interagir avec W&B pendant l’entraînement. Consignez la perte à l’aide de wandb.Run.log(), puis enregistrez le modèle entraîné en tant qu’artifact avec wandb.Artifact, avant d’ajouter le fichier du modèle avec Artifact.add_file.
import random # Pour simuler des données
def model(training_data: int) -> int:
"""Simulation de modèle à des fins de démonstration."""
return training_data * 2 + random.randint(-1, 1)
# Simuler les poids et le bruit
weights = random.random() # Initialiser des poids aléatoires
noise = random.random() / 5 # Petit bruit aléatoire pour simuler le bruit
# Hyperparamètres et configuration
config = {
"epochs": 10, # Nombre d'époques d'entraînement
"learning_rate": 0.01, # Taux d'apprentissage pour l'optimiseur
}
# Utiliser le gestionnaire de contexte pour initialiser et fermer les runs W&B
with wandb.init(project=PROJECT, entity=TEAM_ENTITY, config=config) as run:
# Simuler la boucle d'entraînement
for epoch in range(config["epochs"]):
xb = weights + noise # Données d'entraînement en entrée simulées
yb = weights + noise * 2 # Sortie cible simulée (double du bruit en entrée)
y_pred = model(xb) # Prédiction du modèle
loss = (yb - y_pred) ** 2 # Perte erreur quadratique moyenne
print(f"epoch={epoch}, loss={loss}")
# Enregistrer l'époque et la perte dans W&B
run.log({
"epoch": epoch,
"loss": loss,
})
# Nom unique pour l'artifact du modèle,
model_artifact_name = f"model-demo"
# Chemin local pour enregistrer le fichier de modèle simulé
PATH = "model.txt"
# Enregistrer le modèle localement
with open(PATH, "w") as f:
f.write(str(weights)) # Enregistrement des poids du modèle dans un fichier
# Créer un objet artifact
# Ajouter le modèle enregistré localement à l'objet artifact
artifact = wandb.Artifact(name=model_artifact_name, type="model", description="My trained model")
artifact.add_file(local_path=PATH)
artifact.save()
- Utilisez
wandb.Run.log() pour consigner des métriques pendant l’entraînement.
- Utilisez
wandb.Artifact pour enregistrer des modèles (jeux de données, etc.) en tant qu’artifact dans votre projet W&B.
Maintenant que vous avez entraîné un modèle et l’avez enregistré en tant qu’artifact, vous pouvez le publier dans un registre de W&B. Utilisez wandb.Run.use_artifact() pour récupérer l’artifact de votre projet et le préparer à être publié dans le registre de modèles. wandb.Run.use_artifact() remplit deux fonctions clés :
- Récupérer l’objet artifact depuis votre projet.
- Marquer l’artifact comme entrée du run, ce qui garantit la reproductibilité et la traçabilité. Voir Créer et afficher la carte de traçabilité pour plus de détails.
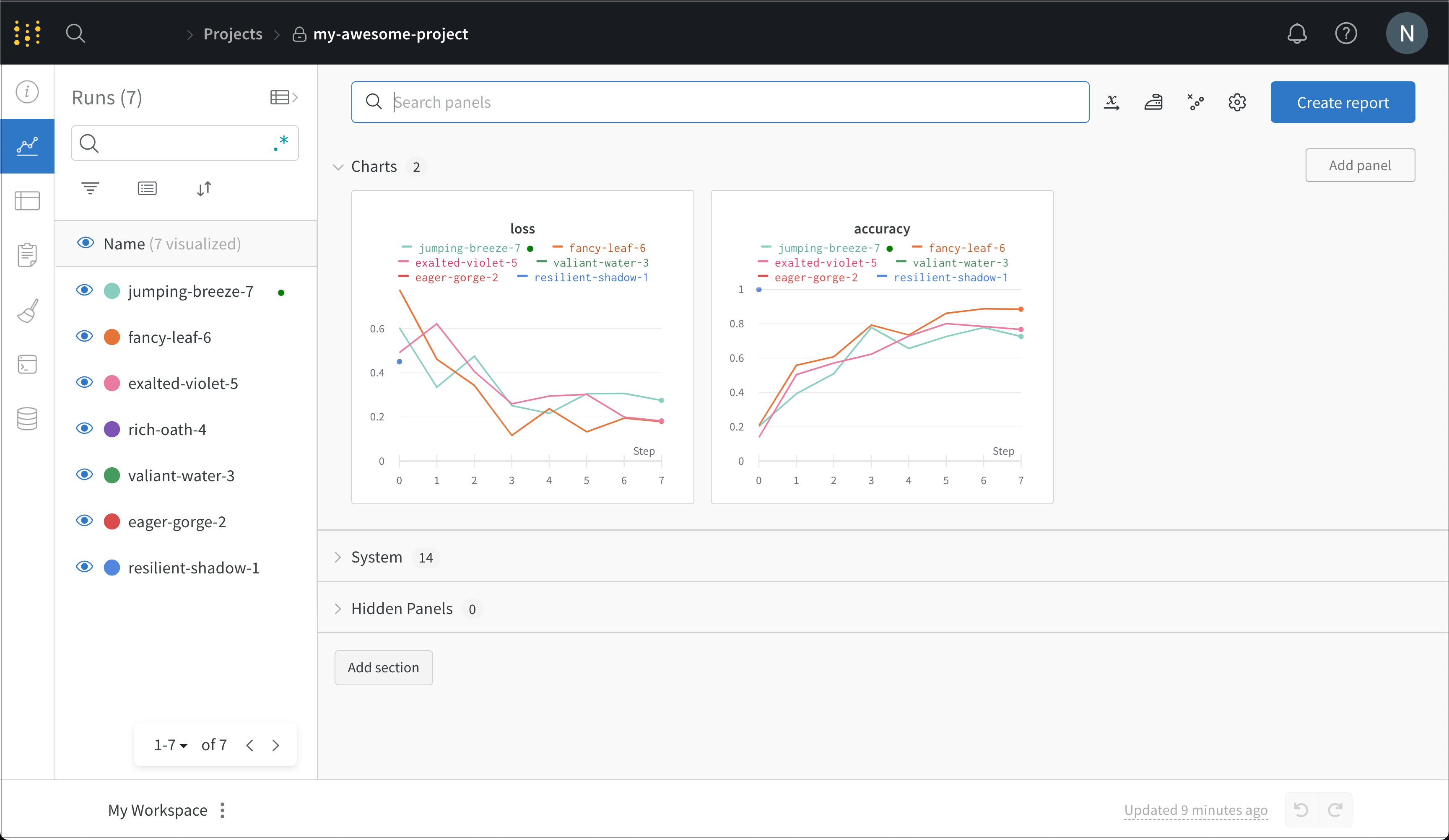
Voir les données d’entraînement dans le tableau de bord
my-awesome-project (ou le nom de projet que vous avez utilisé plus haut). Cliquez dessus pour accéder au Workspace de votre projet.
Vous pouvez ensuite voir les détails de chaque run que vous avez effectué. Dans cette capture d’écran, le code a été relancé plusieurs fois, ce qui a généré plusieurs runs, chacun portant un nom généré aléatoirement.
Publier le modèle dans le registre W&B
wandb.Run.link_artifact(). Le code suivant associe l’artifact à un registre, ce qui le rend accessible à votre équipe.
# Le nom de l'artifact spécifie la version exacte de l'artifact dans le projet de notre équipe
artifact_name = f'{TEAM_ENTITY}/{PROJECT}/{model_artifact_name}:v0'
print("Artifact name: ", artifact_name)
REGISTRY_NAME = "Model" # Nom du registre dans W&B
COLLECTION_NAME = "DemoModels" # Nom de la collection dans le registre
# Créer un chemin cible pour notre artifact dans le registre
target_path = f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}"
print("Target path: ", target_path)
with wandb.init(entity=TEAM_ENTITY, project=PROJECT) as run:
model_artifact = run.use_artifact(artifact_or_name=artifact_name, type="model")
run.link_artifact(artifact=model_artifact, target_path=target_path)
wandb.Run.link_artifact(), l’artifact de modèle se trouvera dans la collection DemoModels de votre registre. Vous pouvez ensuite consulter des informations telles que l’historique des versions, la carte de traçabilité et d’autres métadonnées.
Pour en savoir plus sur la façon de lier des artifacts à un registre, consultez Lier des artifacts à un registre.
Récupérer un artifact de modèle du registre pour l’inférence
wandb.Run.use_artifact() afin de récupérer l’artifact publié dans le registre. Cette méthode renvoie un objet artifact, que vous pouvez ensuite télécharger dans un fichier local à l’aide de wandb.Artifact.download().
REGISTRY_NAME = "Model" # Nom du registre dans W&B
COLLECTION_NAME = "DemoModels" # Nom de la collection dans le registre
VERSION = 0 # Version de l'artifact à récupérer
model_artifact_name = f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"
print(f"Nom de l'artifact modèle : {model_artifact_name}")
with wandb.init(entity=TEAM_ENTITY, project=PROJECT) as run:
registry_model = run.use_artifact(artifact_or_name=model_artifact_name)
local_model_path = registry_model.download()
Partagez vos résultats avec un rapport
L’API W&B Report and Workspace est en préversion publique.
pip install wandb wandb-workspaces -qqq
import wandb_workspaces.reports.v2 as wr
experiment_summary = """This is a summary of the experiment conducted to train a simple model using W&B."""
dataset_info = """The dataset used for training consists of synthetic data generated by a simple model."""
model_info = """The model is a simple linear regression model that predicts output based on input data with some noise."""
report = wr.Report(
project=PROJECT,
entity=TEAM_ENTITY,
title="My Awesome Model Training Report",
description=experiment_summary,
blocks= [
wr.TableOfContents(),
wr.H2("Experiment Summary"),
wr.MarkdownBlock(text=experiment_summary),
wr.H2("Dataset Information"),
wr.MarkdownBlock(text=dataset_info),
wr.H2("Model Information"),
wr.MarkdownBlock(text = model_info),
wr.PanelGrid(
panels=[
wr.LinePlot(title="Train Loss", x="Step", y=["loss"], title_x="Step", title_y="Loss")
],
),
]
)
# Sauvegarder le rapport dans W&B
report.save()
import wandb
# Initialiser l'API wandb
api = wandb.Api()
# Trouver toutes les versions d'artifact contenant la chaîne `model` et
# ayant soit le tag `text-classification`, soit un alias `latest`
registry_filters = {
"name": {"$regex": "model"}
}
# Utiliser l'opérateur logique $or pour filtrer les versions d'artifact
version_filters = {
"$or": [
{"tag": "text-classification"},
{"alias": "latest"}
]
}
# Renvoie un itérable de toutes les versions d'artifact correspondant aux filtres
artifacts = api.registries(filter=registry_filters).collections().versions(filter=version_filters)
# Afficher le nom, la collection, les alias, les tags et la date created_at de chaque artifact trouvé
for art in artifacts:
print(f"nom de l'artifact : {art.name}")
print(f"collection à laquelle appartient l'artifact : { art.collection.name}")
print(f"alias de l'artifact : {art.aliases}")
print(f"tags associés à l'artifact : {art.tags}")
print(f"artifact créé le : {art.created_at}\n")