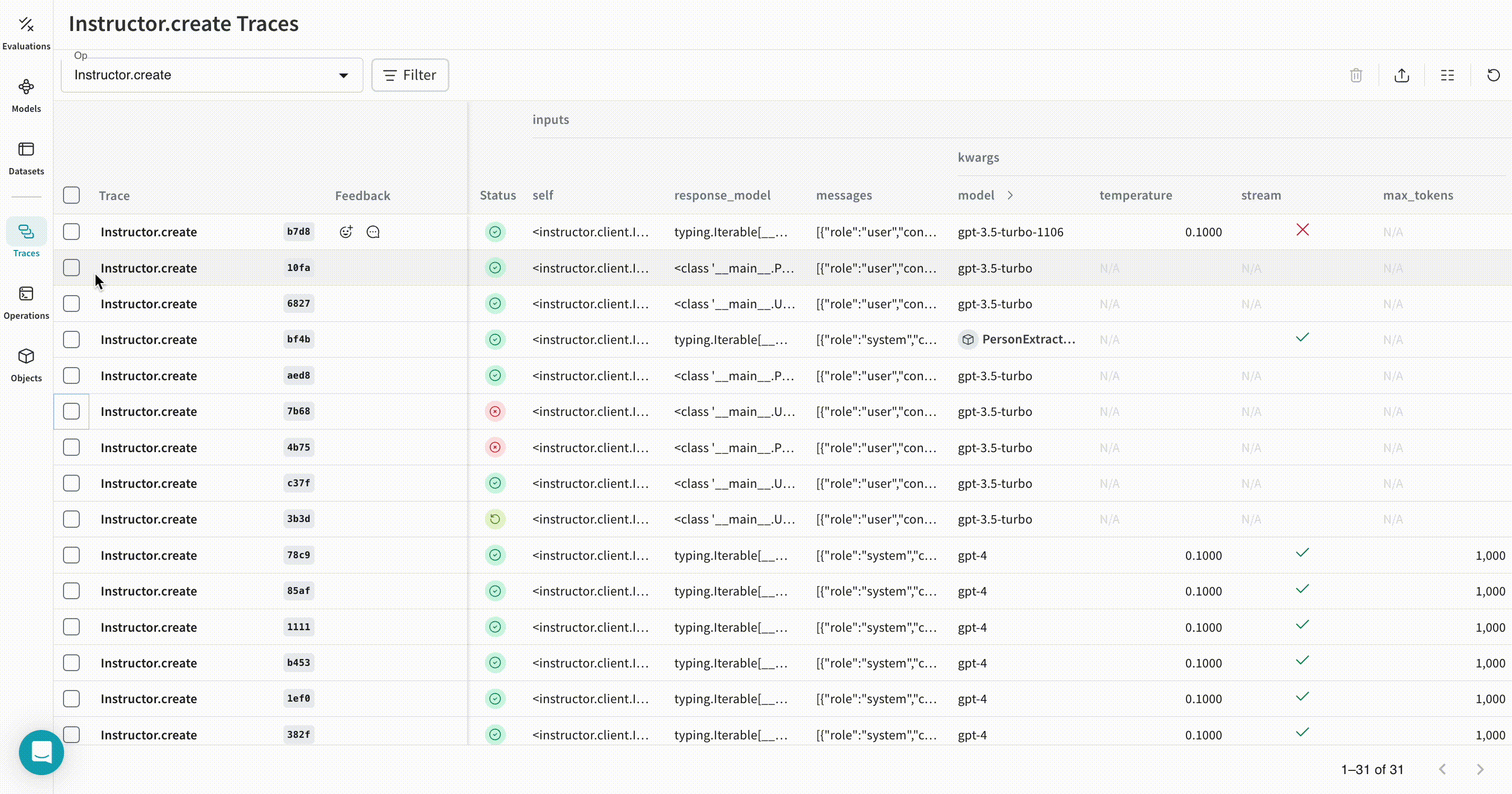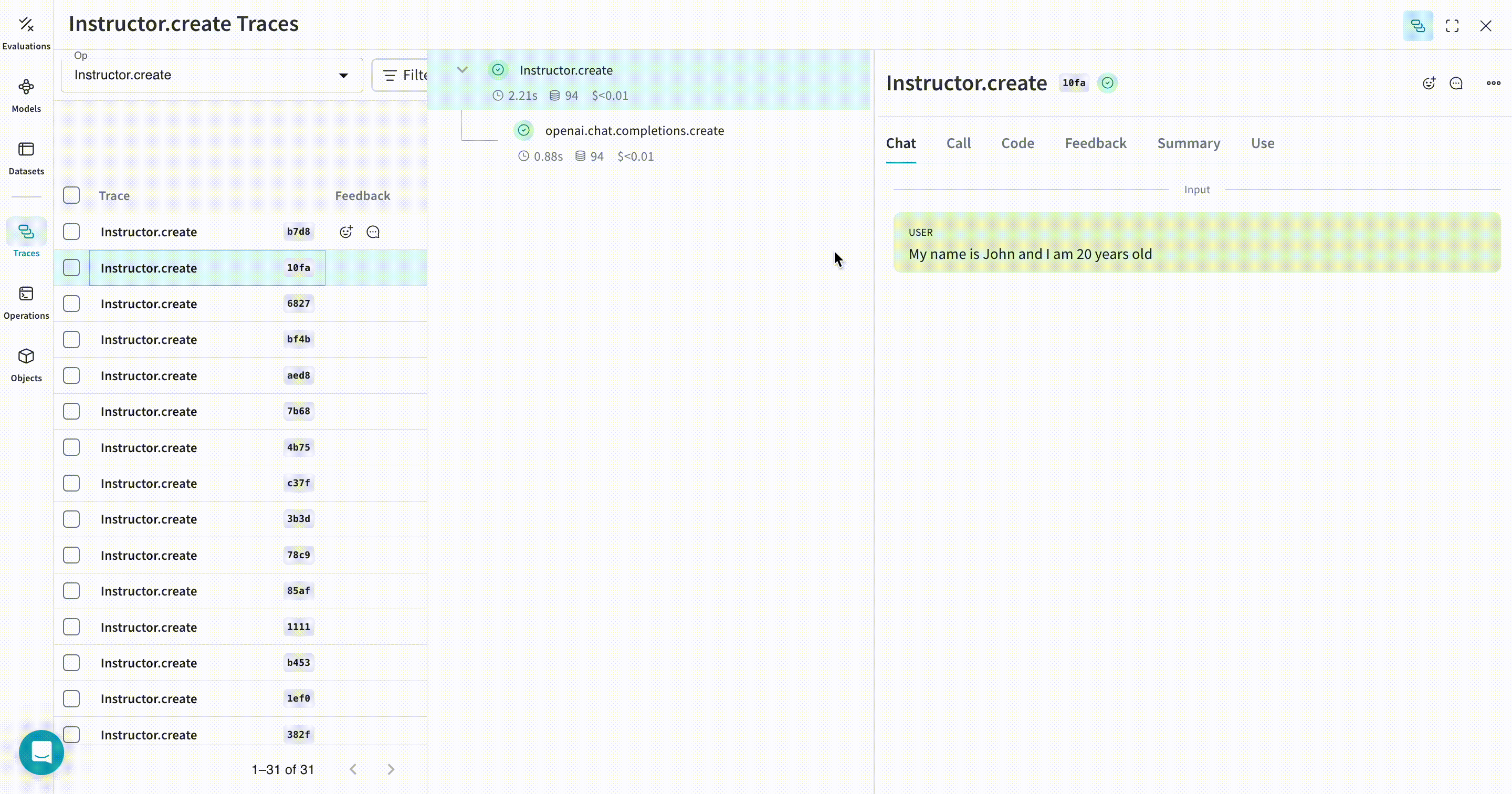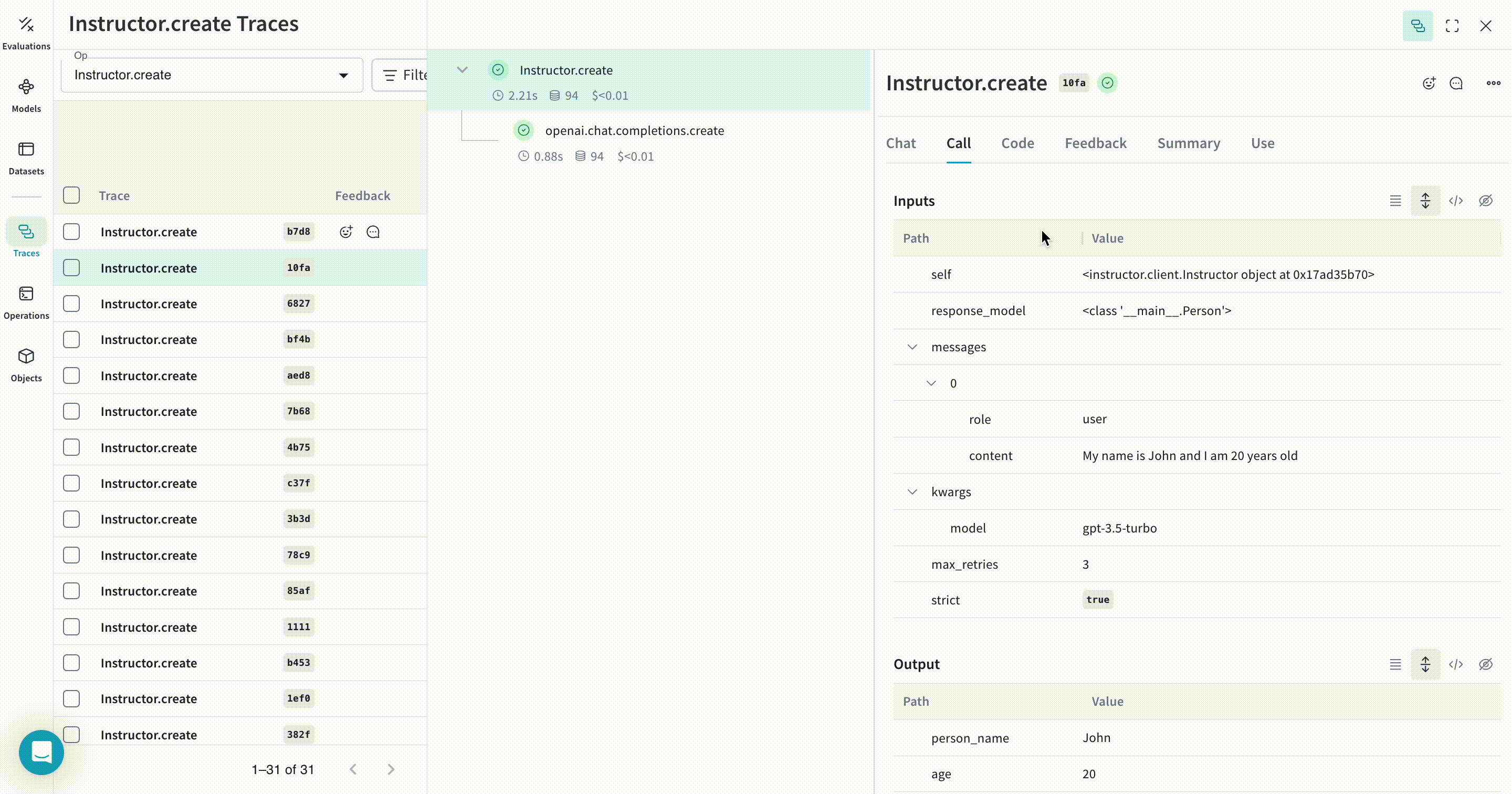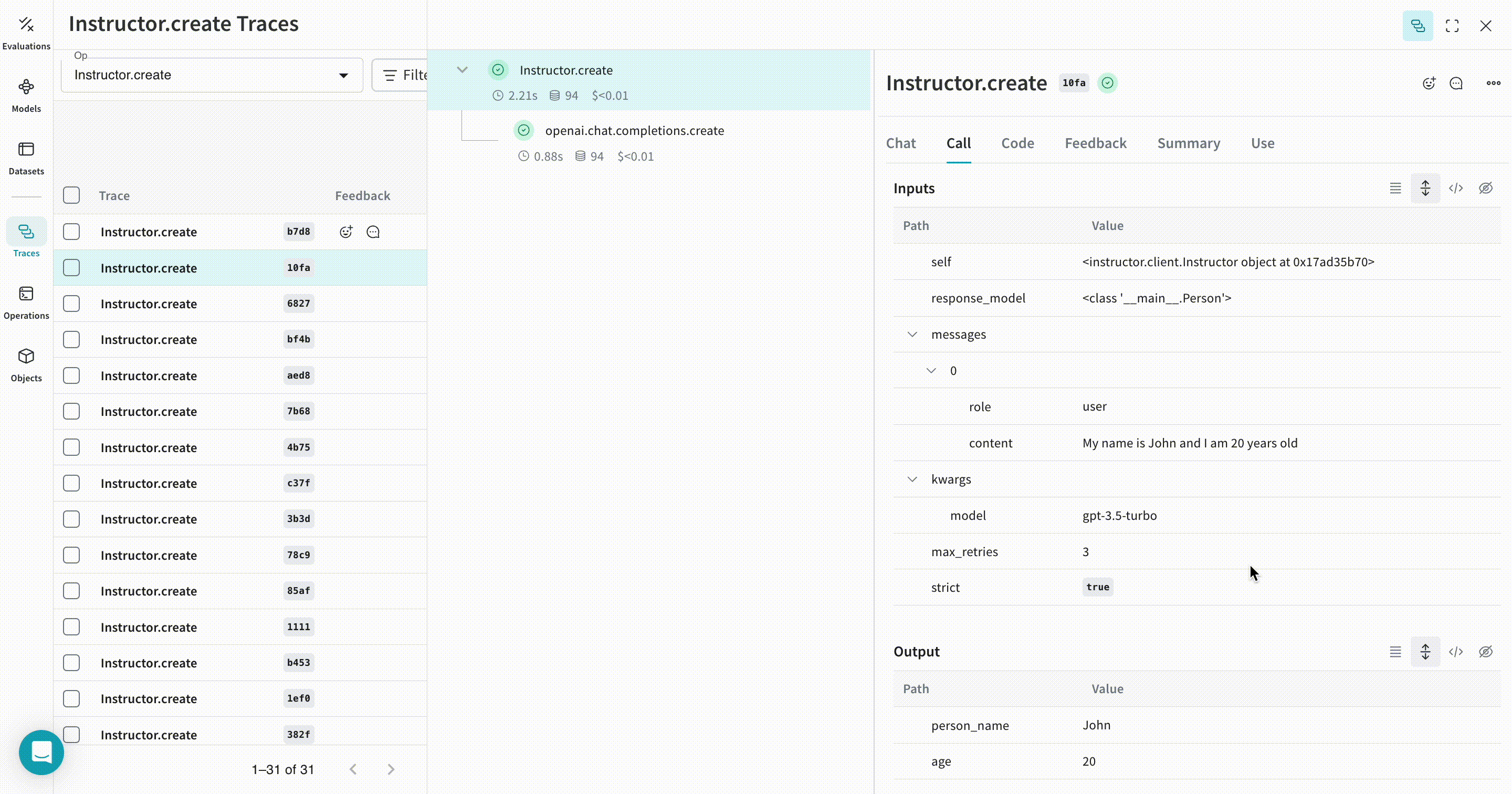
トレース
weave.init(project_name="<YOUR-WANDB-PROJECT-NAME>") を呼び出し、その後は通常どおりライブラリを使用してください。
 |
|---|
| これで Weave は、Instructor を使用して行われるすべての LLM 呼び出しを追跡し、ログとして記録します。トレースは Weave の Web インターフェースで確認できます。 |
自分の op をトラッキングする
@weave.op でラップすると、入力・出力やアプリのロジックのキャプチャが始まり、アプリ内でデータがどのように流れているかをデバッグできるようになります。op は深くネストしてツリー状の関数構造を作成でき、追跡したい関数を細かく指定できます。また、実験中のコードも自動でバージョニングされるため、まだ git にコミットしていないアドホックな変更内容も記録されます。
@weave.op でデコレートされた関数を作成するだけです。
以下の例では、extract_person という関数が、@weave.op でラップされたメトリクス関数になっています。これにより、OpenAI の chat completion 呼び出しなどの中間ステップがどのように処理されているかを確認できます。
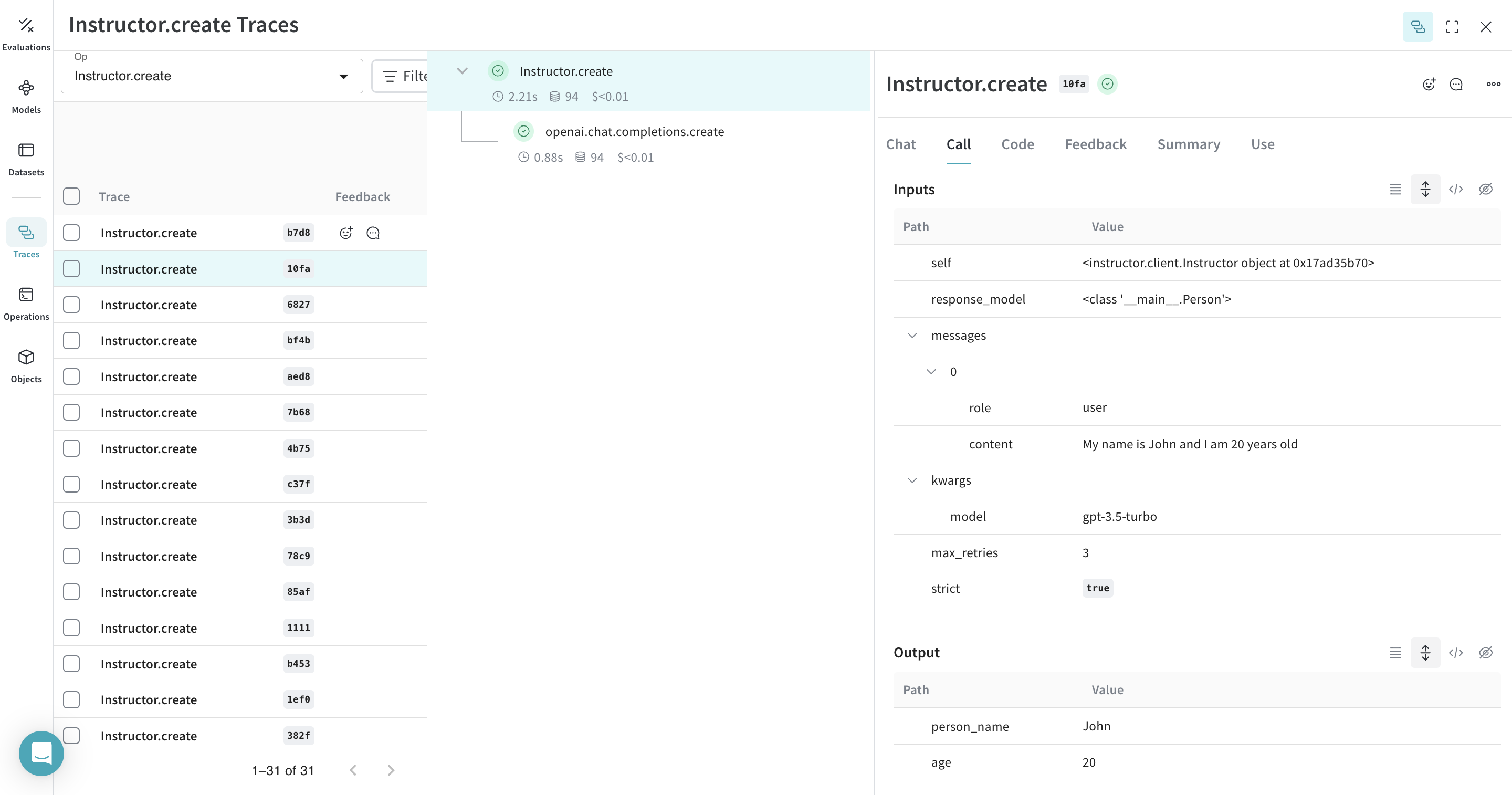 |
|---|
extract_person 関数に @weave.op デコレータを付与すると、関数の入力、出力、および関数内で行われるすべての内部 LM 呼び出しがトレースされます。さらに Weave は、Instructor によって生成された構造化オブジェクトも自動的に追跡し、バージョン管理します。 |
実験を効率化するために Model を作成する
Model クラスを使うことで、システムプロンプトや使用しているモデルなど、アプリの実験に関する詳細を保存・整理できます。これにより、アプリのさまざまな反復バージョンを体系的に整理し、比較しやすくなります。
コードのバージョン管理や入出力の記録に加えて、Model はアプリケーションの挙動を制御する構造化されたパラメータも保持するため、どのパラメータ設定が最も有効だったかを簡単に見つけることができます。Weave Models は serve(後述)や Evaluation と組み合わせて使用することもできます。
以下の例では、PersonExtractor を使って実験できます。これらの設定のいずれかを変更するたびに、PersonExtractor の新しい バージョン が作成されます。
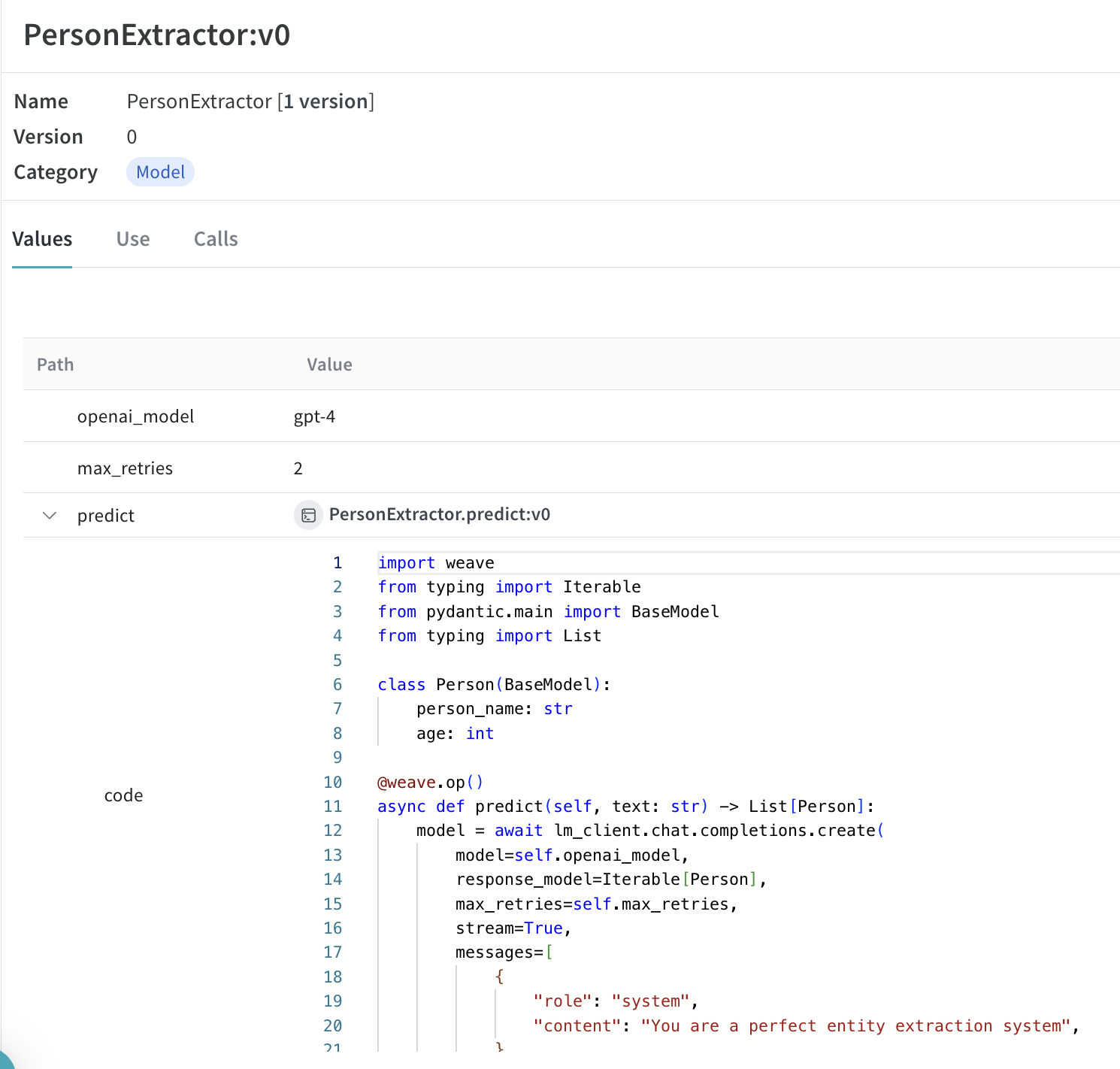 |
|---|
Model を使って呼び出しをトレースし、バージョン管理する |
Weave モデルの提供
weave.Model オブジェクトへの Weave リファレンスがあれば、FastAPI サーバーを立ち上げて、それを serve できます。
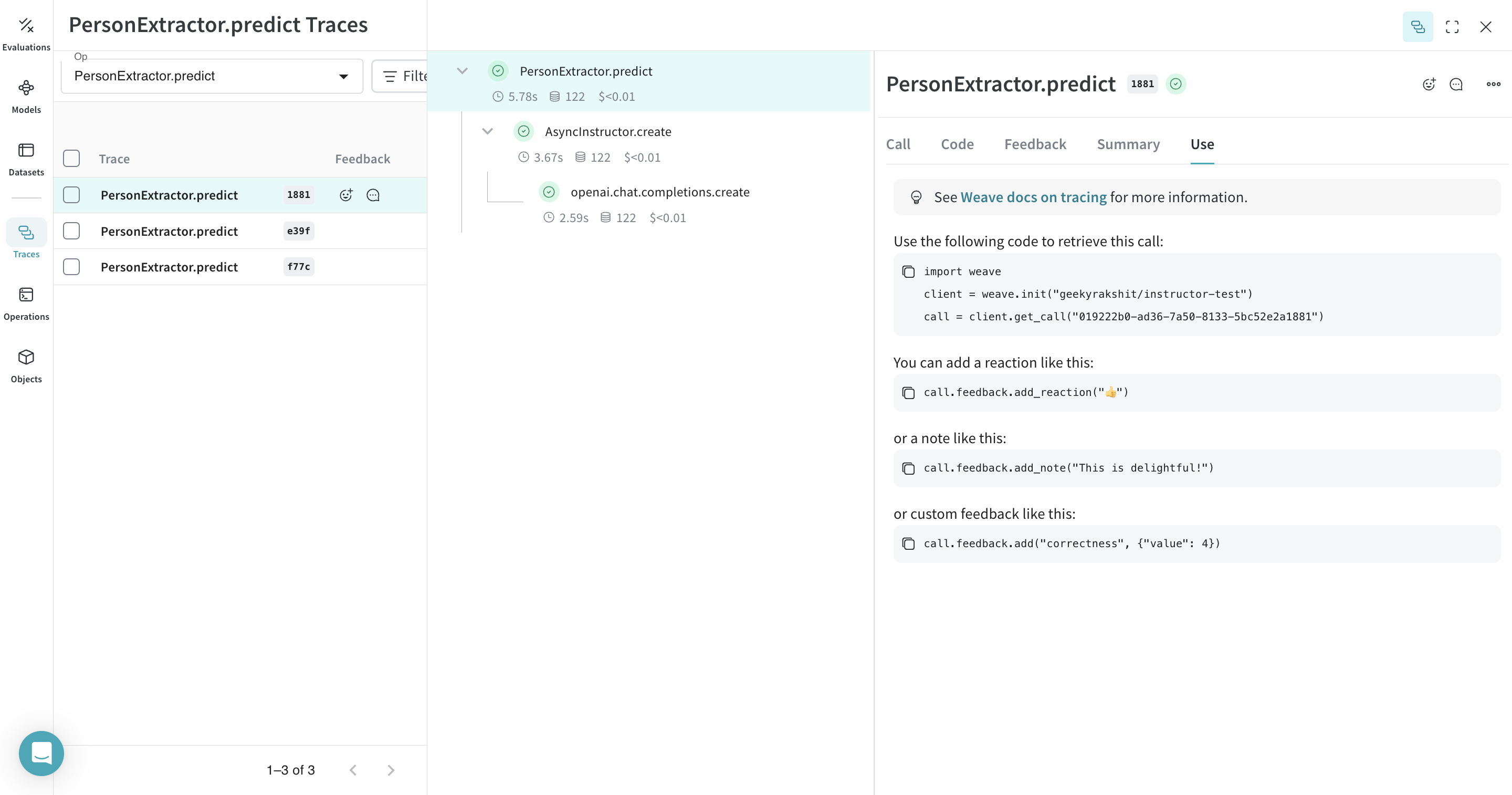 |
|---|
任意の weave.Model の Weave リファレンスは、モデル画面に移動し、UI からコピーすることで取得できます。 |