はじめに
uv を使用して Verifiers ライブラリをインストールします(uv の使用はライブラリの作者により推奨されています)。ライブラリをインストールするには、次のいずれかのコマンドを使用します:
ロールアウトをトレースして評価する
実験トラッキングとトレーシングを用いたモデルのファインチューニング
verifiers リポジトリには、すぐに実行できるサンプルが含まれており、すぐに使い始めるのに役立ちます。
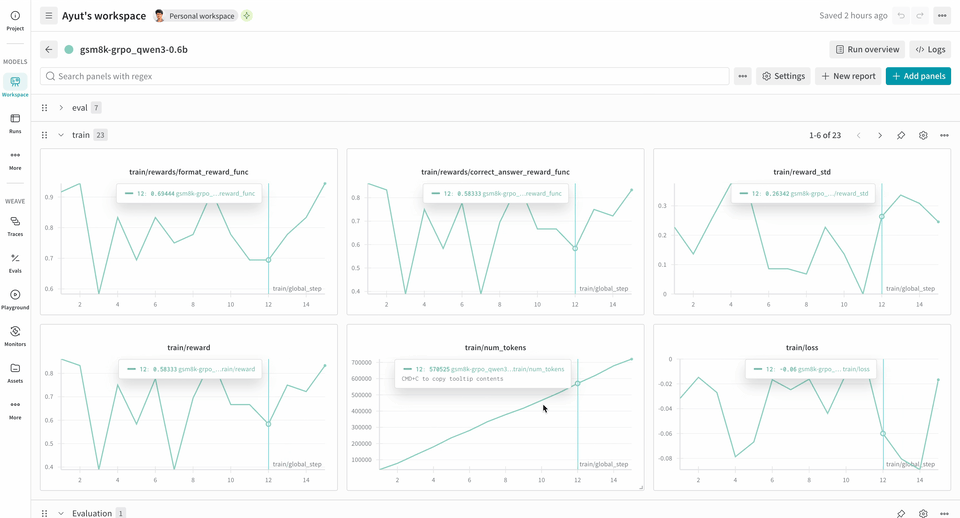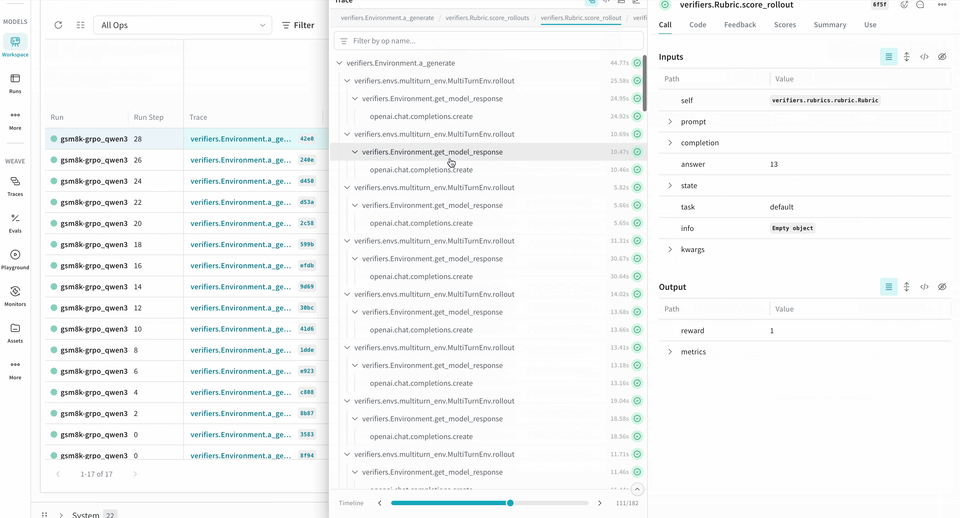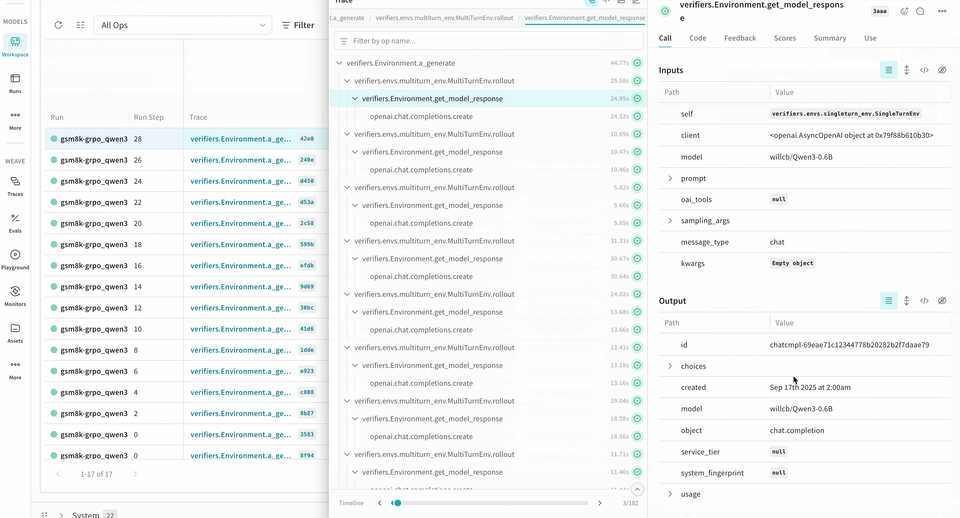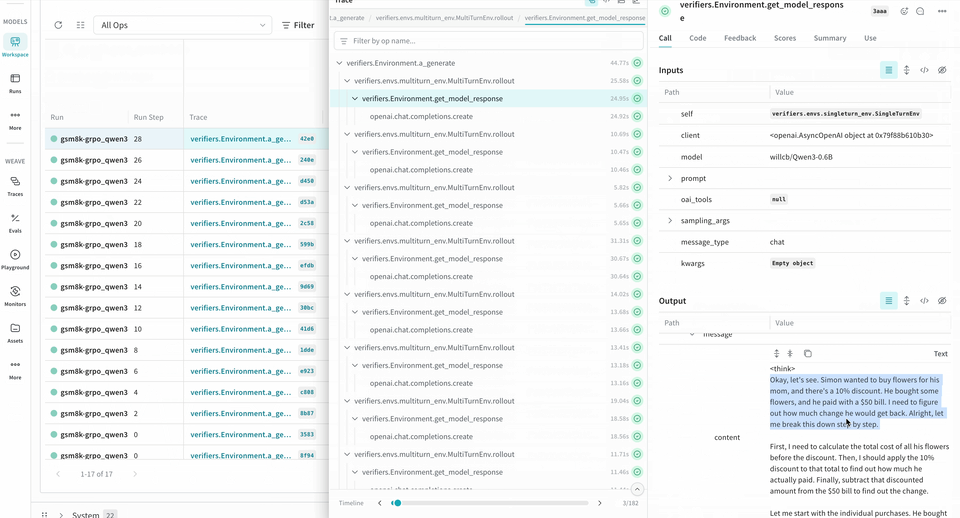
次の RL 学習パイプラインの例では、ローカル推論サーバーを起動し、GSM8K データセットを使ってモデルを学習します。モデルは数学の問題に対する解答を返し、学習ループが出力にスコアを付け、それに応じてモデルを更新します。W&B は loss、reward、accuracy などの学習メトリクスをログし、Weave は入力、出力、推論過程、およびスコアリングを取得します。
このパイプラインを使用するには、次の手順を実行します。
- ソースからフレームワークをインストールします。以下のコマンドは、GitHub から Verifiers ライブラリと必要な依存関係をインストールします。
- 既製の環境をインストールします。次のコマンドで、事前構成済みの GSM8K 学習環境をインストールします:
- モデルを学習します。次のコマンドは、それぞれ推論サーバーと学習ループを起動します。このサンプルワークフローでは
report_to=wandbがデフォルトで設定されているため、別途wandb.initを呼び出す必要はありません。メトリクスを W&B にログとして記録できるよう、このマシンを認証するよう求められます。
この例は 2xH100 上で正常に動作することを確認しており、安定性を高めるために次の環境変数を設定しました:これらの変数は、デバイスメモリ割り当てに対する CUDA Unified Memory (CuMem) を無効化します。
Environment.a_generate メソッドおよび Rubric.score_rollouts メソッドの logprobs は含まれません。これにより、元データは学習用にそのまま保持しつつ、ペイロードサイズを小さく抑えられます。