これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクから開くこともできます:
前提条件
1. Weave を使ってプロンプトを作成し、反復的に改善する
2. データセットを取得する
base64 でエンコードされているため、LLM は事前処理なしにそのままこのデータを利用できます。
3. NER パイプラインを構築する
- データセットから受け取った PIL 画像を、VLM に渡すことができる
base64形式の文字列表現に変換して返すencode_image関数 - 画像とシステムプロンプトを受け取り、そのシステムプロンプトで指示されたとおりに画像から抽出された固有表現を返す
extract_named_entities_from_image関数
named_entity_recognation という関数を作成します:
- 画像データを NER パイプラインに渡す
- 結果を正しくフォーマットされた JSON で返す
@weave.op() decorator デコレーターを使用します。
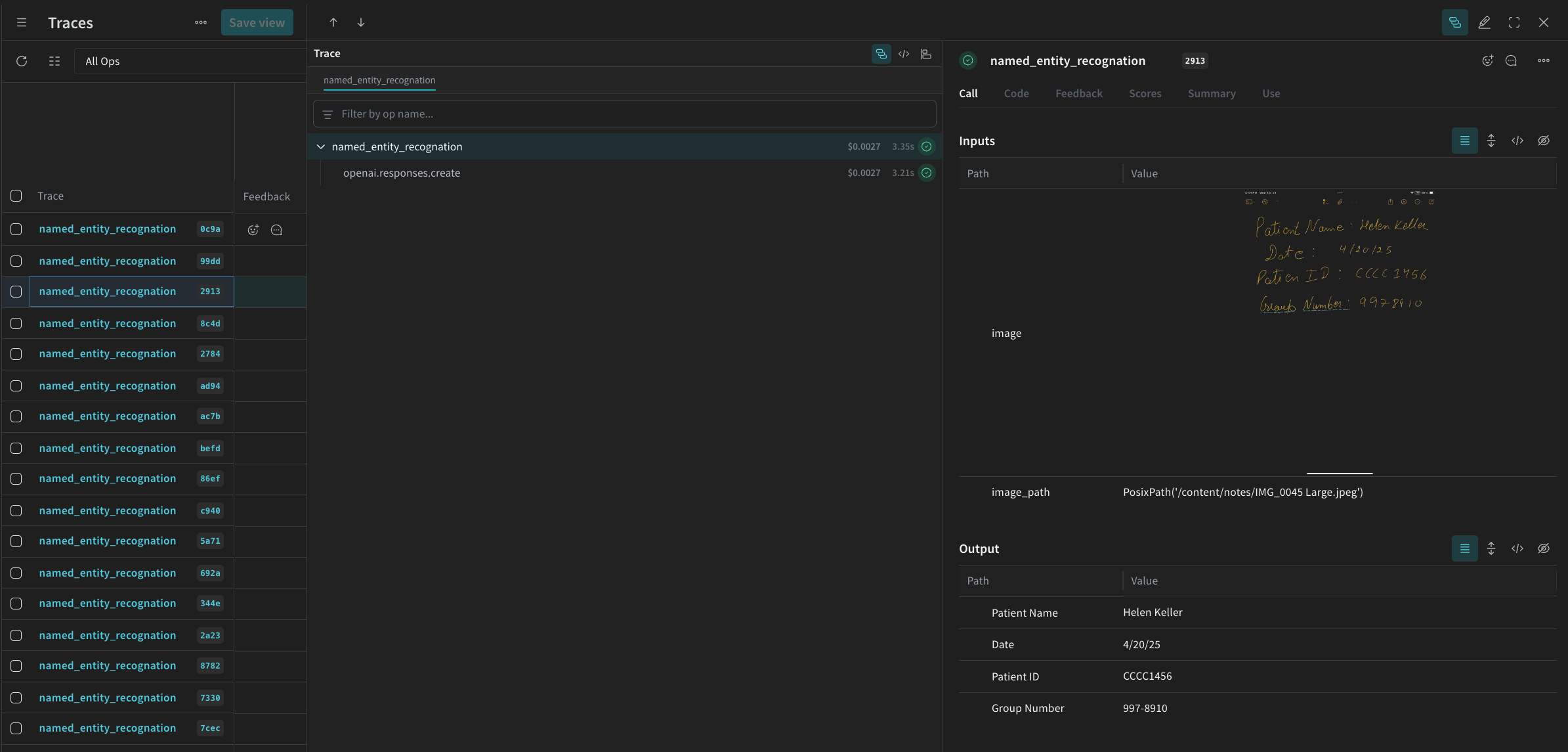
named_entity_recognation が実行されるたびに、すべてのトレース結果が Weave UI で確認できます。トレースを表示するには、Weave プロジェクトの Traces タブに移動します。
processing_results.json に保存します。結果は Weave の UI 上でも参照できます。
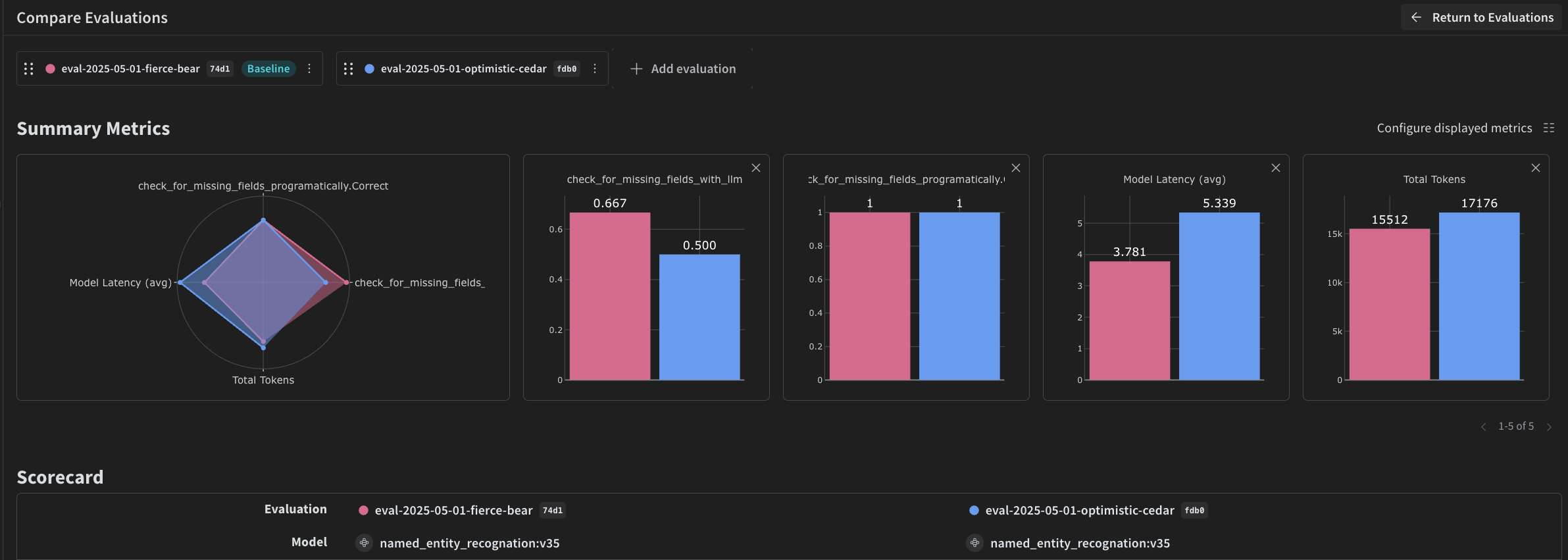
4. Weave を使ってパイプラインを評価する
- プログラムによる Scorer
- LLM-as-a-judge Scorer
プログラムによるスコアラー
check_for_missing_fields_programatically は、モデル出力(named_entity_recognition 関数の出力)を受け取り、結果の中でどの keys が欠落しているか、または空になっているかを特定します。
このチェックは、モデルがいずれのフィールドも抽出できなかったサンプルを特定するのに有用です。
LLM-as-a-judge スコアラー
check_for_missing_fields_with_llm は、LLM(具体的には OpenAI の gpt-4o)を用いてスコアリングを行います。eval_prompt の内容で指定されているとおり、check_for_missing_fields_with_llm は Boolean 値を出力します。すべてのフィールドが画像内の情報と一致し、かつフォーマットが正しければ、Scorer は true を返します。いずれかのフィールドが欠落している、空である、不正確である、あるいは不一致である場合、結果は false となり、Scorer は問題点を説明するメッセージも返します。
5. 評価を実行する
dataset を自動的に繰り返し処理し、結果を Weave UI にまとめてログする評価用の呼び出しを定義します。
次のコードは評価の実行を開始し、NER パイプラインのすべての出力に 2 つの Scorer を適用します。結果は Weave UI の Evals タブで確認できます。