これはインタラクティブなノートブックです。ローカルで実行するか、次のリンクを使用してください: DSPy と Weave を使った LLM ワークフローの最適化
- LLM ワークフローの構築と最適化のための DSPy
- LLM ワークフローのトラッキングとプロンプト戦略の評価のための Weave
- Hugging Face Hub から Big-Bench Hard データセットにアクセスするための datasets
!pip install -qU dspy-ai weave datasets
import os
from getpass import getpass
api_key = getpass("Enter you OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = api_key
weave.init を呼び出すことで、DSPy の関数を自動的にトレースし、その結果を Weave UI 上で確認・探索できるようになります。詳しくは、DSPy 向け Weave インテグレーションのドキュメント を参照してください。
import weave
weave.init(project_name="dspy-bigbench-hard")
weave.Object を継承するメタデータクラスを使用します。
class Metadata(weave.Object):
dataset_address: str = "maveriq/bigbenchhard"
big_bench_hard_task: str = "causal_judgement"
num_train_examples: int = 50
openai_model: str = "gpt-3.5-turbo"
openai_max_tokens: int = 2048
max_bootstrapped_demos: int = 8
max_labeled_demos: int = 8
metadata = Metadata()
オブジェクトのバージョニング: Metadata オブジェクトは、それらを利用する関数がトレース対象になると、自動的にバージョン管理およびトレースされます
BIG-Bench Hard データセットを読み込む
weave.Evaluation を使ってプロンプト戦略を評価できるようになります。
import dspy
from datasets import load_dataset
@weave.op()
def get_dataset(metadata: Metadata):
# Huggingface Hub からタスクに対応する BIG-Bench Hard データセットを読み込む
dataset = load_dataset(metadata.dataset_address, metadata.big_bench_hard_task)[
"train"
]
# 学習用および検証用データセットを作成する
rows = [{"question": data["input"], "answer": data["target"]} for data in dataset]
train_rows = rows[0 : metadata.num_train_examples]
val_rows = rows[metadata.num_train_examples :]
# `dspy.Example` オブジェクトで構成される学習用および検証用サンプルを作成する
dspy_train_examples = [
dspy.Example(row).with_inputs("question") for row in train_rows
]
dspy_val_examples = [dspy.Example(row).with_inputs("question") for row in val_rows]
# データセットを Weave に公開する。これによりデータのバージョン管理と評価への利用が可能になる
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_train", rows=train_rows
)
)
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_val", rows=val_rows
)
)
return dspy_train_examples, dspy_val_examples
dspy_train_examples, dspy_val_examples = get_dataset(metadata)
dspy.OpenAI 抽象化を使って、GPT3.5 Turbo への LLM 呼び出しを行います。
system_prompt = """
You are an expert in the field of causal reasoning. You are to analyze the a given question carefully and answer in `Yes` or `No`.
You should also provide a detailed explanation justifying your answer.
"""
llm = dspy.OpenAI(model="gpt-3.5-turbo", system_prompt=system_prompt)
dspy.settings.configure(lm=llm)
from pydantic import BaseModel, Field
class Input(BaseModel):
query: str = Field(description="回答される質問")
class Output(BaseModel):
answer: str = Field(description="質問に対する回答")
confidence: float = Field(
ge=0, le=1, description="回答の信頼スコア"
)
explanation: str = Field(description="回答の説明")
class QuestionAnswerSignature(dspy.Signature):
input: Input = dspy.InputField()
output: Output = dspy.OutputField()
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.TypedPredictor(QuestionAnswerSignature)
@weave.op()
def forward(self, question) -> dict:
return self.prog(input=Input(query=question)).output.dict()
CausalReasoningModule をテストしてみましょう。
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
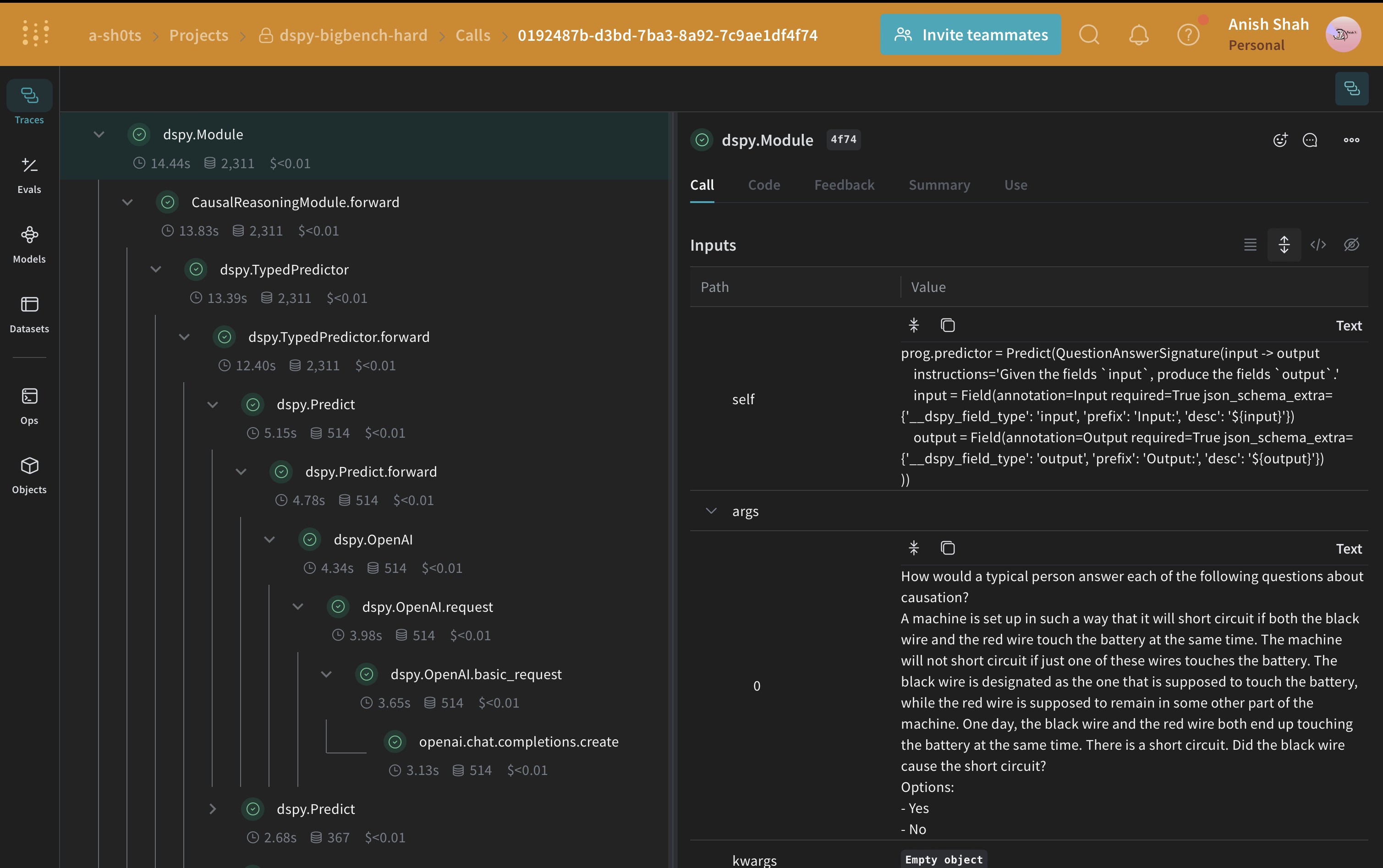
DSPy プログラムを評価する
weave.Evaluation を使い、予測された答えと正解ラベルを照合する単純なメトリクスで検証用データセットに対する評価を実行します。Weave は各サンプルを取り出してアプリケーションに通し、複数のカスタムスコアリング関数で出力にスコアを付けます。これにより、アプリケーションのパフォーマンスを俯瞰できるだけでなく、個々の出力やスコアを掘り下げて確認できるリッチな UI も利用できます。
まず、ベースラインモジュールの出力から得られる答えが正解ラベルと一致するかどうかを判定する、シンプルな Weave の評価用スコアリング関数を作成する必要があります。スコアリング関数には model_output というキーワード引数が必要ですが、それ以外の引数はユーザー定義であり、データセットのサンプルから取得されます。引数名に基づく辞書キーを使うことで、必要なキーだけが渡されます。
@weave.op()
def weave_evaluation_scorer(answer: str, output: Output) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(baseline_module.forward)
Python スクリプトから実行する場合は、次のコードで評価を実行できます。import asyncio
asyncio.run(evaluation.evaluate(baseline_module.forward))
因果推論データセットの評価を実行すると、OpenAI クレジットで約 $0.24 のコストが発生します。
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
評価用因果推論データセットを実行すると、OpenAI クレジットが約 $0.04 分消費されます。
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(optimized_module.forward)



