これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクのいずれかを使用できます:
Not Diamond を用いた LLM プロンプトのカスタムルーティング
プロンプトのルーティング
カスタムルーティング
- LLMプロンプトのセット: プロンプトは文字列であり、アプリケーションで実際に使用しているプロンプトを代表する必要があります。
- LLMの応答: 各入力に対する候補LLMからの応答です。候補LLMには、サポートされているLLMと、独自のカスタムモデルの両方を含めることができます。
- 候補LLMからの入力に対する応答の評価スコア: スコアは数値であり、ニーズに合う任意の指標を使用できます。
学習データのセットアップ
カスタムルーターの学習
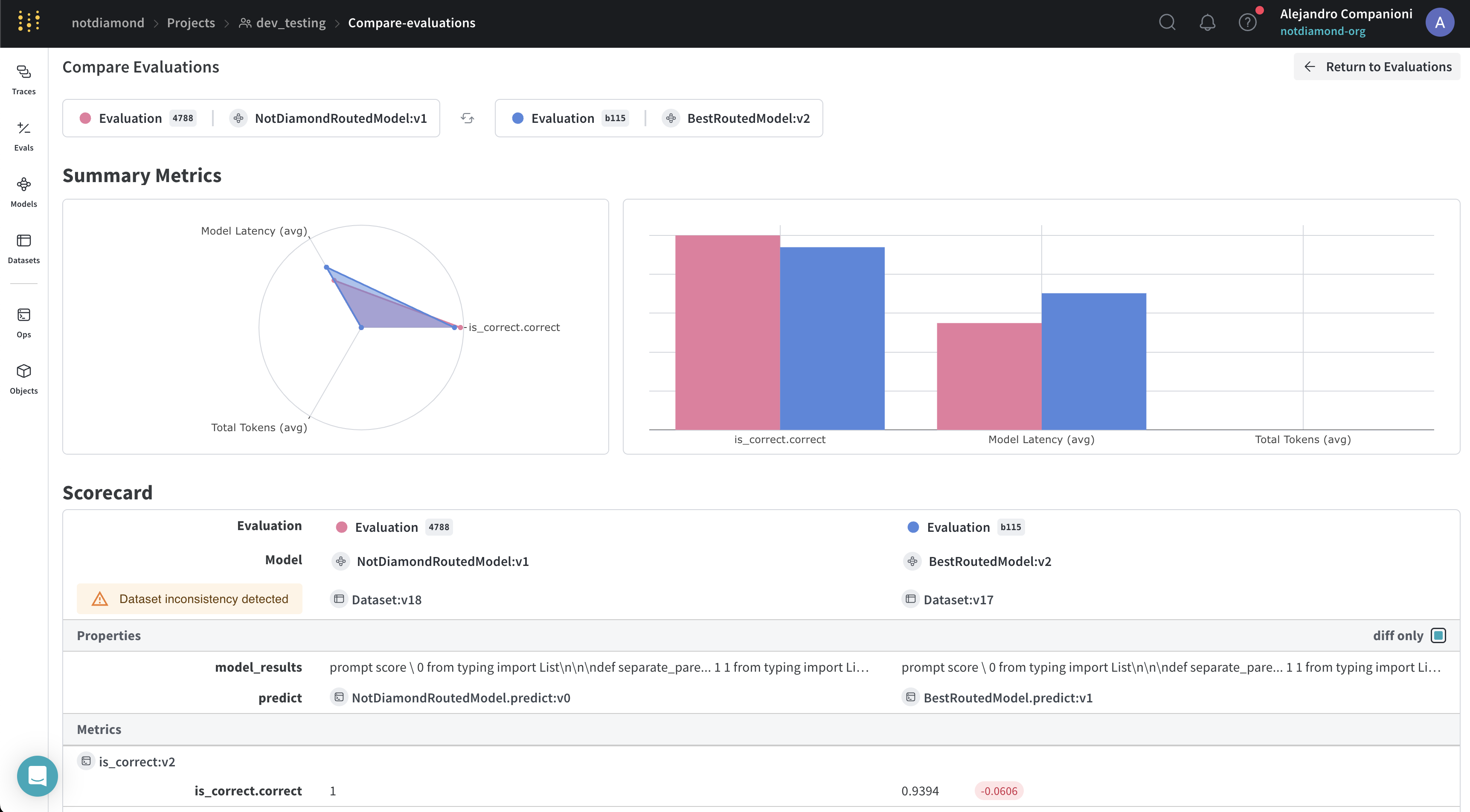
カスタムルーターの評価
- 学習プロンプトを送信してインサンプルでの性能を評価する
- 新規またはホールドアウトしたプロンプトを送信してアウトオブサンプルでの性能を評価する