LLM Evaluation Jobs は W&B Multi-tenant Cloud で プレビュー として提供されています。プレビュー期間中のコンピュート料金は無料です。詳細はこちらをご覧ください。
前提条件
- LLM Evaluation Job の要件と制限事項を確認します。
- 一部のベンチマークを実行するには、チーム管理者が必要な APIキーをチームスコープのシークレットとして追加しておく必要があります。任意のチームメンバーが、評価ジョブの設定時にそのシークレットを指定できます。
- OpenAPI API key: OpenAI モデルをスコアリングに使用するベンチマークで使用します。ベンチマークを選択した後に Scorer API key フィールドが表示される場合は必須です。シークレット名は
OPENAI_API_KEYである必要があります。 - Hugging Face user access token: 1つ以上の制限付き Hugging Face データセットへのアクセスが必要な
lingolyやlingoly2など、特定のベンチマークで必要です。ベンチマークを選択した後に Hugging Face Token フィールドが表示される場合は必須です。APIキーには、該当するデータセットへのアクセス権が付与されている必要があります。Hugging Face のドキュメント User access tokens および accessing gated datasets を参照してください。 - W&B Inference が提供するモデルを評価するには、組織またはチーム管理者が任意の値で
WANDB_API_KEYを作成する必要があります。このシークレットは実際の認証には使用されません。
- OpenAPI API key: OpenAI モデルをスコアリングに使用するベンチマークで使用します。ベンチマークを選択した後に Scorer API key フィールドが表示される場合は必須です。シークレット名は
- 評価対象のモデルは、パブリックにアクセス可能な URL で利用できる必要があります。組織またはチーム管理者が、認証用の APIキーを含むチームスコープのシークレットを作成する必要があります。
- 評価結果を保存するための新しい W&B project を作成します。プロジェクトのサイドバーから Create new project をクリックします。
- 各ベンチマークについて、その仕組みや特有の要件を理解するためにドキュメントを確認します。参考として、Available evaluation benchmarks リファレンスに関連リンクがまとめられています。
モデルを評価する
- W&B にログインし、プロジェクトのサイドバーで Launch をクリックします。LLM Evaluation Jobs ページが表示されます。
- 評価をセットアップするには、Evaluate hosted API model をクリックします。
- 評価結果を保存する宛先プロジェクトを選択します。
- Model セクションで、評価対象のベース URL とモデル名を指定し、認証に使用する APIキー を選択します。AI Security Institute で定義されている OpenAI 互換形式でモデル名を指定します。たとえば、OpenAI モデルの場合は次の構文で指定します:
openai/<model-name>。ホスト型モデルプロバイダとモデルの包括的な一覧については、AI Security Institute のモデルプロバイダリファレンス を参照してください。- W&B Inference が提供するモデルを評価するには、ベース URL を
https://api.inference.wandb.ai/v1に設定し、モデル名を次の構文で指定します:openai-api/wandb/<model_id>。詳細については Inference model catalog を参照してください。 - OpenRouter プロバイダを使用するには、モデル名の前に
openrouterを付け、次の構文で指定します:openrouter/<model-name>。 - OpenAPI 準拠のカスタムモデルを評価するには、モデル名を次の構文で指定します:
openai-api/wandb/<model-name>。
- W&B Inference が提供するモデルを評価するには、ベース URL を
- Select evaluations をクリックし、実行するベンチマークを最大 4 つまで選択します。
- スコアリングに OpenAI モデルを使用するベンチマークを選択した場合は、Scorer API key フィールドが表示されます。そこをクリックし、
OPENAI_API_KEYシークレットを選択します。必要に応じて、チーム管理者はこのドロワーから Create secret をクリックしてシークレットを作成できます。 - Hugging Face のゲート付きデータセットへのアクセスを必要とするベンチマークを選択した場合は、Hugging Face token フィールドが表示されます。該当データセットへのアクセスをリクエスト し、Hugging Face ユーザーアクセス用トークンを含むシークレットを選択します。
- 任意で、Sample limit に正の整数を設定して、評価するベンチマークサンプル数の上限を制限します。設定しない場合は、そのタスクのすべてのサンプルが含まれます。
- リーダーボードを自動で作成するには、Publish results to leaderboard をクリックします。リーダーボードには、すべての評価がワークスペースパネル内でまとめて表示され、レポート内で共有することもできます。
- Launch をクリックして評価ジョブを起動します。
- ページ上部の円形の矢印アイコンをクリックして、最近の run モーダルを開きます。評価ジョブは他の最近の run と一緒に表示されます。完了した run の名前をクリックすると単一 run ビューで開き、Leaderboard リンクをクリックするとリーダーボードを直接開きます。詳細は 結果を表示する を参照してください。
simpleqa ベンチマークを OpenAI モデル o4-mini に対して実行しています:
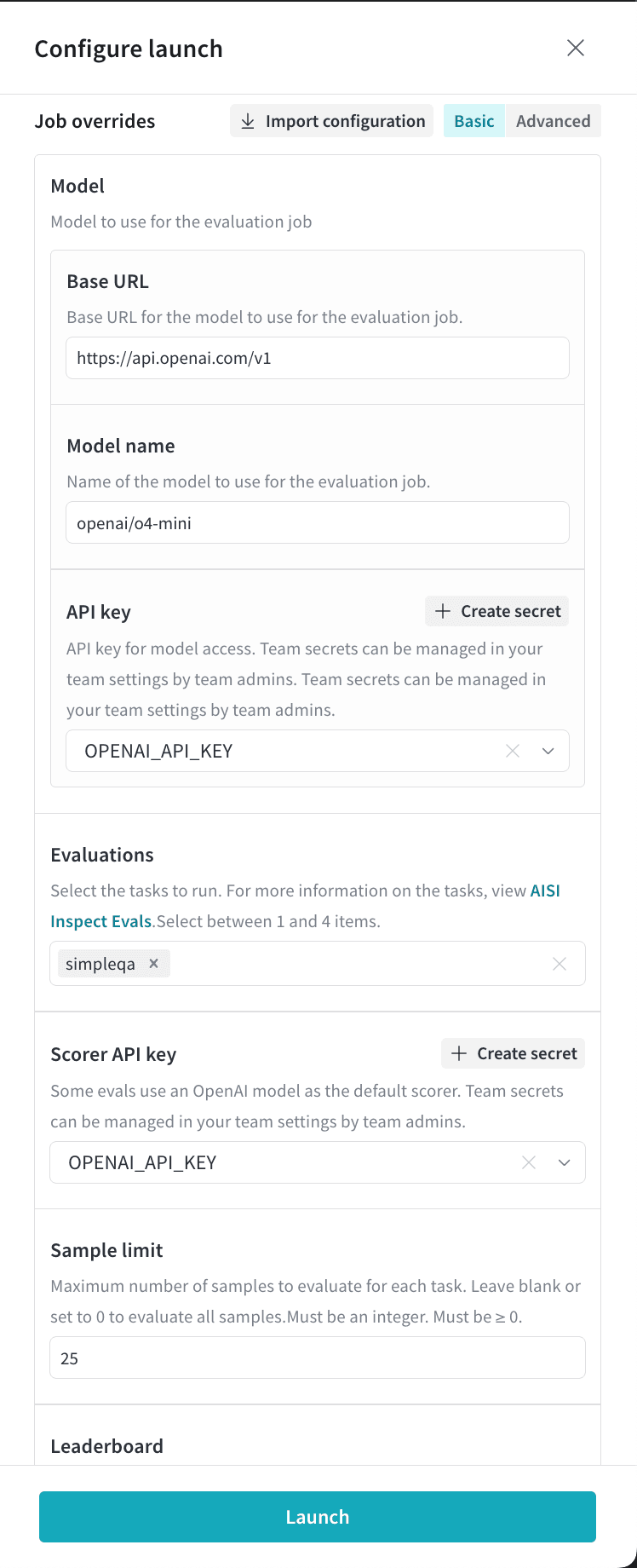
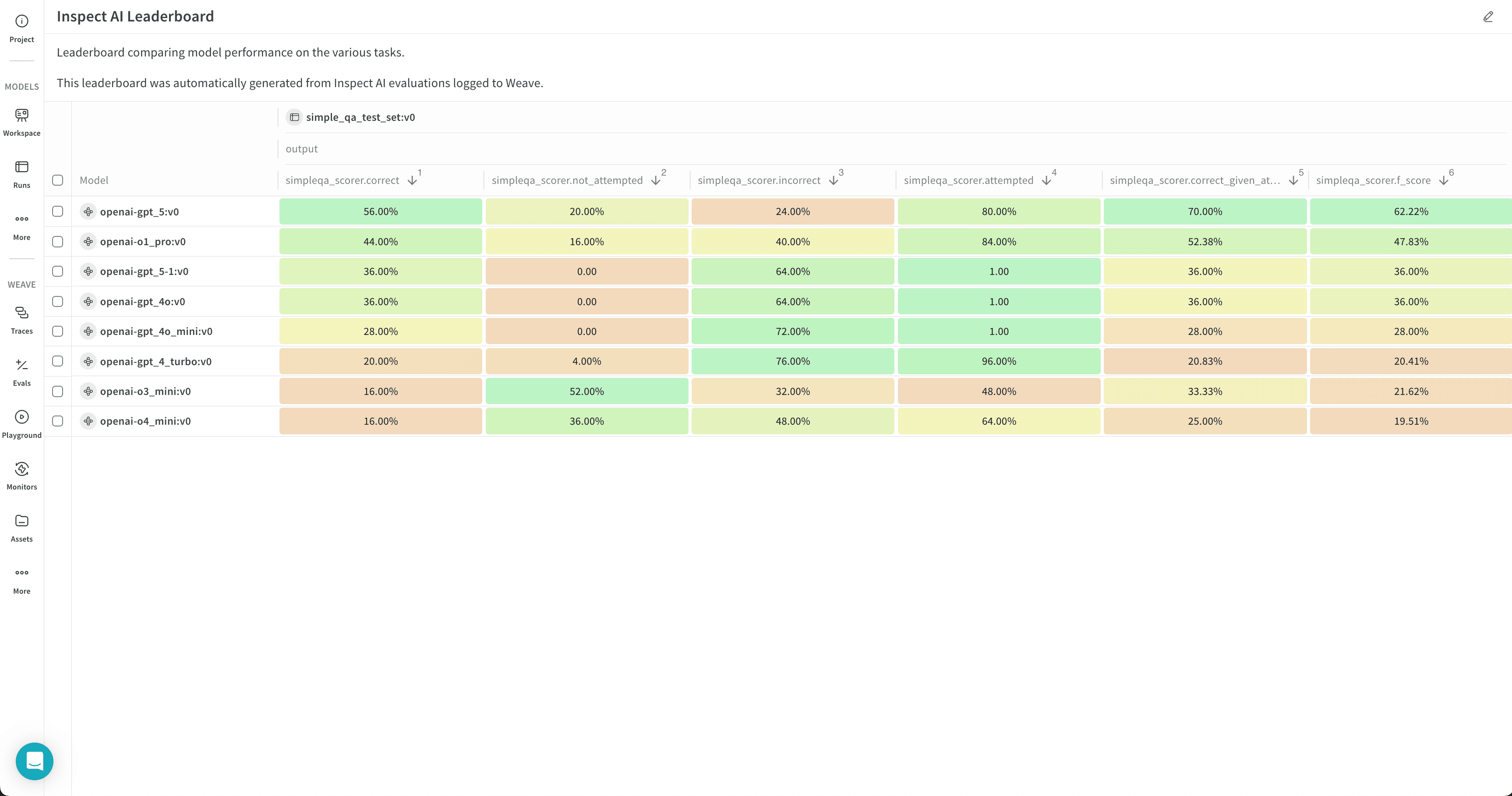
評価結果を確認する
- ページ上部の円形の矢印アイコンをクリックして最近の run モーダルを開きます。ここに評価ジョブが、プロジェクト内の他の run と一緒に表示されます。評価ジョブにリーダーボードがある場合は、Leaderboard をクリックしてリーダーボードを全画面で開くか、run 名をクリックしてその run をプロジェクト内の単一 run ビューで開きます。
- ワークスペースの Evaluations セクション、または Weave サイドバー パネルの Traces タブで、評価ジョブのトレースを表示します。
- Overview タブをクリックして、評価ジョブの設定やサマリーメトリクスなどの詳細情報を表示します。
- Logs タブをクリックして、評価ジョブのデバッグログを表示、検索、またはダウンロードします。
- Files タブをクリックして、コード、ログ、設定ファイルやその他の出力ファイルを含む評価ジョブのファイルを参照、表示、またはダウンロードします。
リーダーボードをカスタマイズする
- デフォルトでは、すべての評価ジョブが表示されます。左側の run セレクタを使用して、評価ジョブをフィルタリングまたは検索します。
- デフォルトでは、評価ジョブはグループ化されていません。1 つ以上の列でグループ化するには、Group アイコンをクリックします。グループを表示または非表示にしたり、グループを展開してその中の run を表示できます。
- デフォルトでは、すべてのオペレーションが表示されます。1 つのオペレーションのみを表示するには、All ops をクリックしてオペレーションを選択します。
- 列でソートするには、列見出しをクリックします。列の表示をカスタマイズするには、Columns をクリックします。
- デフォルトでは、ヘッダーは 1 階層で構成されています。ヘッダー階層の深さを増やして、関連するヘッダーをまとめて整理できます。
- 個々の列を選択または選択解除して表示・非表示を切り替えるか、1 回のクリックですべての列を表示または非表示にできます。
- 列を固定して、固定されていない列より前に表示します。
リーダーボードをエクスポートする
- Columns ボタンの近くにあるダウンロードアイコンをクリックします。
- エクスポートサイズを抑えるため、デフォルトではトレースのルートのみがエクスポートされます。トレース全体をエクスポートするには、Trace roots only をオフにします。
- エクスポートサイズを抑えるため、デフォルトではフィードバックとコストはエクスポートされません。エクスポートに含めるには、Feedback または Costs をオンにします。
- デフォルトでは、エクスポート形式は JSONL です。形式を変更するには、Export to file をクリックして形式を選択します。
- ブラウザでリーダーボードをエクスポートするには、Export をクリックします。
- プログラムからリーダーボードをエクスポートするには、Python または cURL を選択し、Copy をクリックしてスクリプトまたはコマンドを実行します。
評価ジョブを再実行する
- 直近の評価ジョブをもう一度実行するには、モデルを評価するの手順に従ってください。宛先プロジェクトを選択すると、前回選択したモデルアーティファクトの詳細とベンチマークが自動的に入力されます。必要に応じて調整を行い、その後評価ジョブを起動します。
- プロジェクトの Runs タブまたは run セレクタから評価ジョブを再実行するには、run 名にカーソルを合わせて再生アイコンをクリックします。ジョブ設定ドロワーが表示され、設定があらかじめ入力されています。必要に応じて設定を調整し、Launch をクリックします。
- 別のプロジェクトから評価ジョブを再実行するには、その設定をインポートします:
- モデルを評価するの手順に従います。宛先プロジェクトを選択した後、Import configuration をクリックします。
- インポートしたい評価ジョブを含むプロジェクトを選択し、その評価ジョブの run を選択します。ジョブ設定ドロワーが表示され、設定があらかじめ入力されています。
- 必要に応じて設定を調整します。
- Launch をクリックします。
評価ジョブの設定をエクスポートする
- 対象の run を single-run view で開きます。
- Files タブをクリックします。
config.yamlの横にあるダウンロードボタンをクリックして、ローカルにダウンロードします。