LLM Evaluation Jobs は W&B Multi-tenant Cloud で プレビュー として提供されています。プレビュー期間中のコンピュート料金は無料です。詳細はこちらをご覧ください。
仕組み
- W&B Models で評価ジョブをセットアップします。ベンチマークや、リーダーボードを生成するかどうかといった設定を行います。
- 評価ジョブを起動します。
- 結果とリーダーボードを表示して分析します。
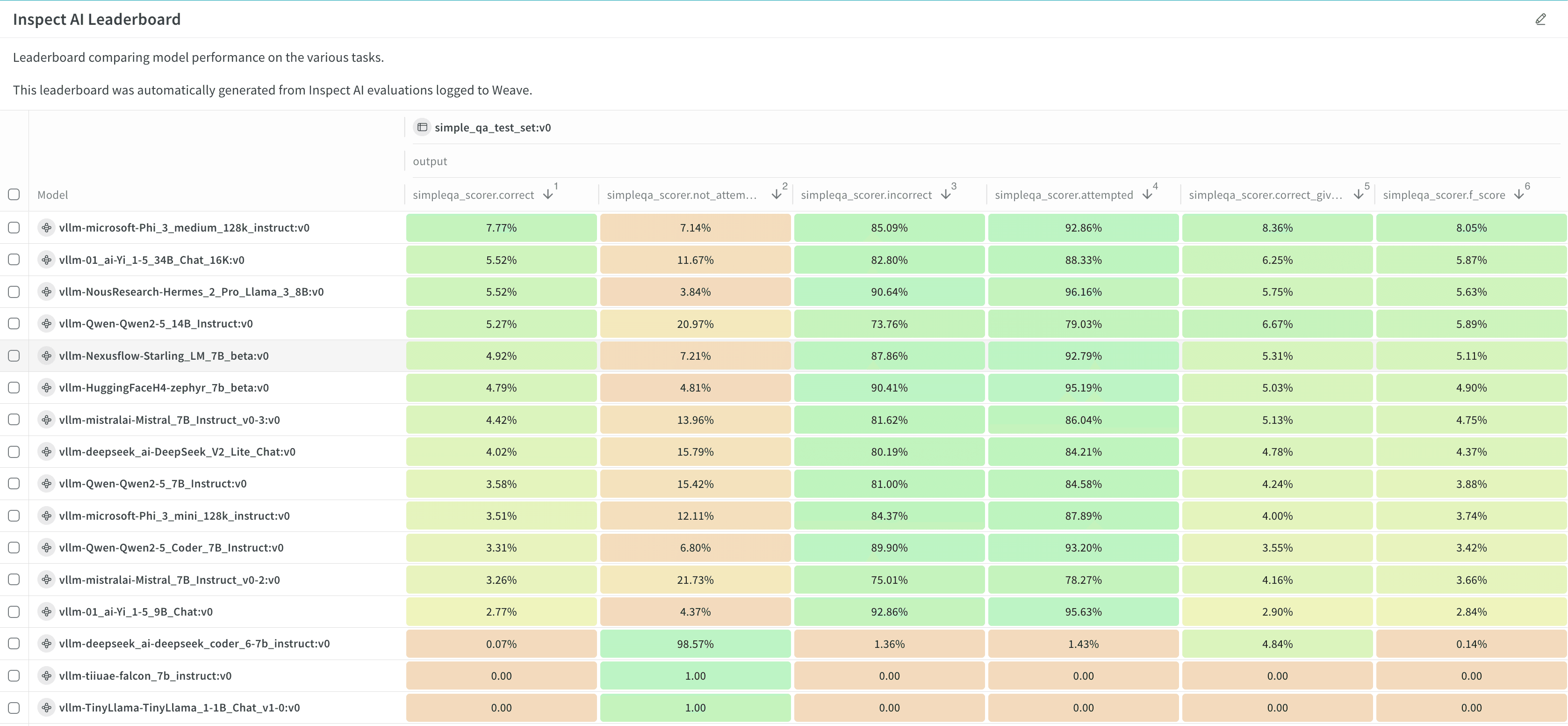
次のステップ
詳細
料金
ジョブの制限
- 評価対象のモデルの最大サイズは、コンテキストを含めて 86 GB です。
- 各ジョブで使用できる GPU は最大 2 基までです。
要件
- モデルチェックポイントを評価するには、モデルの重みを VLLM 互換のアーティファクトとしてパッケージ化する必要があります。詳細とコード例については、Example: Prepare a model を参照してください。
- OpenAI 互換のモデルを評価するには、そのモデルがパブリック URL からアクセス可能であり、かつ組織またはチームの管理者が認証用の APIキー を含むチームシークレットを設定する必要があります。
- 一部のベンチマークはスコアリングに OpenAI モデルを使用します。これらのベンチマークを実行するには、組織またはチームの管理者が必要な APIキー を含むチームシークレットを設定する必要があります。ベンチマークにこの要件があるかどうかを確認するには、Evaluation benchmark catalog を参照してください。
- 一部のベンチマークでは、Hugging Face のアクセス制限付き(gated)データセットへのアクセスが必要です。これらのベンチマークのいずれかを実行するには、組織またはチームの管理者が Hugging Face 上のアクセス制限付きデータセットへのアクセスをリクエストし、Hugging Face ユーザーアクセストークンを生成し、それをチームシークレットとして設定する必要があります。ベンチマークにこの要件があるかどうかを確認するには、Evaluation benchmark catalog を参照してください。