このノートブックで扱う内容
インストール・インポート・ログイン
ステップ 0: W&B をインストールする
wandb は pip を使って簡単にインストールできます。
Step 1: W&B をインポートしてログインする
実験とパイプラインの定義
wandb.init を使ってメタデータとハイパーパラメータを追跡する
config 辞書(または類似のオブジェクト)に保存し、
必要に応じてそこから参照する、というワークフローはとても一般的です。
この例では、一部のハイパーパラメータだけを変化させ、
残りはコードに手書きで埋め込んでいます。
ただし、モデルの任意の部分を config に含めることができます。
また、いくつかメタデータも含めています。ここでは MNIST データセットと
畳み込みアーキテクチャを使用しています。あとで同じプロジェクト内で、
例えば CIFAR 上の全結合アーキテクチャを扱う場合、
これによって run を区別しやすくなります。
- まず
makeでモデルと、それに関連するデータやオプティマイザを作成し、 - 次にそのモデルを
trainで学習させ、 - 最後に、学習がどう進んだかを確認するために
testします。
wandb.init のコンテキスト内で実行されるということだけです。
この関数を呼び出すと、あなたのコードと当社サーバーとの
通信経路が確立されます。
config 辞書を wandb.init に渡すと、
その情報はすぐにログとして当社に送信されます。
これにより、実験でどのハイパーパラメータ値を
設定したかを常に把握できます。
選択してログした値が、常にあなたのモデルで実際に使われる値になるようにするには、
オブジェクトの run.config のコピーを使うことを推奨しています。
以下の make の定義を確認して、いくつかの例を見てください。
補足: 当社のコードは別プロセスで実行されるよう注意して設計しているため、
当社側で問題が発生しても
(巨大な海の怪物がデータセンターを襲うような事態が起きたとしても)
あなたのコードがクラッシュすることはありません。
問題が解消されたら(たとえばクラーケンが深海に戻ったら)、
wandb sync を使ってデータをログできます。
データの読み込みとモデルを定義する
wandb を使わない場合とまったく同じなので、ここでは詳しくは触れません。
wandb を使うからといってそこは変わりません。
ここでは標準的な ConvNet アーキテクチャを使うことにします。
遠慮せずにいろいろいじって実験してみてください —
すべての結果は wandb.ai に記録されます。
学習ロジックを定義する
model_pipeline の次のステップとして、ここではどのように train するかを指定します。
ここでは 2 つの wandb 関数である watch と log を使用します。
run.watch() で勾配をトラッキングし、その他は run.log() で記録する
run.watch は、学習の log_freq ステップごとに、
モデルの勾配とパラメータをログに記録します。
学習を開始する前にこれを呼び出すだけでかまいません。
それ以外の学習コードはそのままです:
エポックとバッチを反復しながら、
forward / backward パスを実行し、
optimizer を適用します。
run.log() に渡します。
run.log() はキーとして文字列を持つ辞書を受け取ります。
これらの文字列でログされるオブジェクトを識別し、そのオブジェクトが値になります。
またオプションとして、今どの step の学習中かをログすることもできます。
補足: 私は、モデルがこれまでに見たサンプル数を使うのが好きです。
こうするとバッチサイズが異なる場合でも比較しやすくなるからです。
ただし、生のステップ数やバッチ数を使ってもかまいません。学習 run が長くなる場合には、エポック ごとにログを取るのも理にかなっています。
テストロジックを定義する
(オプション)run.save() を呼び出す
export します。
そのファイル名を run.save() に渡すことで、モデルのパラメータが W&B のサーバーに保存されるようになります。どの .h5 や .pb
がどの学習 run に対応しているのか分からなくなることは、もうありません。
モデルの保存、バージョン管理、配布のための、より高度な wandb の機能については、Artifacts tools を参照してください。
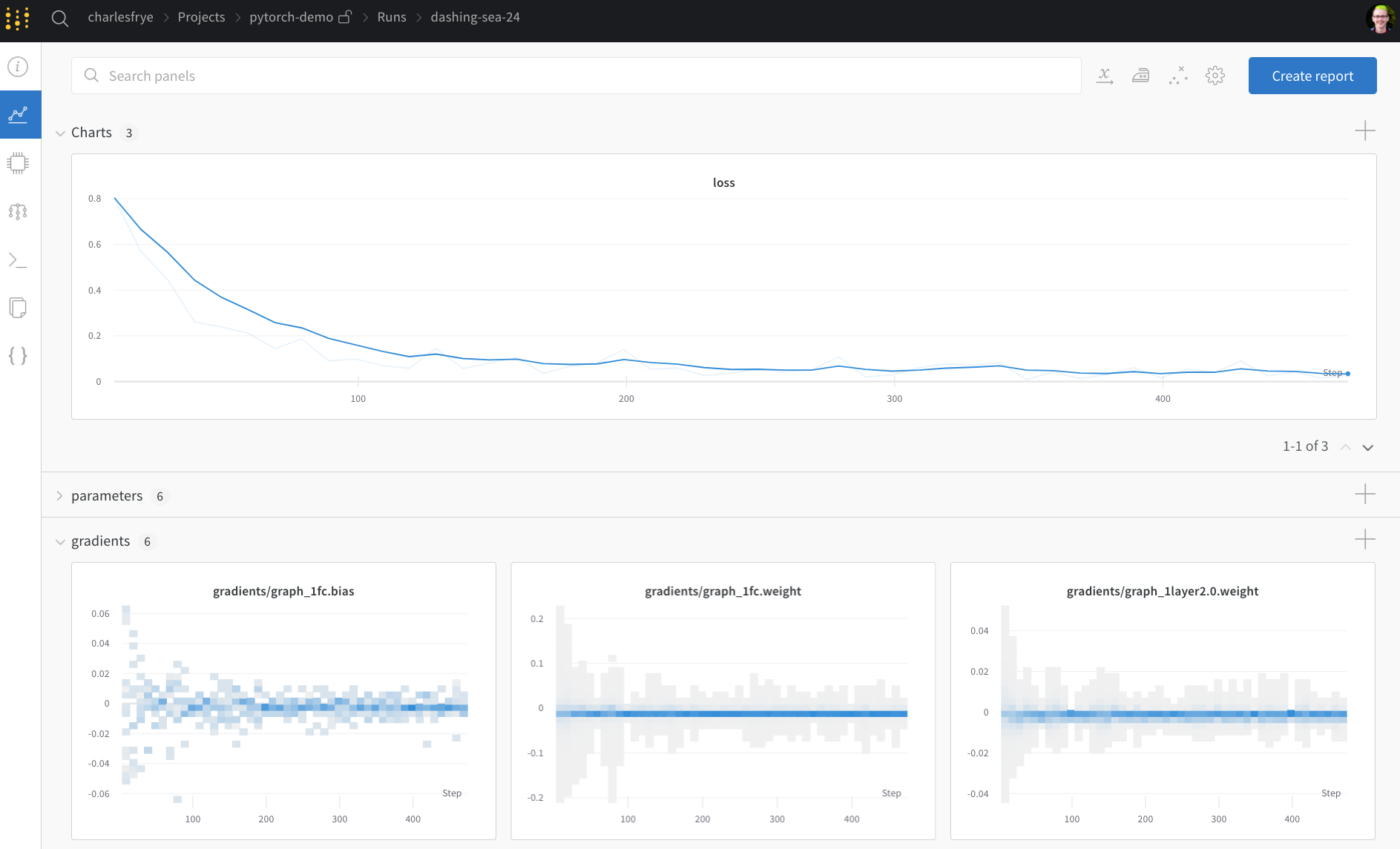
学習を実行して、wandb.ai 上でメトリクスをリアルタイムに確認する
- Charts: 学習全体を通して、モデルの勾配、パラメータ値、損失がログされます
- System: Disk I/O 使用率、CPU と GPU のメトリクス(温度の上昇に注意)など、さまざまなシステムメトリクスが含まれます
- Logs: 学習中に標準出力へ出力された内容のコピーが含まれます
- Files: 学習が完了すると、
model.onnxをクリックして Netron model viewer でネットワークを表示できます。
with wandb.init ブロックを抜けると、
セル出力に結果のサマリーも表示されます。
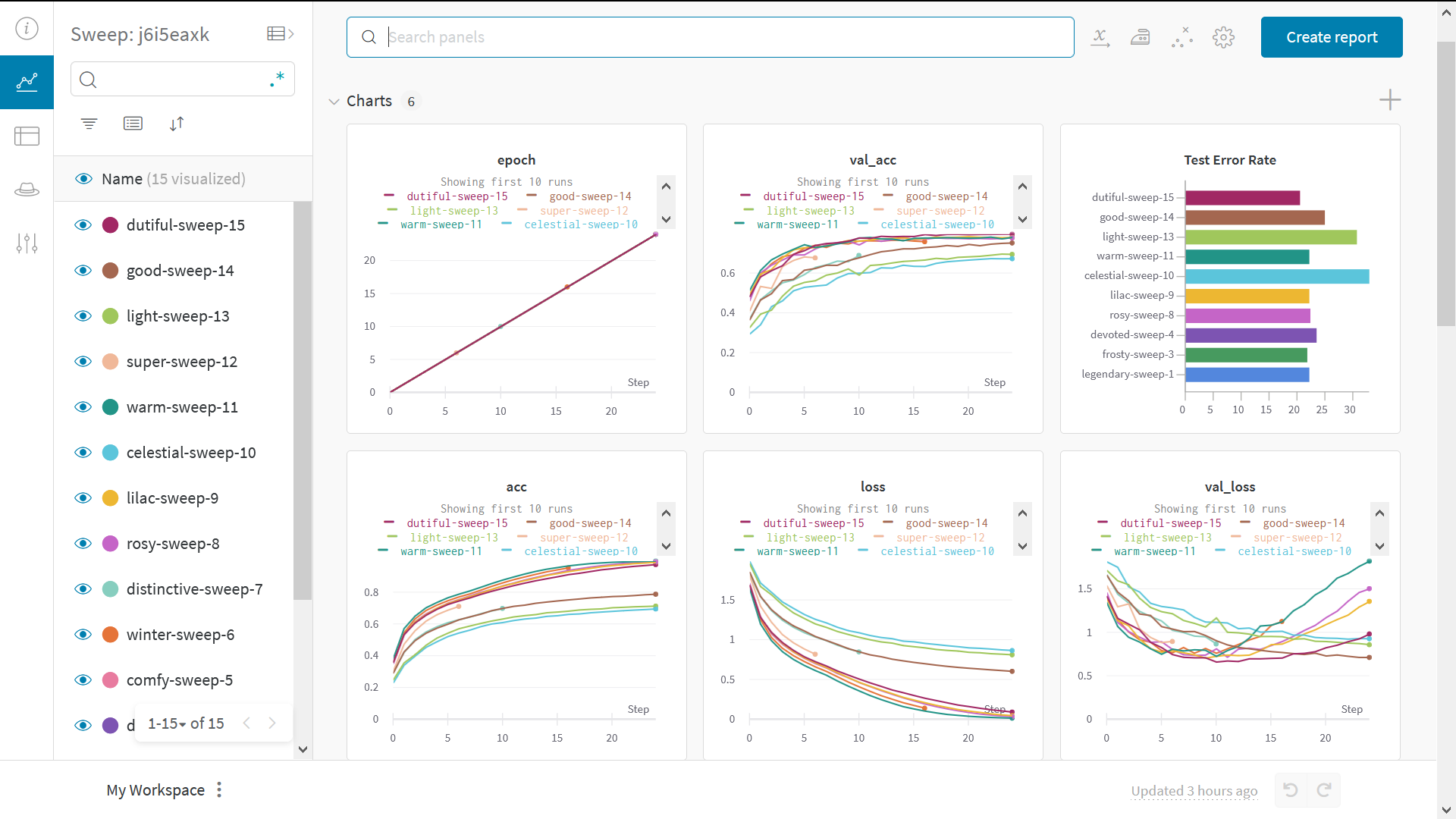
Sweeps を使ってハイパーパラメータをテストする
- スイープを定義する: 検索するパラメータ、検索戦略、最適化指標などを指定する辞書または YAML ファイル を作成します。
-
スイープを初期化する:
sweep_id = wandb.sweep(sweep_config) -
スイープエージェントを実行する:
wandb.agent(sweep_id, function=train)