たった2行で高度なロギングを実現
はじめに
-
diffusers、transformers、accelerate、wandbをインストールします。-
コマンドライン:
-
ノートブック:
-
コマンドライン:
-
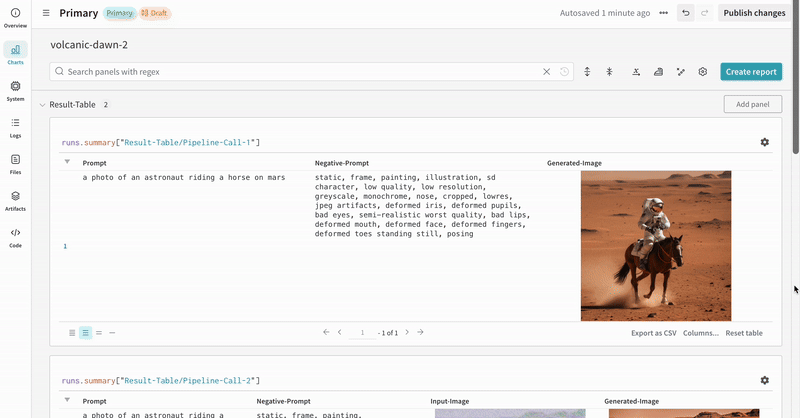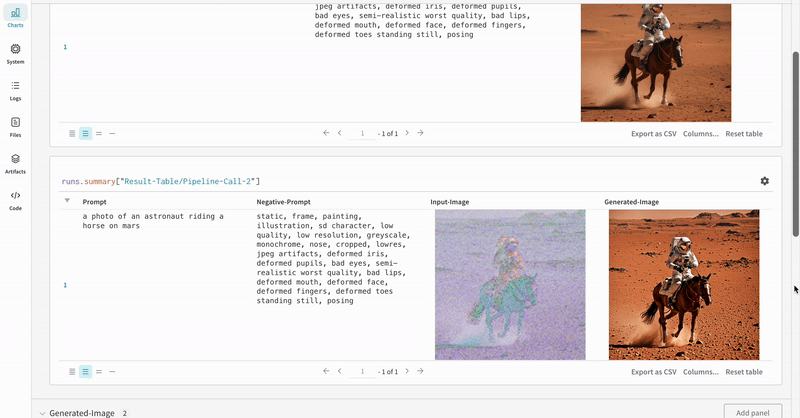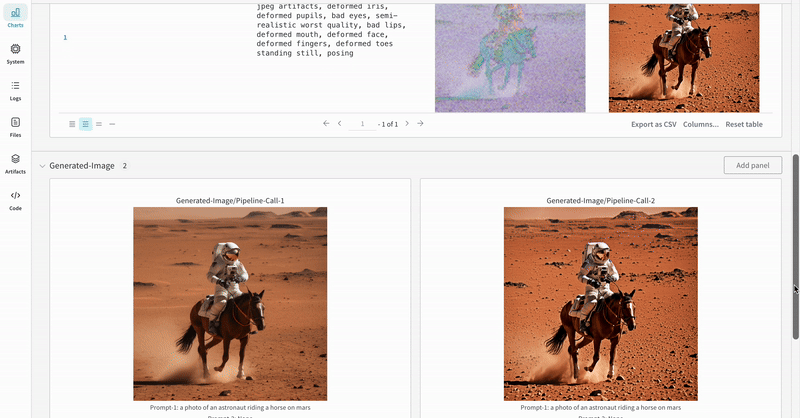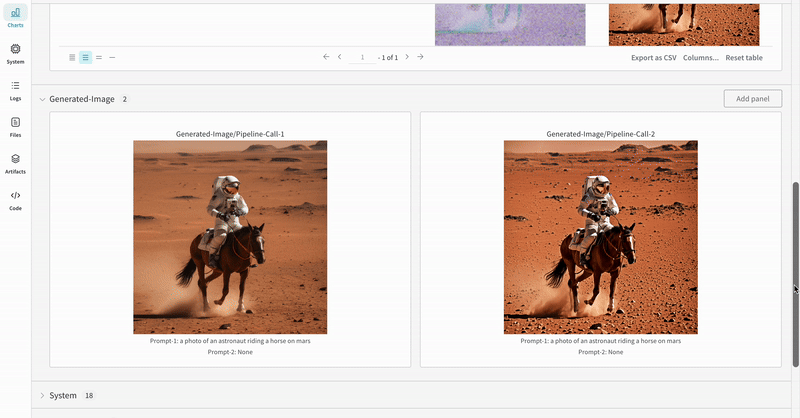
autologを使用して W&B の run を初期化し、サポートされているすべてのパイプライン呼び出しの入力と出力を自動で追跡します。autolog()関数はinitパラメータ付きで呼び出すことができます。initには、wandb.init()に必要なパラメータの辞書を渡します。autolog()を呼び出すと、W&B の run が初期化され、サポートされているすべてのパイプライン呼び出しの入力と出力が自動で追跡されます。- 各パイプライン呼び出しはワークスペース内の専用の table に記録され、そのパイプライン呼び出しに関連付けられた config は、その run の config 内の workflow リストに追加されます。
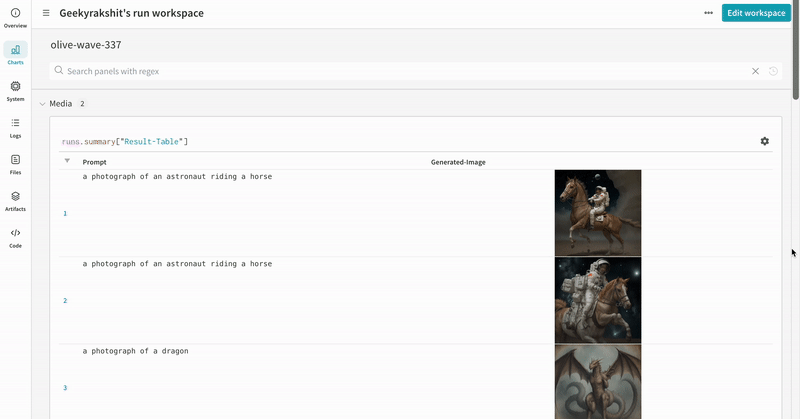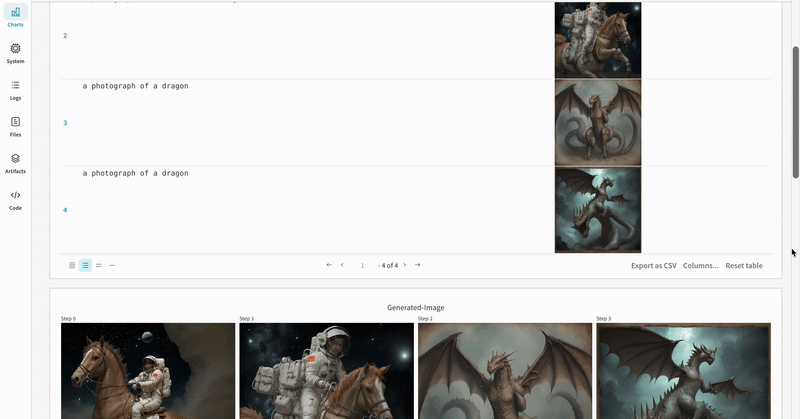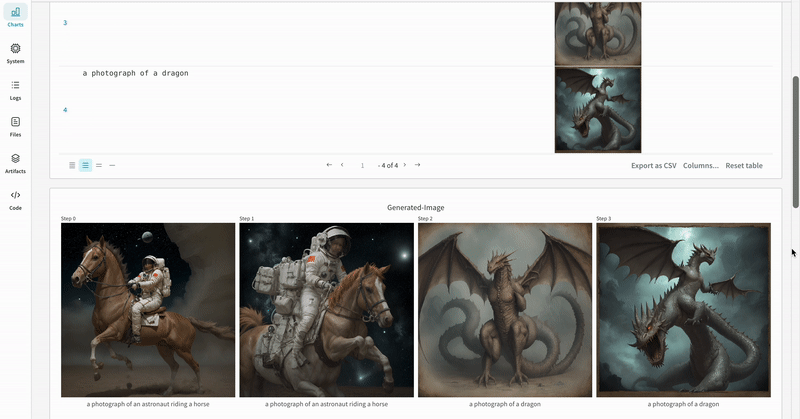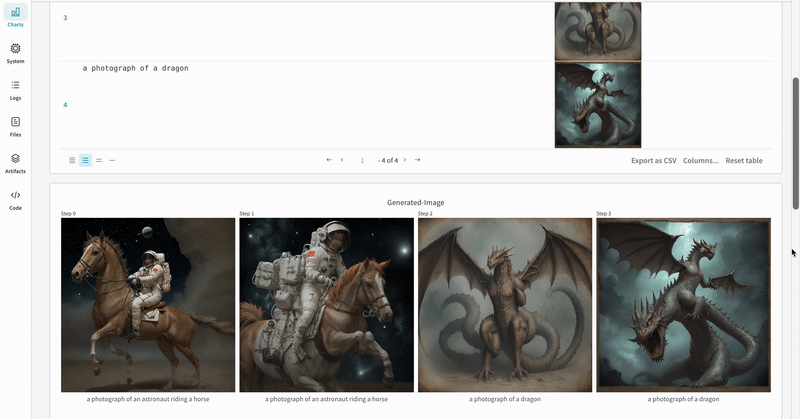
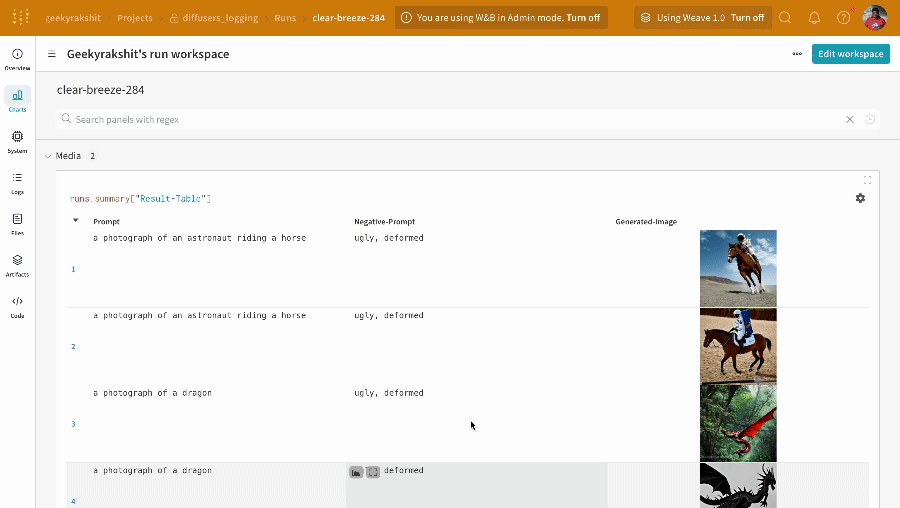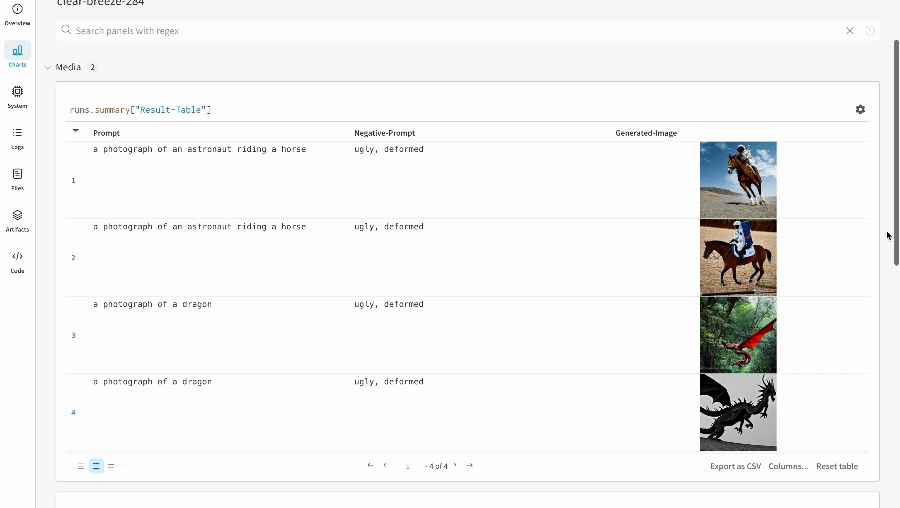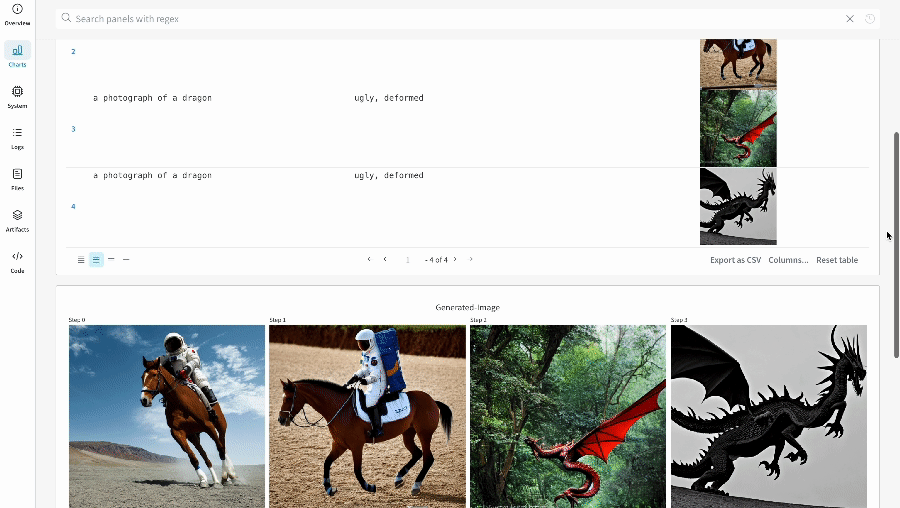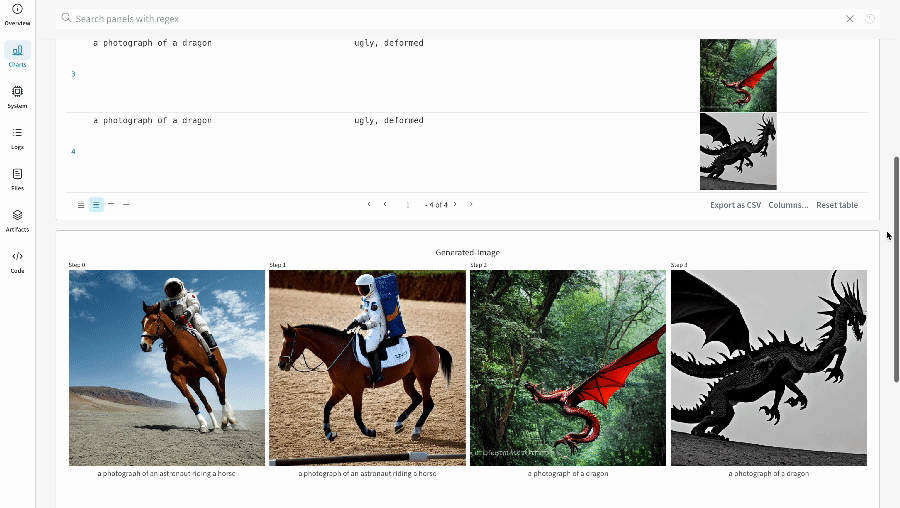
- プロンプト、ネガティブプロンプト、および生成されたメディアは
wandb.Tableにログされます。 - seed やパイプラインアーキテクチャなど、実験に関連するその他すべての config は、その run の config セクションに保存されます。
- 各パイプライン呼び出しで生成されたメディアは、その run の media panels にもログされます。
サポートされているパイプライン呼び出しの一覧を確認できます。このインテグレーションに新機能をリクエストしたい場合や、関連するバグを報告したい場合は、W&B GitHub issues ページで issue を作成してください。
使用例
自動ロギング
- スクリプト
- ノートブック
-
単一の実験結果:
-
複数の実験結果:
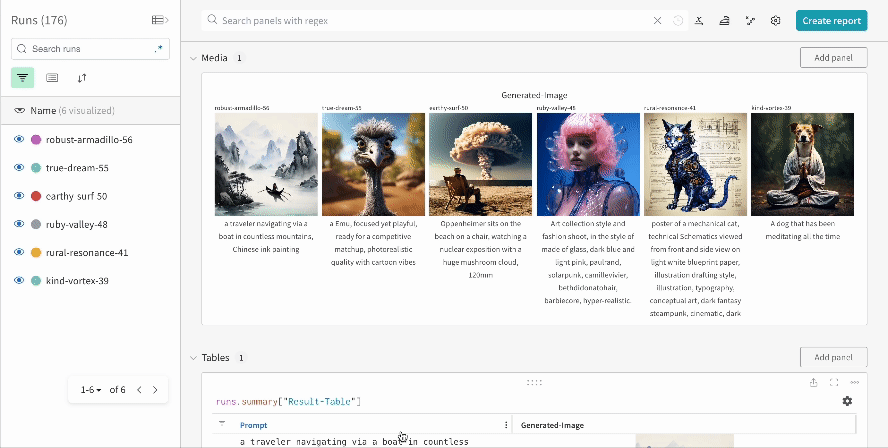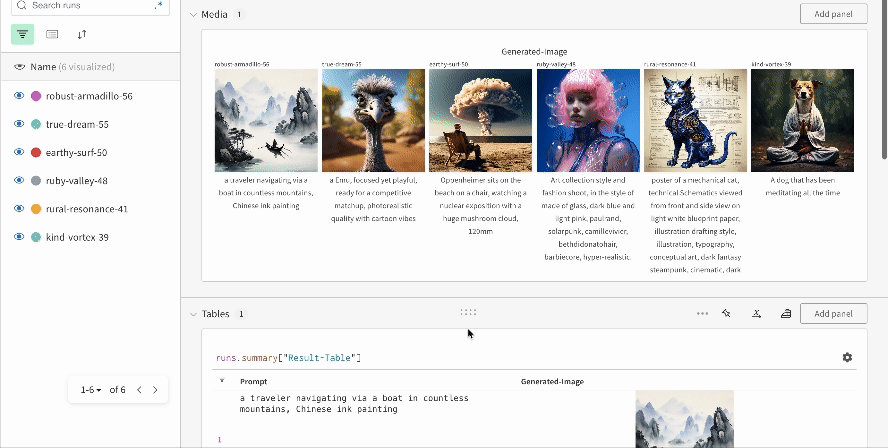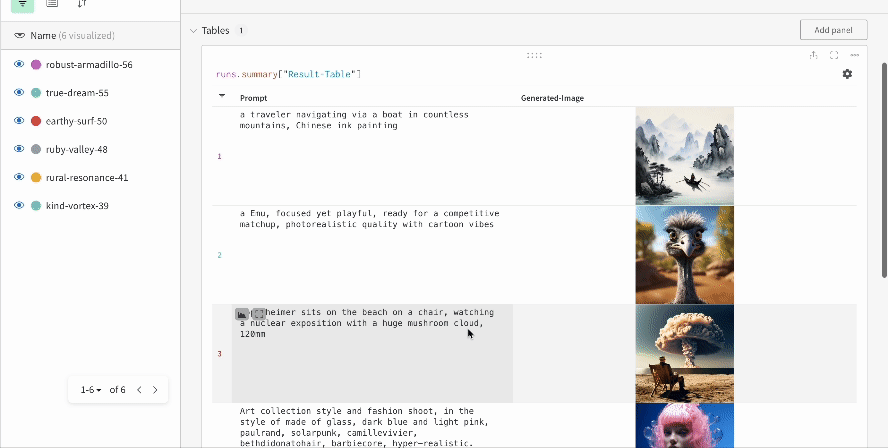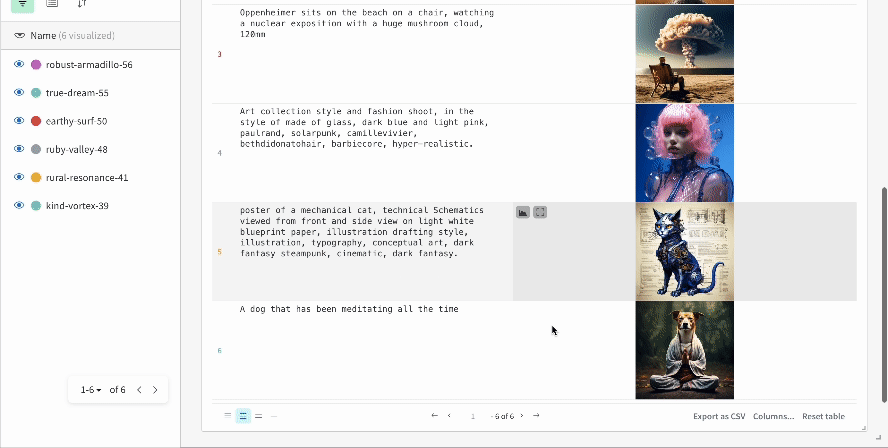
-
実験の設定:
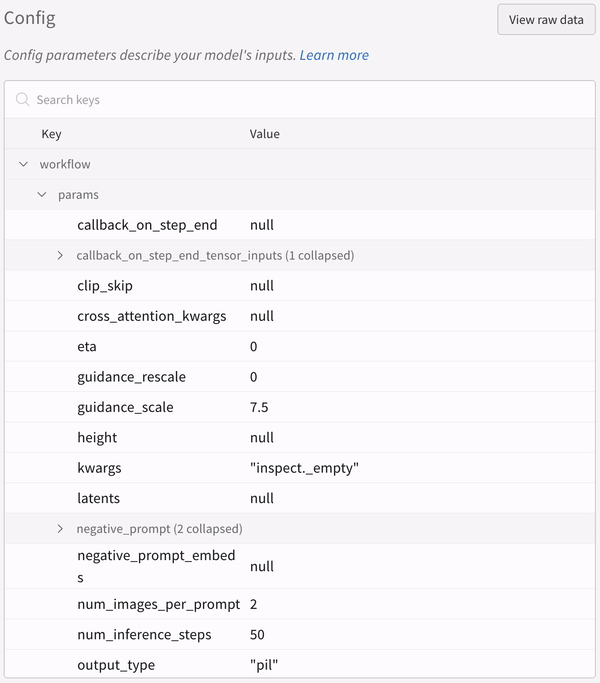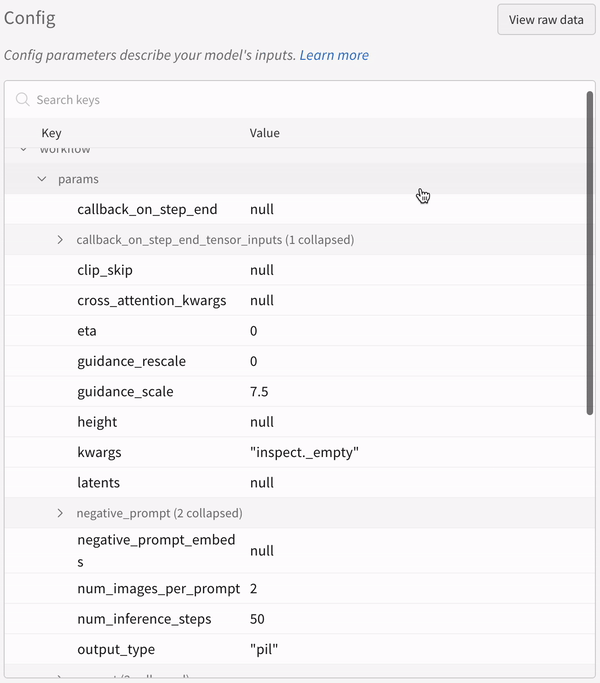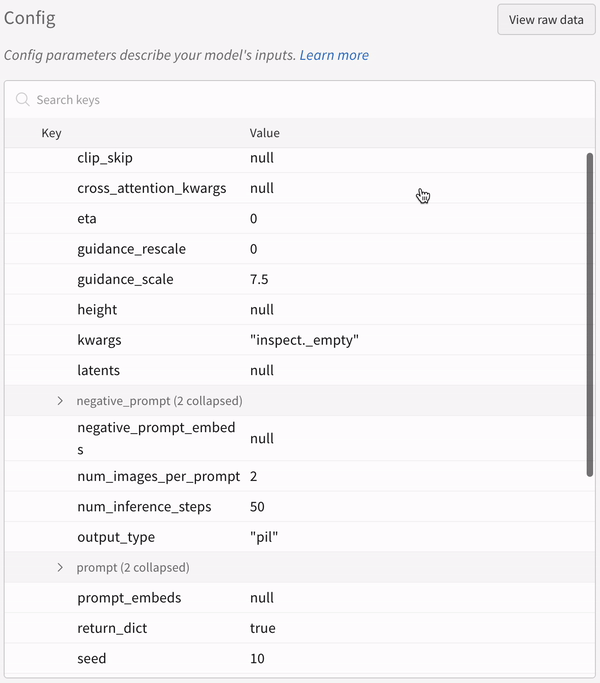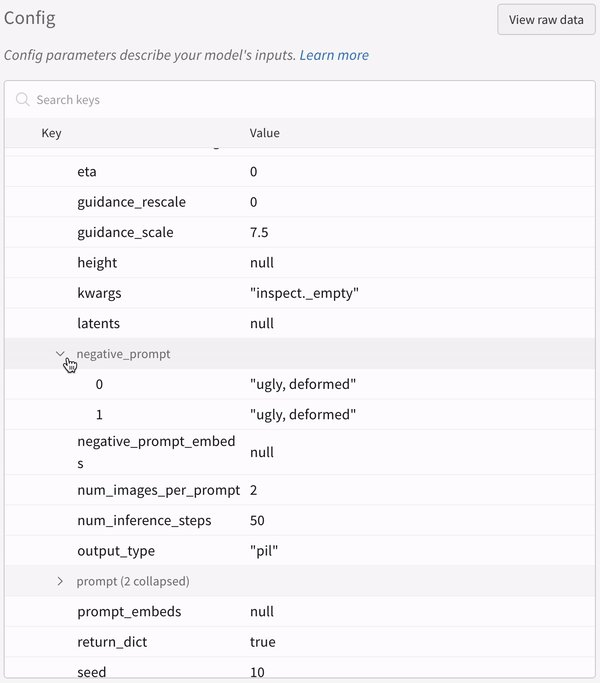
IPython notebook 環境で pipeline を呼び出す場合は、その後に明示的に
wandb.Run.finish() を呼び出す必要があります。python スクリプトを実行する場合は、この呼び出しは不要です。複数パイプライン ワークフローのトラッキング
StableDiffusionXLPipeline によって生成された潜在表現が、対応する refiner によって精緻化されます。
- Python スクリプト
- ノートブック
- Stable Diffusion XL + Refiner を用いた実験例: