Colab で試す
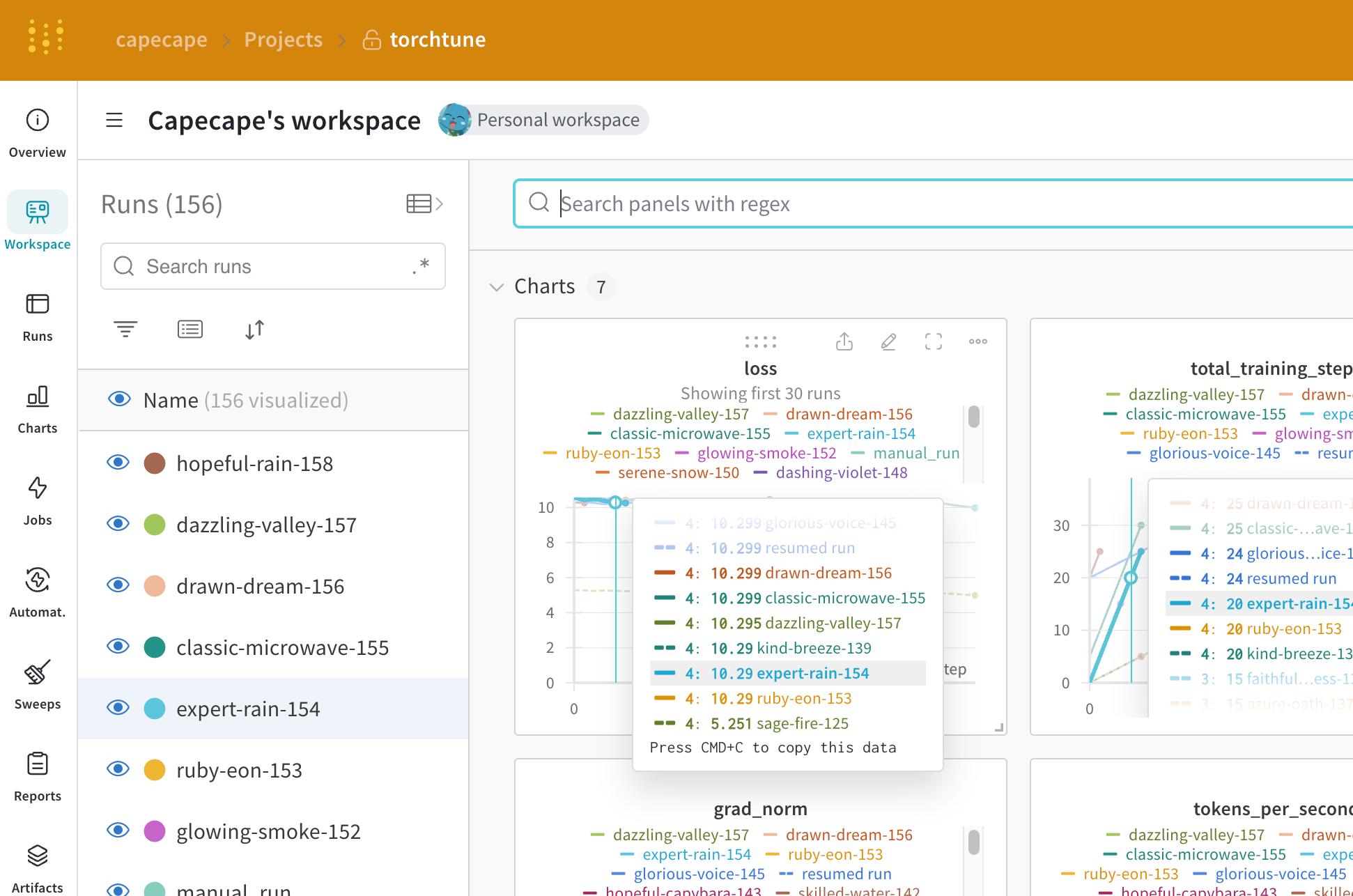
torchtune は、大規模言語モデル (LLM) の作成、ファインチューニング、および実験プロセスを効率化するように設計された PyTorch ベースのライブラリです。さらに torchtune には、W&B でのロギング のサポートが組み込まれており、学習プロセスの追跡と可視化を強化します。
torchtune を使った Mistral 7B のファインチューニング については、W&B のブログ記事を参照してください。
実行時にコマンドライン引数を指定して上書きします:tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
log_every_n_steps=5
レシピの設定で W&B ロギングを有効にします:# llama3/8B_lora_single_device.yaml 内
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
log_every_n_steps: 5
metric_logger セクションを変更して、W&B へのロギングを有効化します。_component_ を torchtune.utils.metric_logging.WandBLogger クラスに変更します。project 名や log_every_n_steps を指定して、ロギングの動作をカスタマイズすることもできます。
wandb.init() メソッドに渡す場合と同様に、他の任意の kwargs も渡すことができます。たとえば、チームで作業している場合は、チーム名を指定するために entity 引数を WandBLogger クラスに渡すことができます。
# llama3/8B_lora_single_device.yaml 内
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
entity: my_project
job_type: lora_finetune_single_device
group: my_awesome_experiments
log_every_n_steps: 5
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
metric_logger.entity="my_project" \
metric_logger.job_type="lora_finetune_single_device" \
metric_logger.group="my_awesome_experiments" \
log_every_n_steps=5
| Metric | Description |
|---|
loss | モデルの損失 |
lr | 学習率 |
tokens_per_second | モデルの 1 秒あたりのトークン数 |
grad_norm | モデルの勾配ノルム |
global_step | 学習ループにおける現在のステップに対応します。勾配の蓄積を考慮しており、基本的にはオプティマイザのステップが 1 回行われるたびに勾配が蓄積され、gradient_accumulation_steps 回ごとにモデルが 1 回更新されます。 |
global_step は学習ステップ数そのものとは異なります。学習ループにおける現在のステップに対応します。勾配の蓄積を考慮しており、基本的にはオプティマイザのステップが 1 回行われるたびに global_step が 1 ずつ増加します。例えば、dataloader から 10 バッチ取得でき、勾配蓄積ステップ数が 2 で、3 エポック実行した場合、オプティマイザは 15 回ステップを実行し、この場合 global_step の値は 1 から 15 までとなります。
current_epoch を総エポック数に対するパーセンテージとして計算し、次のように記録できます:
# レシピファイル内の `train.py` 関数内
self._metric_logger.log_dict(
{"current_epoch": self.epochs * self.global_step / self._steps_per_epoch},
step=self.global_step,
)
このライブラリは高速に進化しており、現状のメトリクスは今後変更される可能性があります。カスタムメトリクスを追加したい場合は、レシピを変更し、対応する self._metric_logger.* 関数を呼び出してください。
save_checkpoint 関数をオーバーライドすることです。
以下は、save_checkpoint 関数をオーバーライドして、モデルのチェックポイントを W&B Artifacts に保存する方法の例です。
def save_checkpoint(self, epoch: int) -> None:
...
## チェックポイントをW&Bに保存する
## Checkpointerクラスによってファイル名が異なる
## full_finetuneの場合の例
checkpoint_file = Path.joinpath(
self._checkpointer._output_dir, f"torchtune_model_{epoch}"
).with_suffix(".pt")
wandb_artifact = wandb.Artifact(
name=f"torchtune_model_{epoch}",
type="model",
# モデルチェックポイントの説明
description="Model checkpoint",
# 任意のメタデータをdictとして追加できる
metadata={
utils.SEED_KEY: self.seed,
utils.EPOCHS_KEY: self.epochs_run,
utils.TOTAL_EPOCHS_KEY: self.total_epochs,
utils.MAX_STEPS_KEY: self.max_steps_per_epoch,
},
)
wandb_artifact.add_file(checkpoint_file)
wandb.log_artifact(wandb_artifact)