임베딩 예제
Hello World
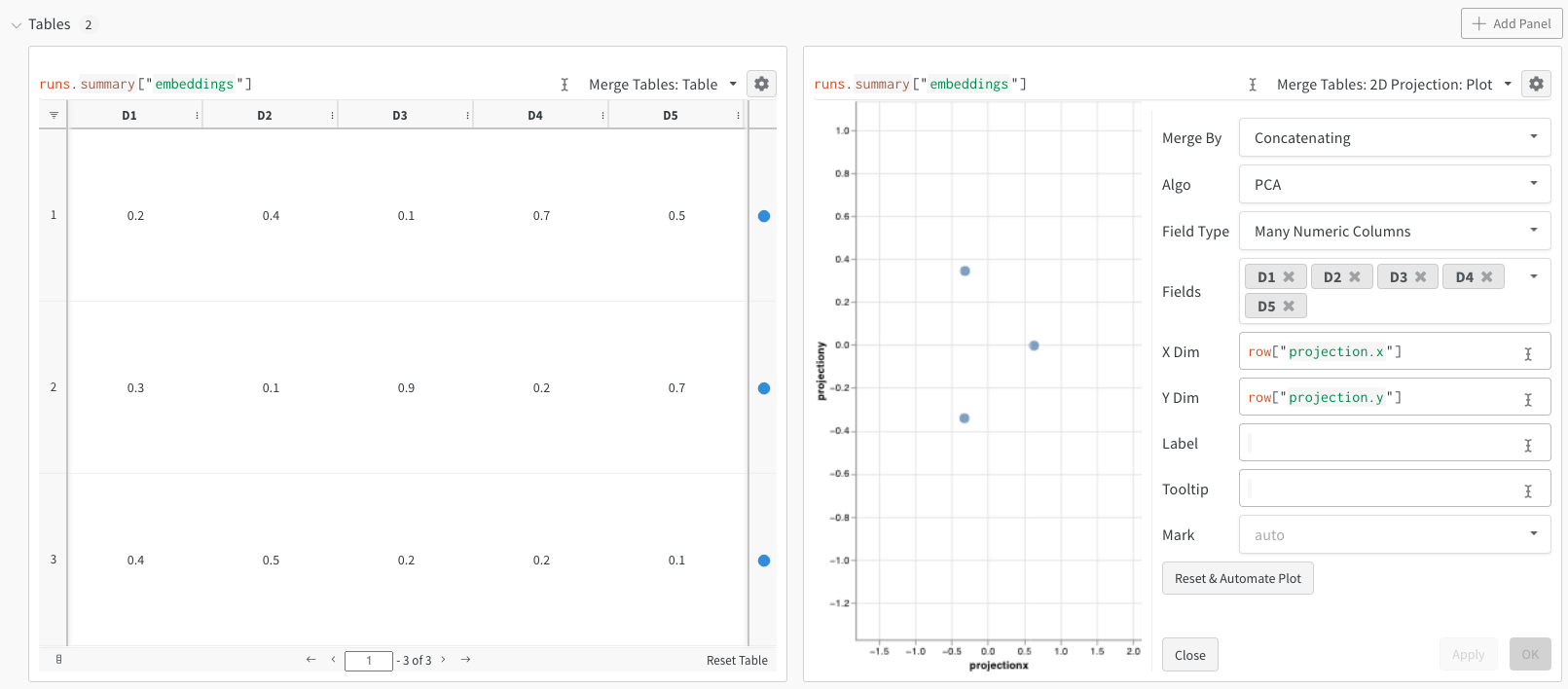
wandb.Table 클래스를 통해 임베딩을 로깅할 수 있습니다. 다음은 각 임베딩이 5차원으로 이루어진 3개의 임베딩 예시입니다:
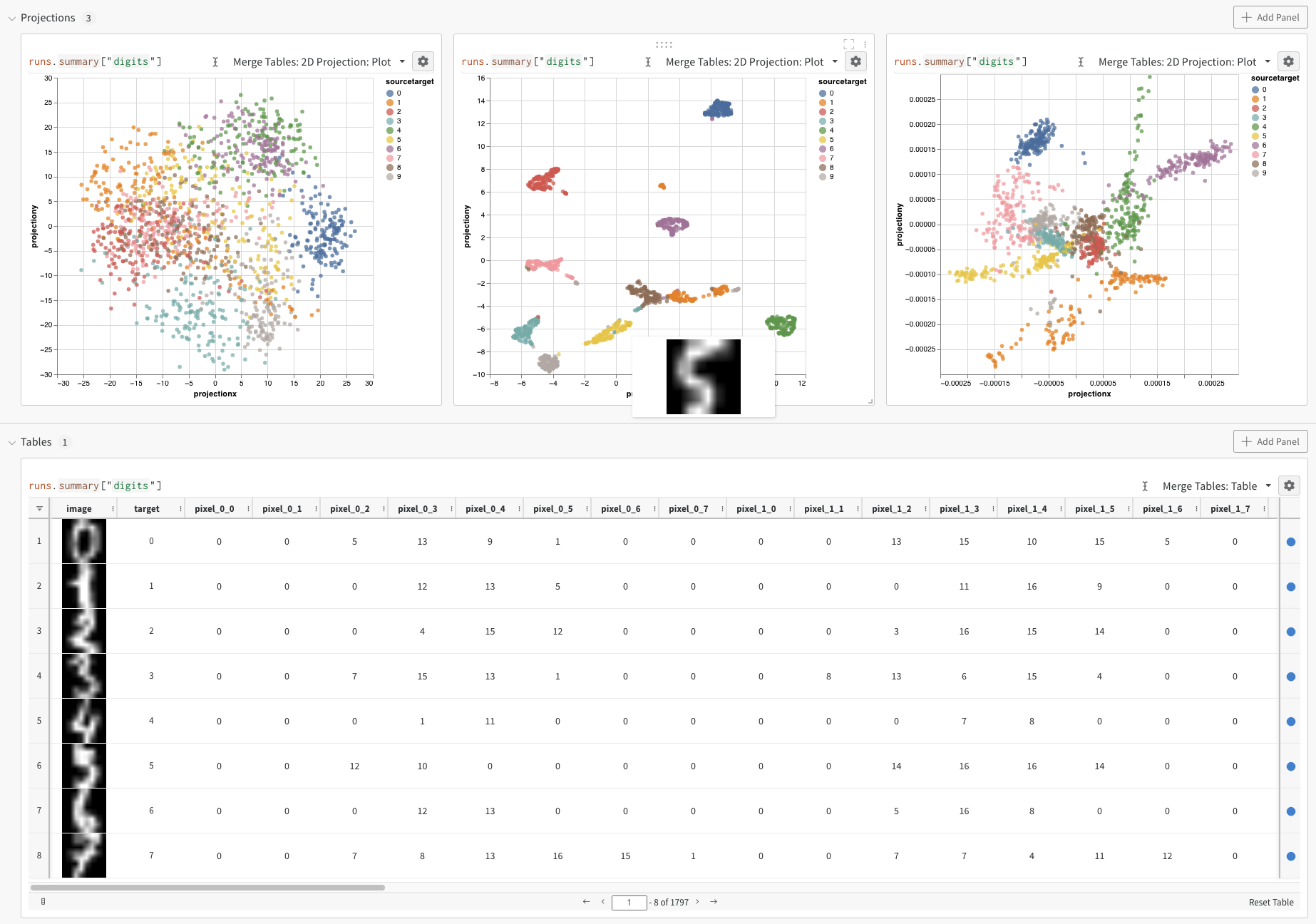
2D Projection을 선택해 임베딩을 2차원으로 시각화할 수 있습니다. Smart default가 자동으로 선택되며, 톱니바퀴 아이콘을 클릭해 열리는 설정 메뉴에서 쉽게 변경할 수 있습니다. 이 예제에서는 사용 가능한 5개의 숫자형 차원을 모두 자동으로 사용합니다.
Digits MNIST
2D Projection을 선택하면 임베딩 정의, 색상, 알고리즘(PCA, UMAP, t-SNE), 알고리즘 파라미터, 심지어 오버레이까지 설정할 수 있습니다(이 예시에서는 각 포인트에 마우스를 올렸을 때 해당 이미지를 표시). 이 예시에서는 이런 설정들이 모두 ‘스마트 기본값(smart defaults)’으로 잡혀 있어서, 2D Projection을 한 번만 클릭해도 거의 동일한 결과를 확인할 수 있습니다. (이 임베딩 튜토리얼 예제를 직접 살펴보세요).
로깅 옵션
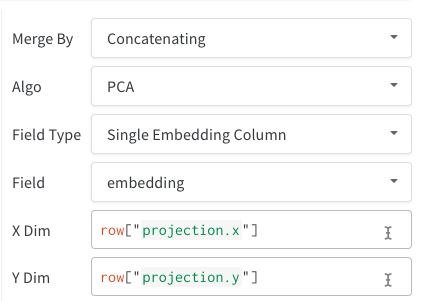
- 단일 임베딩 컬럼: 종종 데이터가 이미 “행렬”과 유사한 형식일 수 있습니다. 이 경우 단일 임베딩 컬럼을 만들 수 있으며, 셀 값의 데이터 타입은
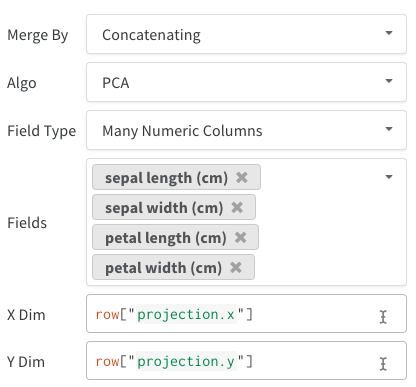
list[int],list[float], 또는np.ndarray일 수 있습니다. - 여러 개의 숫자 컬럼: 위의 두 예시에서처럼, 이 방식은 각 차원마다 하나의 컬럼을 만드는 접근 방식입니다. 현재 셀 값으로는 파이썬
int또는float타입을 허용합니다.
wandb.Table(dataframe=df)를 사용하여 데이터프레임으로부터 직접 생성wandb.Table(data=[...], columns=[...])를 사용하여 데이터 리스트로부터 직접 생성- 테이블을 행 단위로 점진적으로 빌드 (코드에 루프가 있는 경우에 유용).
table.add_data(...)를 사용해 테이블에 행 추가 - 테이블에 임베딩 컬럼 추가 (임베딩 형태의 예측 결과 리스트가 있는 경우에 유용):
table.add_col("col_name", ...) - 계산된 컬럼 추가 (테이블 전체에 적용할 함수나 모델이 있는 경우에 유용):
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
플로팅 옵션
2D Projection을 선택한 후 톱니바퀴 아이콘을 클릭해서 렌더링 설정을 수정할 수 있습니다. 위에서 설명한 대로 사용할 열을 선택하는 것 외에, 관심 있는 알고리즘(및 해당 파라미터)을 선택할 수 있습니다. 아래에서는 각각 UMAP과 t-SNE에 대한 파라미터를 확인할 수 있습니다.
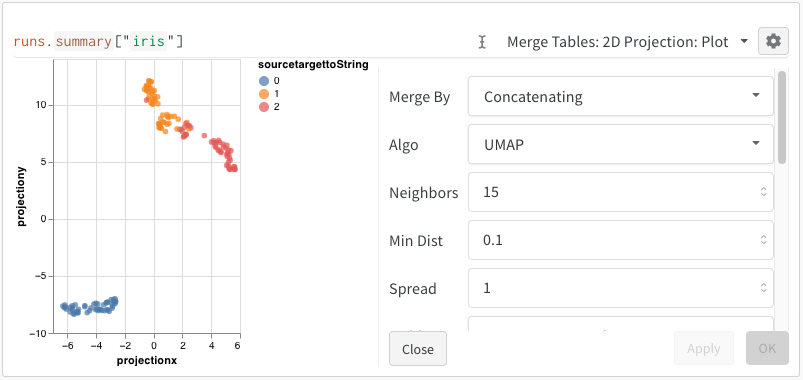
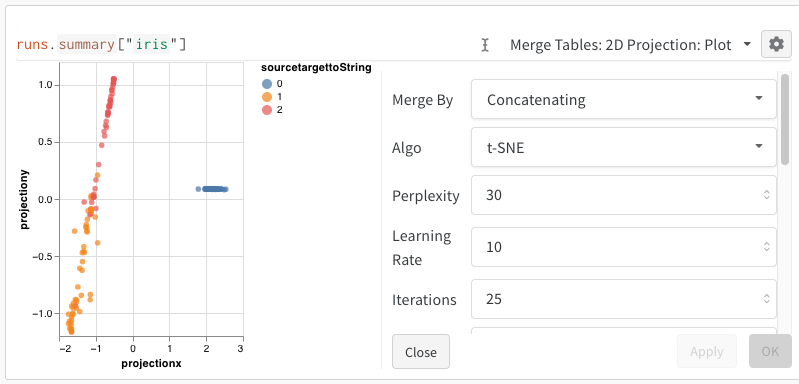
참고: 현재 세 가지 알고리즘 모두에 대해 행 1000개와 차원 50개로 이루어진 무작위 서브셋으로 다운샘플링합니다.