머신 러닝 워크플로에서 모델 아티팩트를 추적·공유·관리해야 하는 시기와 방법을 알아보세요. 이 페이지에서는 트레이닝 중 실험을 로깅하고 리포트를 생성하며, 각 작업에 적합한 W&B API를 사용해 로깅된 데이터에 접근하는 방법을 다룹니다.
이 튜토리얼에서는 다음을 사용합니다:
머신을 W&B에 인증하려면 먼저 wandb.ai/settings에서 API 키를 생성해야 합니다. 생성한 API 키를 복사해 안전한 위치에 보관하세요.
이 튜토리얼에서 사용할 W&B 라이브러리와 기타 패키지를 설치합니다.
W&B Python SDK를 임포트하세요:
다음 코드 블록에서 팀 엔티티를 지정하세요:
TEAM_ENTITY = "<Team_Entity>" # 팀 엔티티를 입력하세요
PROJECT = "my-awesome-project"
wandb.sdk)를 사용하세요. wandb.Run.log()으로 loss를 로깅한 다음, wandb.Artifact로 학습된 모델을 아티팩트로 저장한 뒤, 마지막으로 Artifact.add_file을 사용해 모델 파일을 추가합니다.
import random # 데이터 시뮬레이션용
def model(training_data: int) -> int:
"""데모 목적의 모델 시뮬레이션."""
return training_data * 2 + random.randint(-1, 1)
# 가중치 및 노이즈 시뮬레이션
weights = random.random() # 랜덤 가중치 초기화
noise = random.random() / 5 # 노이즈 시뮬레이션을 위한 소규모 랜덤 노이즈
# 하이퍼파라미터 및 설정
config = {
"epochs": 10, # 트레이닝할 에포크 수
"learning_rate": 0.01, # 옵티마이저의 학습률
}
# 컨텍스트 매니저를 사용하여 W&B run 초기화 및 종료
with wandb.init(project=PROJECT, entity=TEAM_ENTITY, config=config) as run:
# 트레이닝 루프 시뮬레이션
for epoch in range(config["epochs"]):
xb = weights + noise # 시뮬레이션된 입력 트레이닝 데이터
yb = weights + noise * 2 # 시뮬레이션된 목표 출력 (입력 노이즈의 두 배)
y_pred = model(xb) # 모델 예측
loss = (yb - y_pred) ** 2 # 평균 제곱 오차 손실
print(f"epoch={epoch}, loss={loss}")
# 에포크 및 손실을 W&B에 기록
run.log({
"epoch": epoch,
"loss": loss,
})
# 모델 아티팩트의 고유 이름,
model_artifact_name = f"model-demo"
# 시뮬레이션된 모델 파일을 저장할 로컬 경로
PATH = "model.txt"
# 모델을 로컬에 저장
with open(PATH, "w") as f:
f.write(str(weights)) # 모델 가중치를 파일에 저장
# 아티팩트 객체 생성
# 로컬에 저장된 모델을 아티팩트 객체에 추가
artifact = wandb.Artifact(name=model_artifact_name, type="model", description="My trained model")
artifact.add_file(local_path=PATH)
artifact.save()
- 트레이닝 중에 메트릭을 로깅하려면
wandb.Run.log()를 사용합니다.
- 모델(데이터셋 등)을 아티팩트로 저장하여 W&B 프로젝트에 저장하려면
wandb.Artifact를 사용합니다.
이제 모델을 트레이닝하고 아티팩트로 저장했으므로, 이를 W&B의 레지스트리에 게시할 수 있습니다. wandb.Run.use_artifact()를 사용하여 프로젝트에서 아티팩트를 가져오고 Model 레지스트리에 게시할 준비를 합니다. wandb.Run.use_artifact()는 두 가지 핵심 역할을 합니다.
https://wandb.ai/login 에서 계정에 로그인합니다.
Projects 아래에서 my-awesome-project(또는 위에서 프로젝트 이름으로 사용한 값)을 볼 수 있습니다. 이를 클릭하여 해당 프로젝트의 워크스페이스로 들어갑니다.
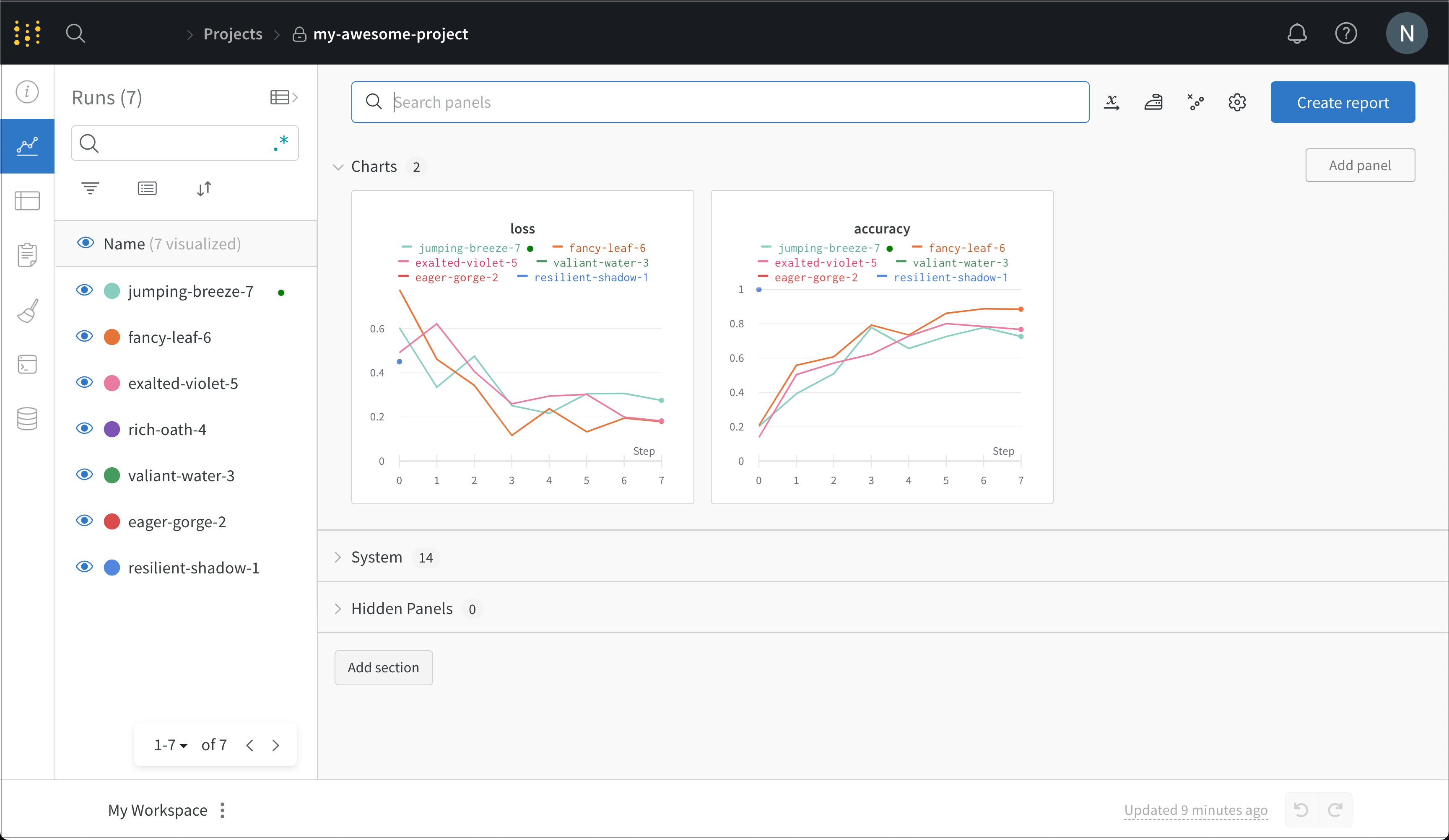
여기에서 지금까지 수행한 모든 run의 세부 정보를 확인할 수 있습니다. 이 스크린샷에서는 코드를 여러 번 다시 실행하여 여러 개의 run이 생성되었고, 각 run에는 무작위로 생성된 이름이 부여되어 있습니다.
조직 내 다른 사람들과 모델을 공유하려면 wandb.Run.link_artifact()을 사용하여 collection에 등록하세요. 다음 코드는 아티팩트를 registry에 연결하여 팀이 사용할 수 있도록 합니다.
# 아티팩트 이름은 팀 프로젝트 내의 특정 아티팩트 버전을 지정합니다
artifact_name = f'{TEAM_ENTITY}/{PROJECT}/{model_artifact_name}:v0'
print("Artifact name: ", artifact_name)
REGISTRY_NAME = "Model" # W&B의 레지스트리 이름
COLLECTION_NAME = "DemoModels" # 레지스트리의 컬렉션 이름
# 레지스트리에서 아티팩트의 대상 경로를 생성합니다
target_path = f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}"
print("Target path: ", target_path)
with wandb.init(entity=TEAM_ENTITY, project=PROJECT) as run:
model_artifact = run.use_artifact(artifact_or_name=artifact_name, type="model")
run.link_artifact(artifact=model_artifact, target_path=target_path)
wandb.Run.link_artifact()를 실행하면 모델 아티팩트가 레지스트리의 DemoModels 컬렉션에 등록됩니다. 여기에서 버전 이력, lineage map, 기타 metadata 등의 세부 정보를 확인할 수 있습니다.
레지스트리에 아티팩트를 연결하는 방법에 대한 자세한 내용은 Link artifacts to a registry를 참조하세요.
레지스트리에서 모델 아티팩트를 가져와 추론에 사용하기
wandb.Run.use_artifact()를 사용하여 레지스트리에서 게시된 아티팩트를 가져옵니다. 이 메서드는 아티팩트 객체를 반환하며, 이후 wandb.Artifact.download()를 사용해 해당 아티팩트를 로컬 파일로 다운로드할 수 있습니다.
REGISTRY_NAME = "Model" # W&B에서 사용하는 레지스트리 이름
COLLECTION_NAME = "DemoModels" # 레지스트리 내 컬렉션 이름
VERSION = 0 # 가져올 아티팩트 버전
model_artifact_name = f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"
print(f"Model artifact name: {model_artifact_name}")
with wandb.init(entity=TEAM_ENTITY, project=PROJECT) as run:
registry_model = run.use_artifact(artifact_or_name=model_artifact_name)
local_model_path = registry_model.download()
W&B Report and Workspace API는 Public Preview 단계입니다.
pip install wandb wandb-workspaces -qqq
import wandb_workspaces.reports.v2 as wr
experiment_summary = """This is a summary of the experiment conducted to train a simple model using W&B."""
dataset_info = """The dataset used for training consists of synthetic data generated by a simple model."""
model_info = """The model is a simple linear regression model that predicts output based on input data with some noise."""
report = wr.Report(
project=PROJECT,
entity=TEAM_ENTITY,
title="My Awesome Model Training Report",
description=experiment_summary,
blocks= [
wr.TableOfContents(),
wr.H2("Experiment Summary"),
wr.MarkdownBlock(text=experiment_summary),
wr.H2("Dataset Information"),
wr.MarkdownBlock(text=dataset_info),
wr.H2("Model Information"),
wr.MarkdownBlock(text = model_info),
wr.PanelGrid(
panels=[
wr.LinePlot(title="Train Loss", x="Step", y=["loss"], title_x="Step", title_y="Loss")
],
),
]
)
# W&B에 리포트 저장
report.save()
import wandb
# wandb API 초기화
api = wandb.Api()
# 문자열 `model`을 포함하고
# `text-classification` 태그 또는 `latest` 별칭을 가진 모든 아티팩트 버전 검색
registry_filters = {
"name": {"$regex": "model"}
}
# 논리 $or 연산자를 사용하여 아티팩트 버전 필터링
version_filters = {
"$or": [
{"tag": "text-classification"},
{"alias": "latest"}
]
}
# 필터 조건에 일치하는 모든 아티팩트 버전의 이터러블 반환
artifacts = api.registries(filter=registry_filters).collections().versions(filter=version_filters)
# 검색된 각 아티팩트의 이름, 컬렉션, 별칭, 태그, 생성일 출력
for art in artifacts:
print(f"artifact name: {art.name}")
print(f"collection artifact belongs to: { art.collection.name}")
print(f"artifact aliases: {art.aliases}")
print(f"tags attached to artifact: {art.tags}")
print(f"artifact created at: {art.created_at}\n")