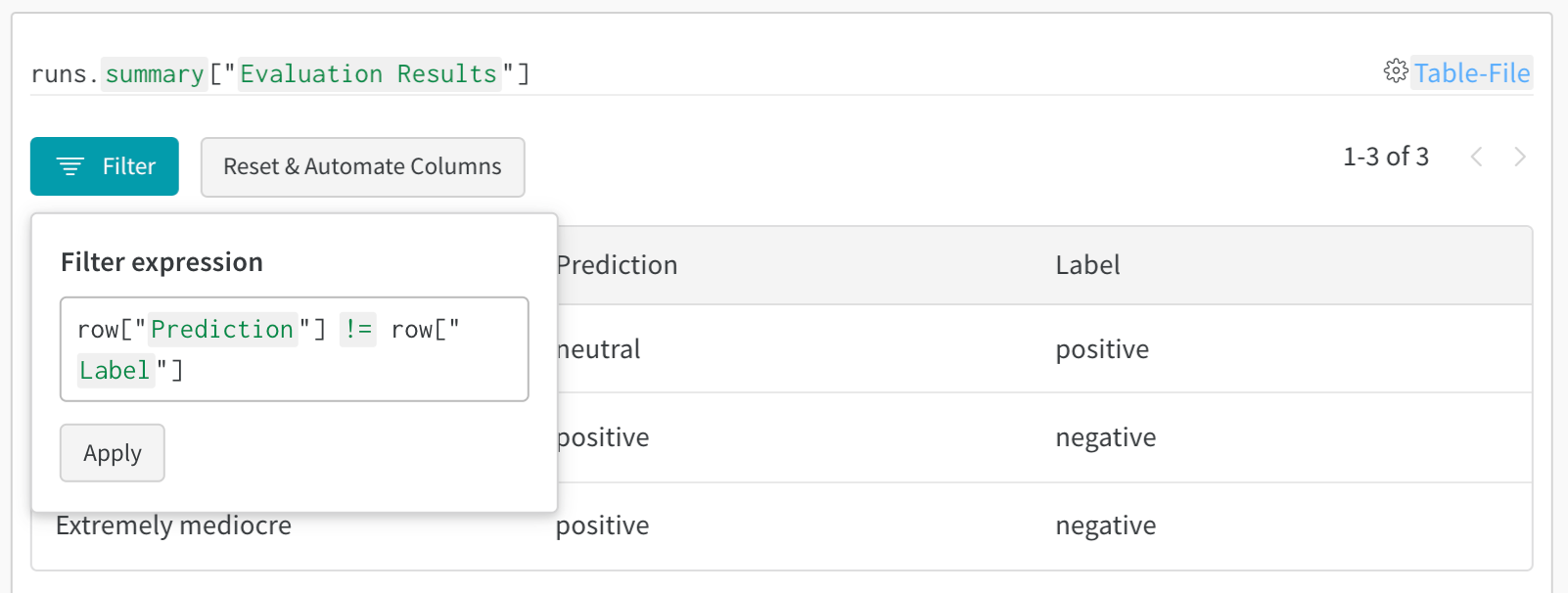
1. テーブルをログする
- テーブルを作成
- Pandas DataFrame
新しい Table を作成してログするには、次を使用します:
wandb.init(): 結果を追跡するための run を作成します。wandb.Table(): 新しいテーブルオブジェクトを作成します。columns: 列名を設定します。data: 各行の内容を設定します。
wandb.Run.log(): テーブルをログして W&B に保存します。
2. プロジェクトのワークスペースでテーブルを可視化する
- W&B App で自分のプロジェクトに移動します。
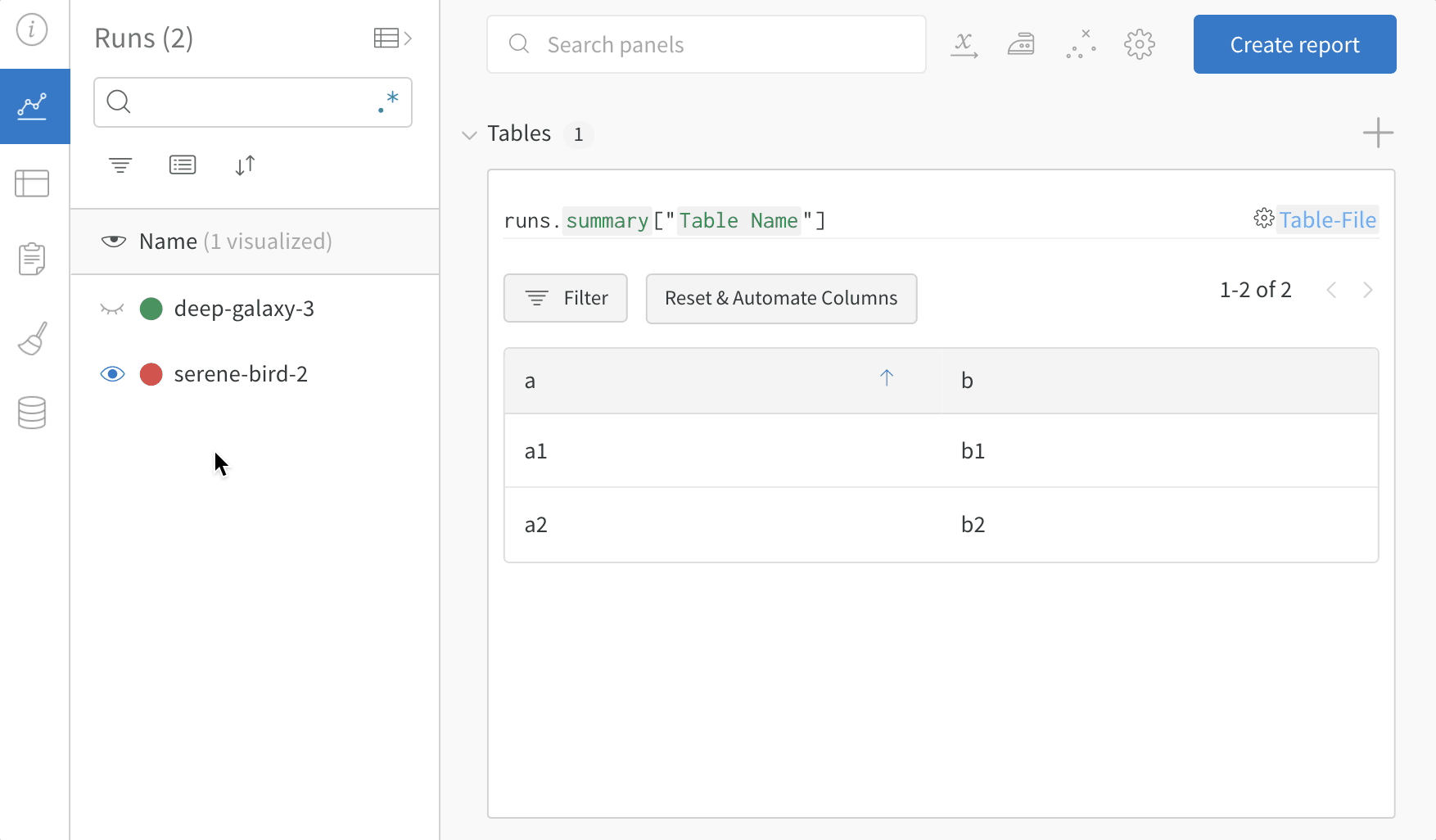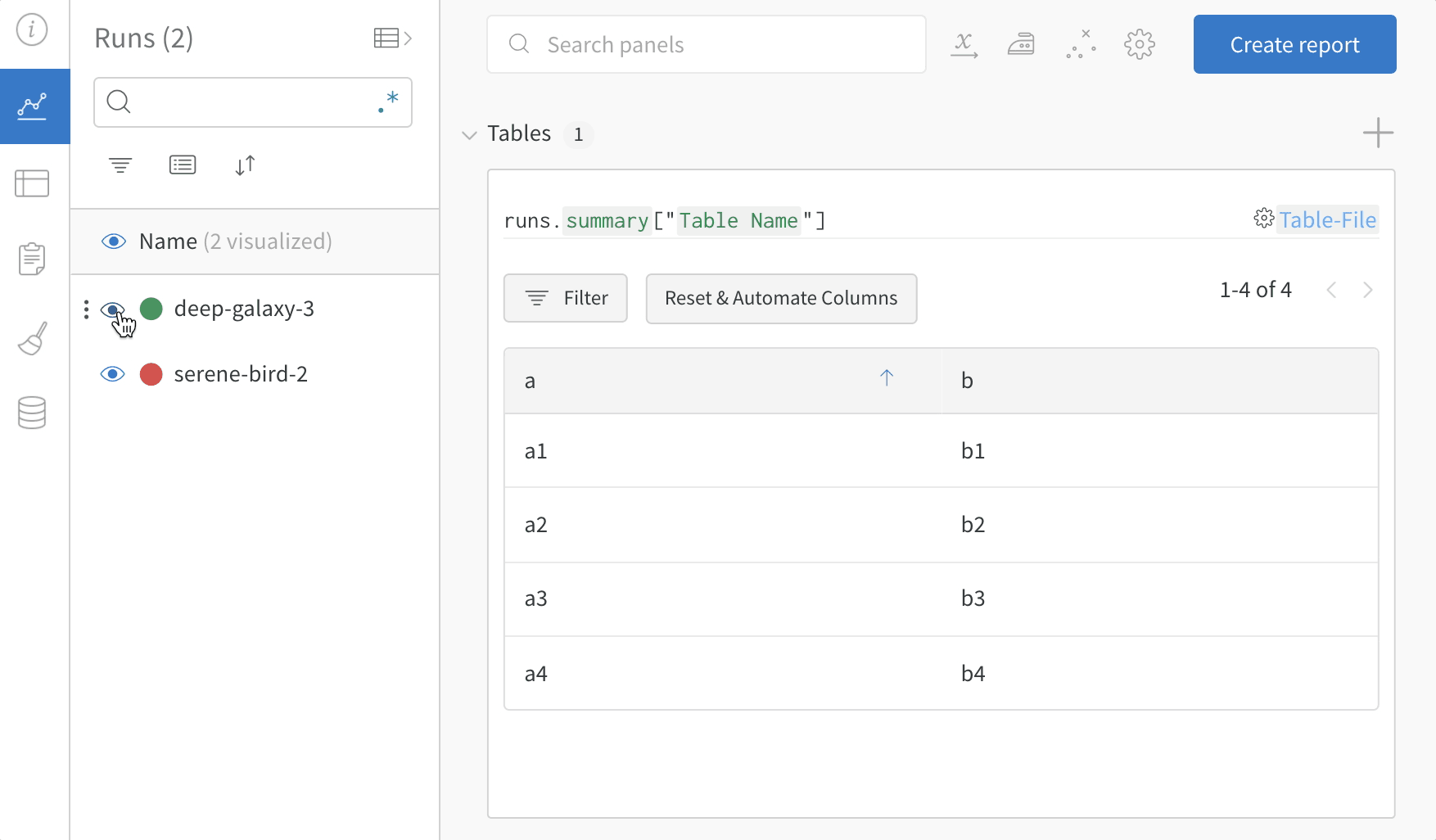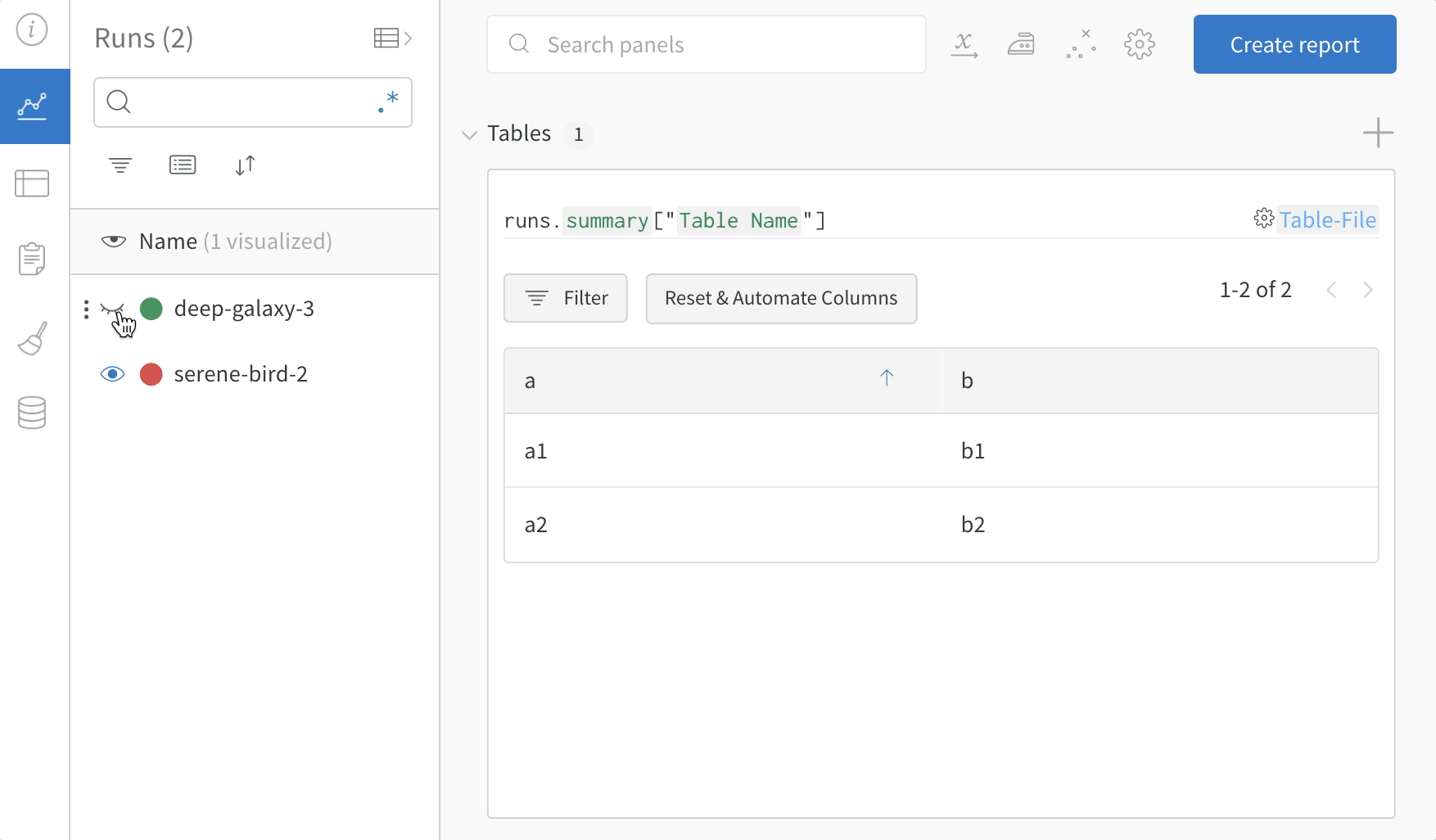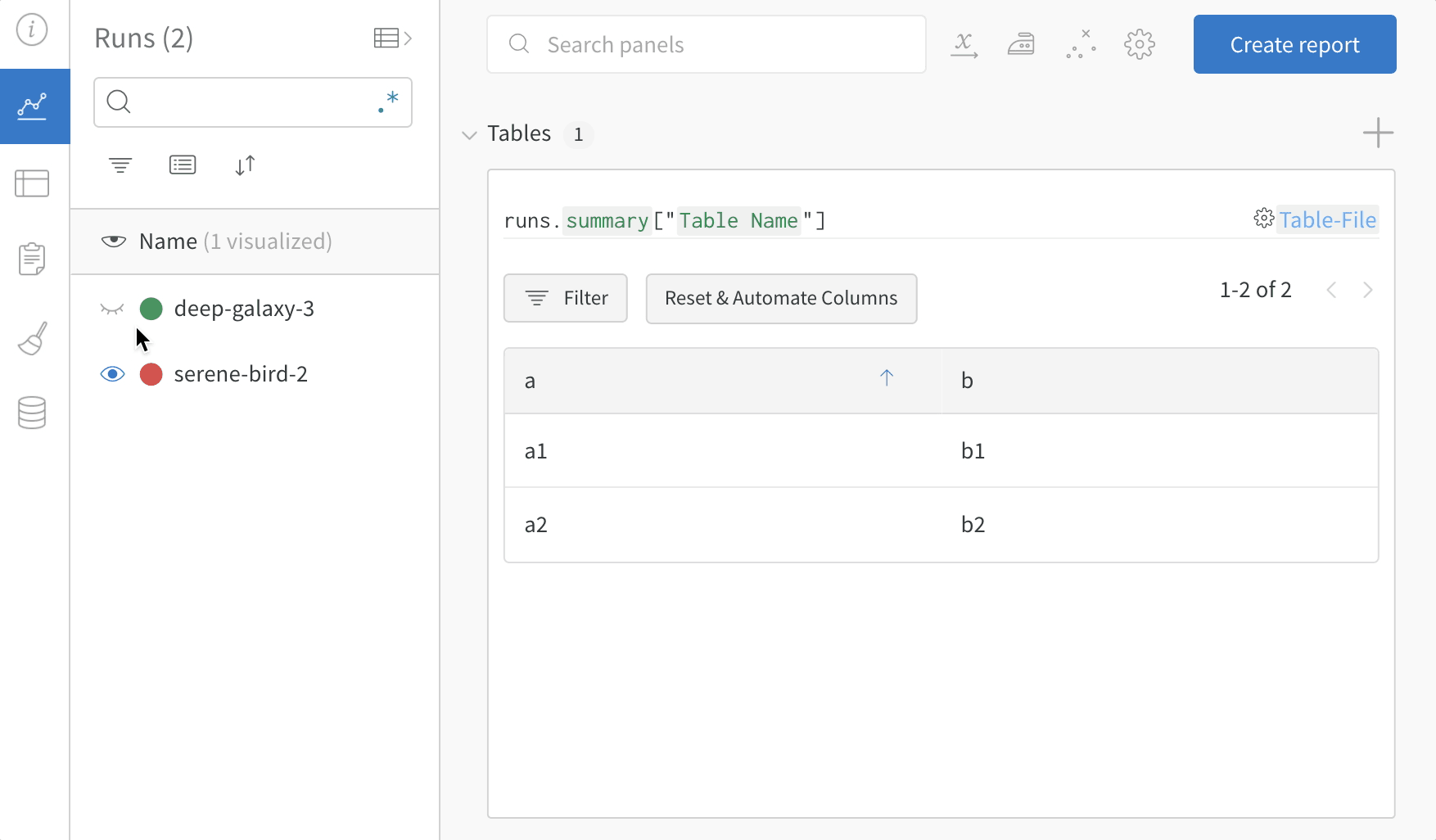
- プロジェクトのワークスペースで、自分の run の名前を選択します。一意のテーブルキーごとに新しいパネルが追加されます。
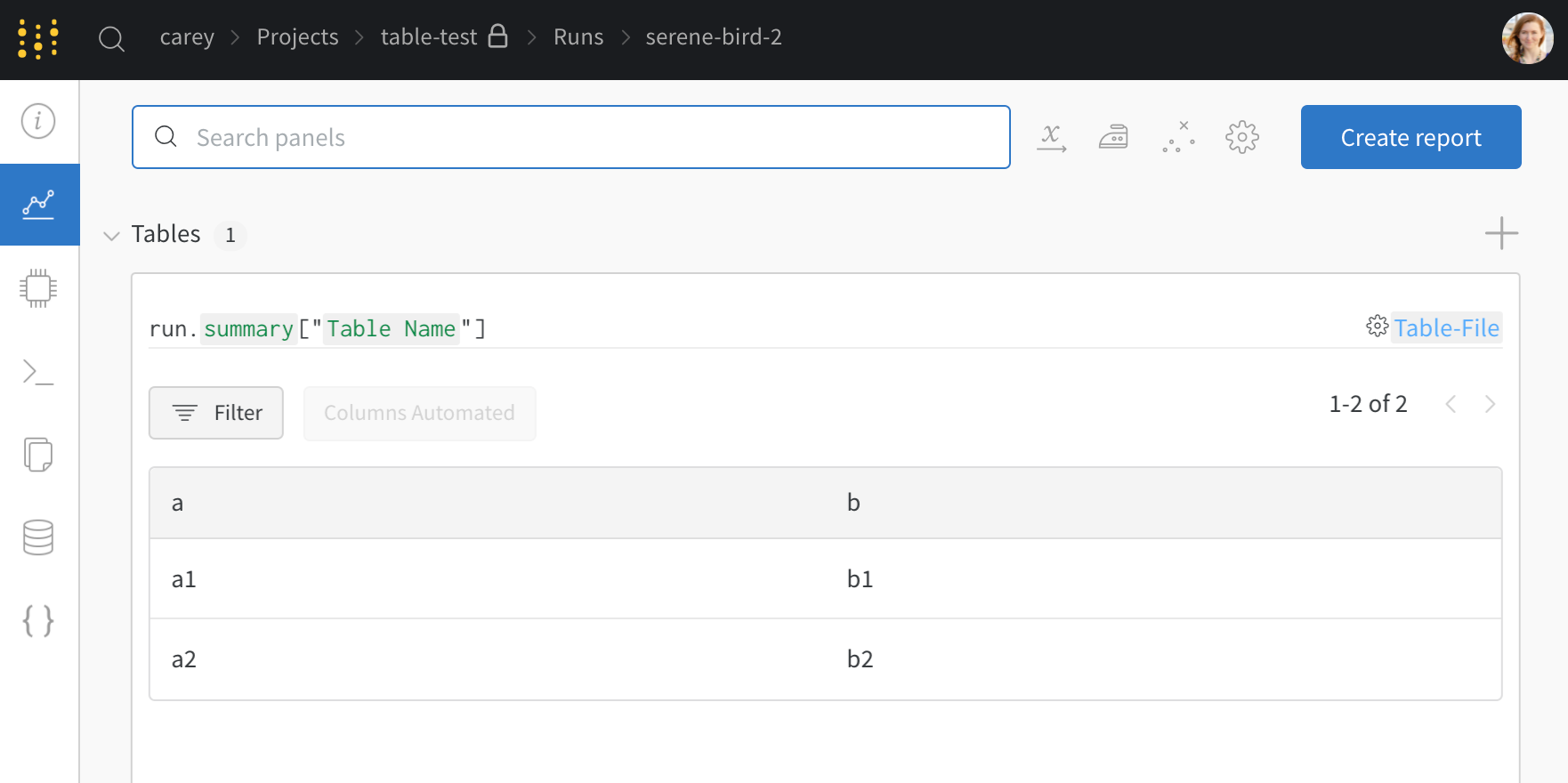
my_table はキー "Table Name" としてログされています。
3. モデルバージョン間で比較する