基本的な例: Weave を使って Llama 3.1 8B をトレースする
- チャット補完リクエストを行う
@weave.op()デコレータ付き関数を定義する - トレースが記録され、W&B のエンティティおよびプロジェクトに関連付けられる
- 関数が自動的にトレースされ、入力、出力、レイテンシ、およびメタデータがログに記録される
- 結果がターミナルに出力され、トレースが https://wandb.ai の Traces タブに表示される
- ターミナルに出力されたリンクをクリックする(例:
https://wandb.ai/<your-team>/<your-project>/r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g) - または https://wandb.ai にアクセスし、Traces タブを選択する
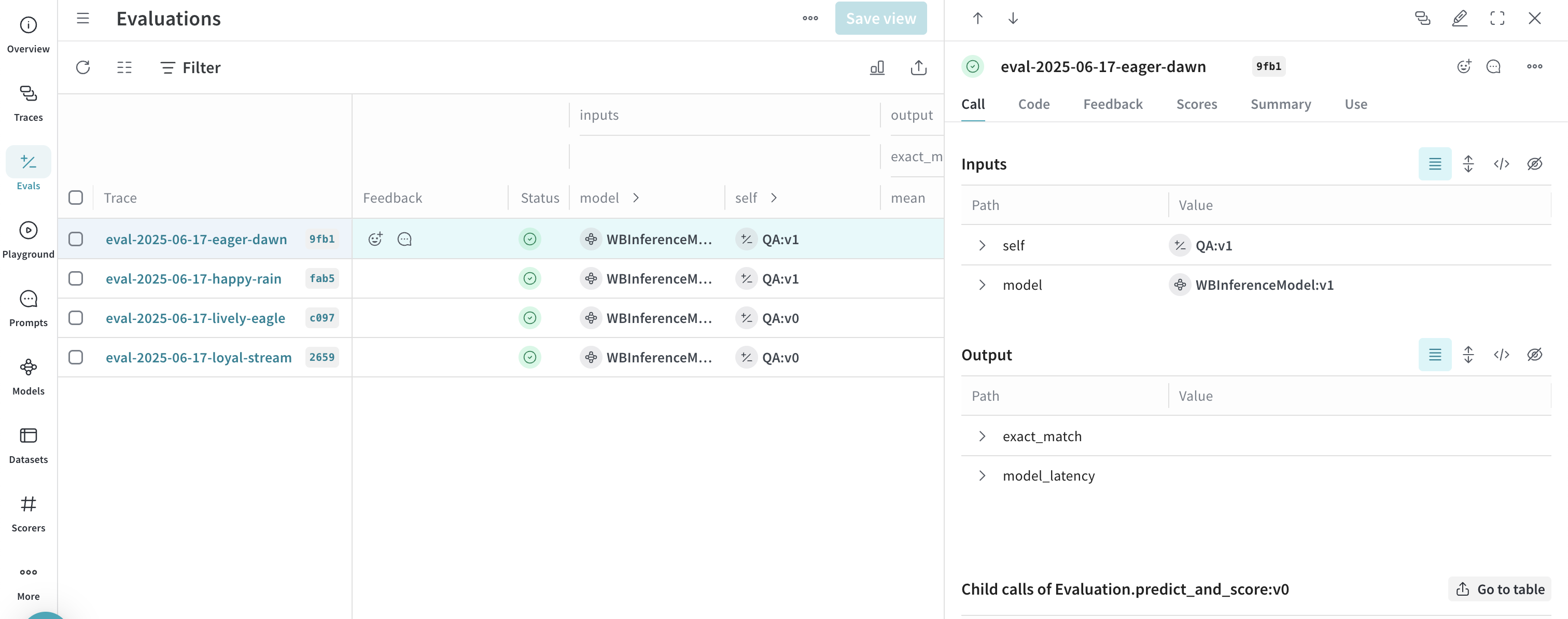
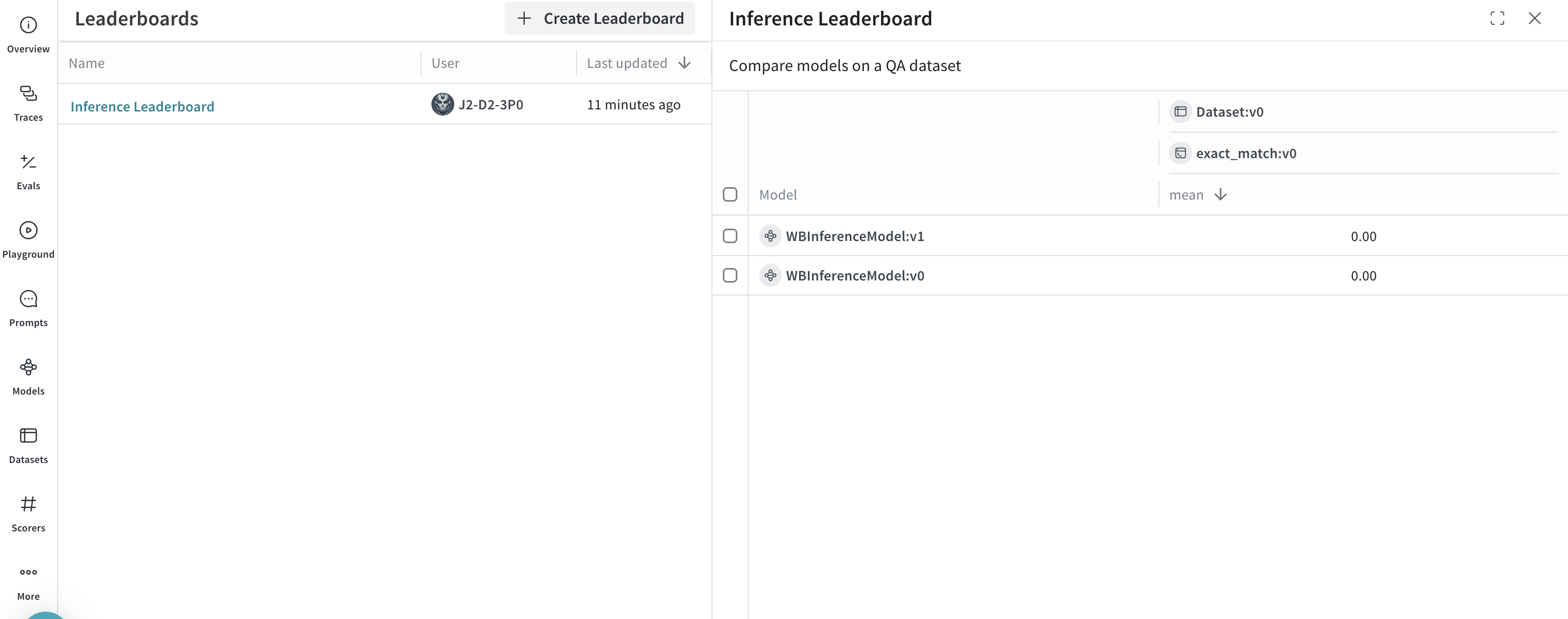
応用例: Weave Evaluations と Leaderboards を利用する
- Traces タブを選択して、トレースを表示します
- Evals タブを選択して、モデルの評価結果を表示します
- Leaders タブを選択して、生成されたリーダーボードを表示します
次のステップ
- 利用可能なメソッドの一覧は API リファレンス を参照してください
- UI でモデルを試してください