Fidélité totale
- Préserver les valeurs extrêmes et les pics : conservez les valeurs extrêmes et les pics dans vos données.
- Configurer le rendu des points minimum et maximum : utilisez le W&B App pour choisir de manière interactive si vous souhaitez afficher les valeurs extrêmes (min/max) sous forme de zone ombrée.
- Explorer vos données sans perte de fidélité : W&B recalcule la taille des buckets du axe X lorsque vous zoomez sur des points de données spécifiques. Cela vous permet d’explorer vos données sans perdre en précision. La mise en cache est utilisée pour stocker les agrégations précédemment calculées afin de réduire les temps de chargement, ce qui est particulièrement utile lorsque vous parcourez de grands jeux de données.
Activer la fidélité totale
- Tous les graphiques dans un Workspace
- Graphique individuel dans un Workspace
- Accédez à votre Workspace.
- Sélectionnez l’icône d’engrenage dans le coin supérieur droit de l’écran, à gauche du bouton Add panels.
- Dans le panneau de l’interface qui s’affiche, sélectionnez graphique en courbes
- Choisissez fidélité totale dans la section agrégation des points.
- Configurez l’algorithme et les paramètres de lissage.
- Réglez Aggregation sur Mean, Min ou Max.
- Cliquez sur Apply.
Configurer l’ombrage
- Min/Max : pour chaque point de l’axe X, la zone comprise entre les valeurs minimale et maximale est ombrée. La zone ombrée montre tous les points, de la valeur la plus faible à la plus élevée, dans chaque bucket : où x_1, x_2, \ldots, x_n sont les valeurs d’un bucket donné.
- Standard deviation : pour chaque point de l’axe X, calculez la variabilité des valeurs à l’aide de l’écart type, puis ombrez la zone obtenue.
- Standard error : pour chaque point de l’axe X, calculez l’erreur standard en divisant l’écart type par la racine carrée de la taille de l’échantillon :
- None : aucun ombrage (par défaut).
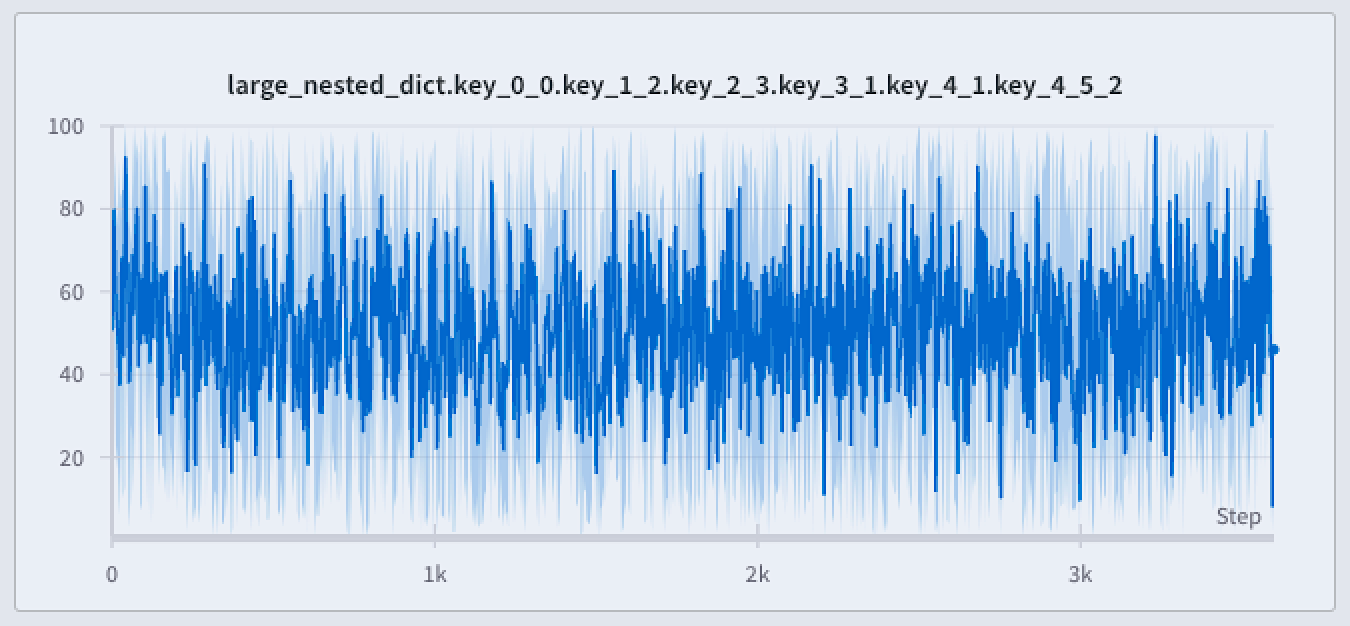
- Accédez à votre Workspace.
- Survolez un graphique en courbes, puis cliquez sur l’icône d’engrenage.
- Dans l’onglet Data, définissez agrégation des points sur fidélité totale si nécessaire, puis configurez l’algorithme de lissage.
- Dans l’onglet Grouping, activez Group runs. Si vous le souhaitez, définissez Group by sur un attribut de run.
- Définissez Agg sur Mean (par défaut), Min ou Max.
- Définissez Range sur Min/Max, Std Dev, Std Err ou None.
- Cliquez sur Apply.
Explorez vos données sans perdre en fidélité des données
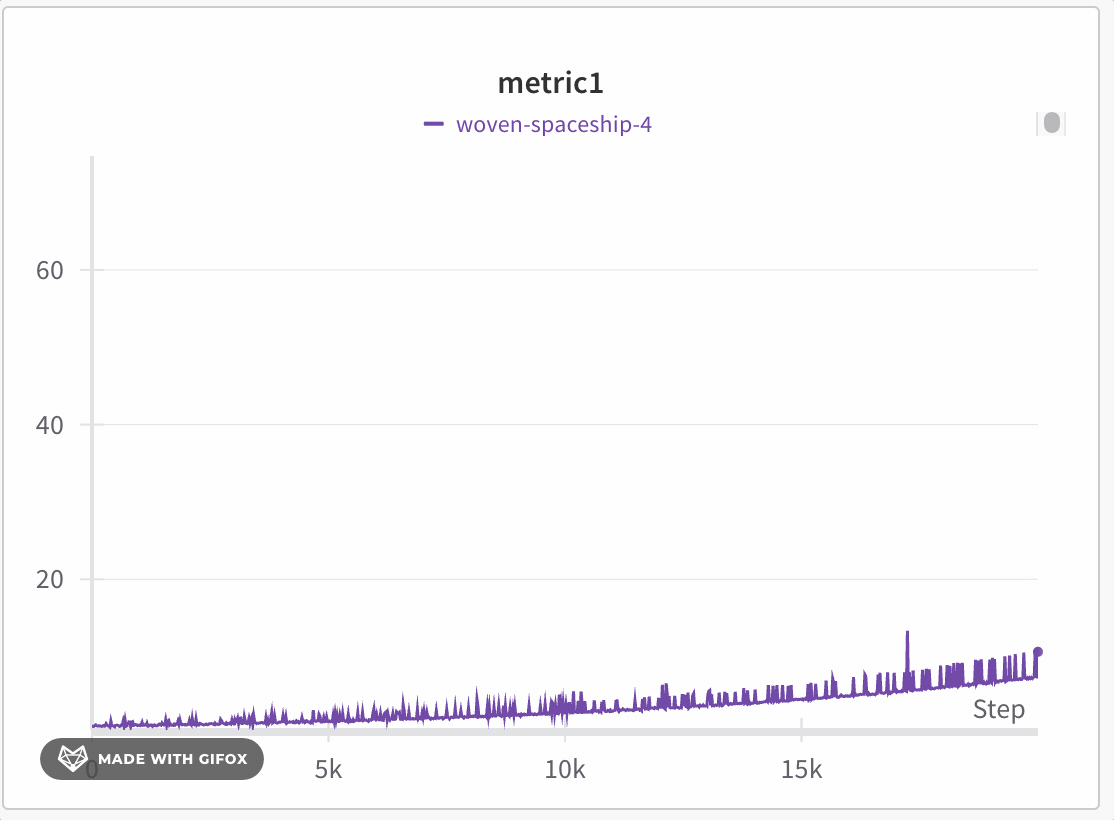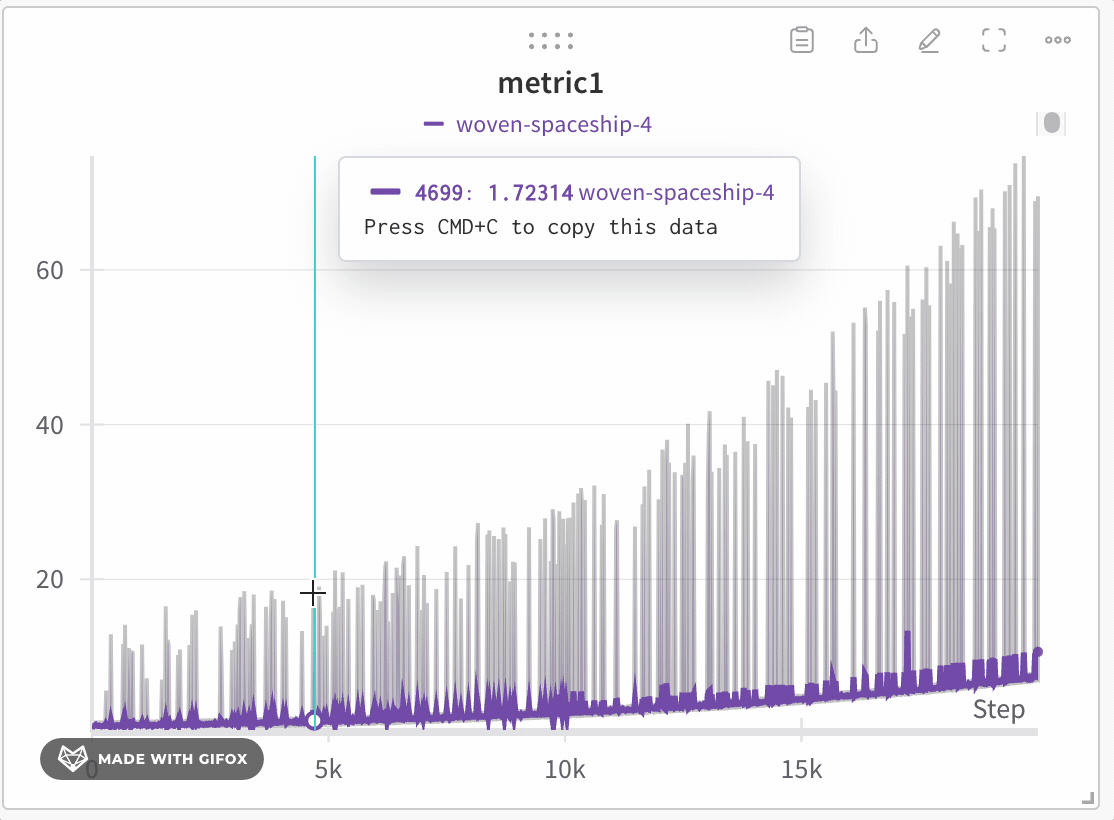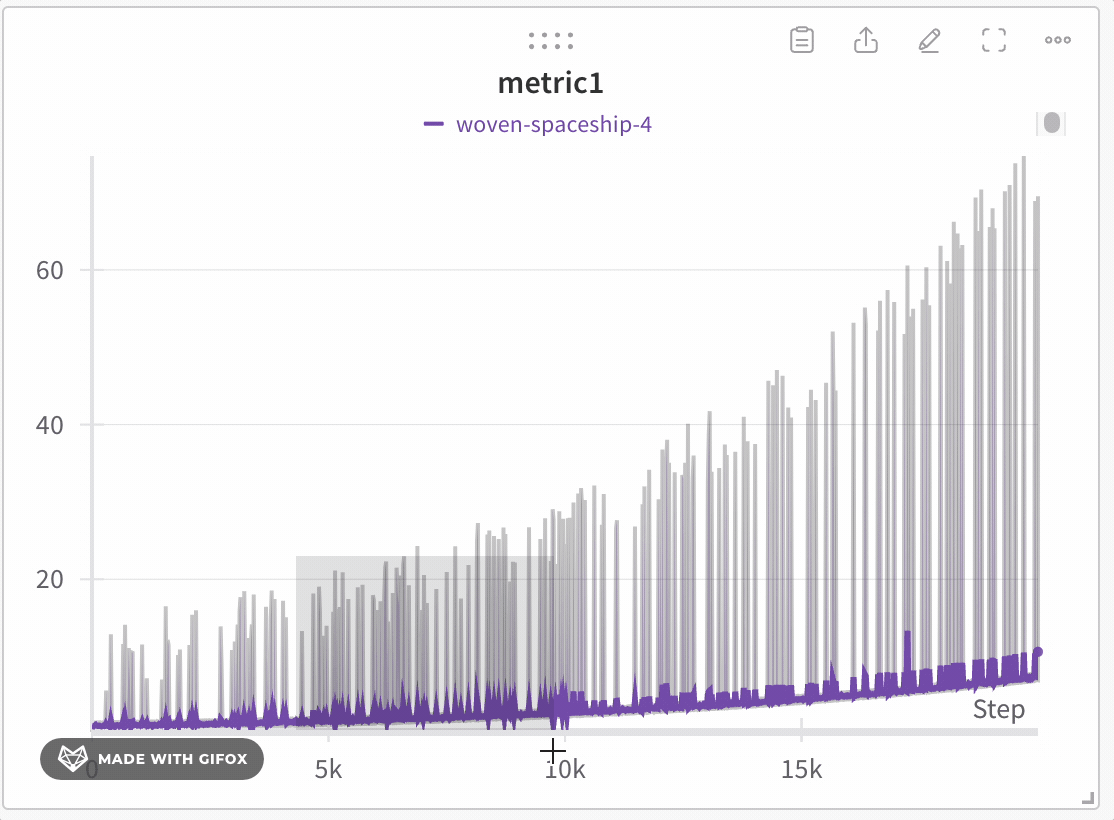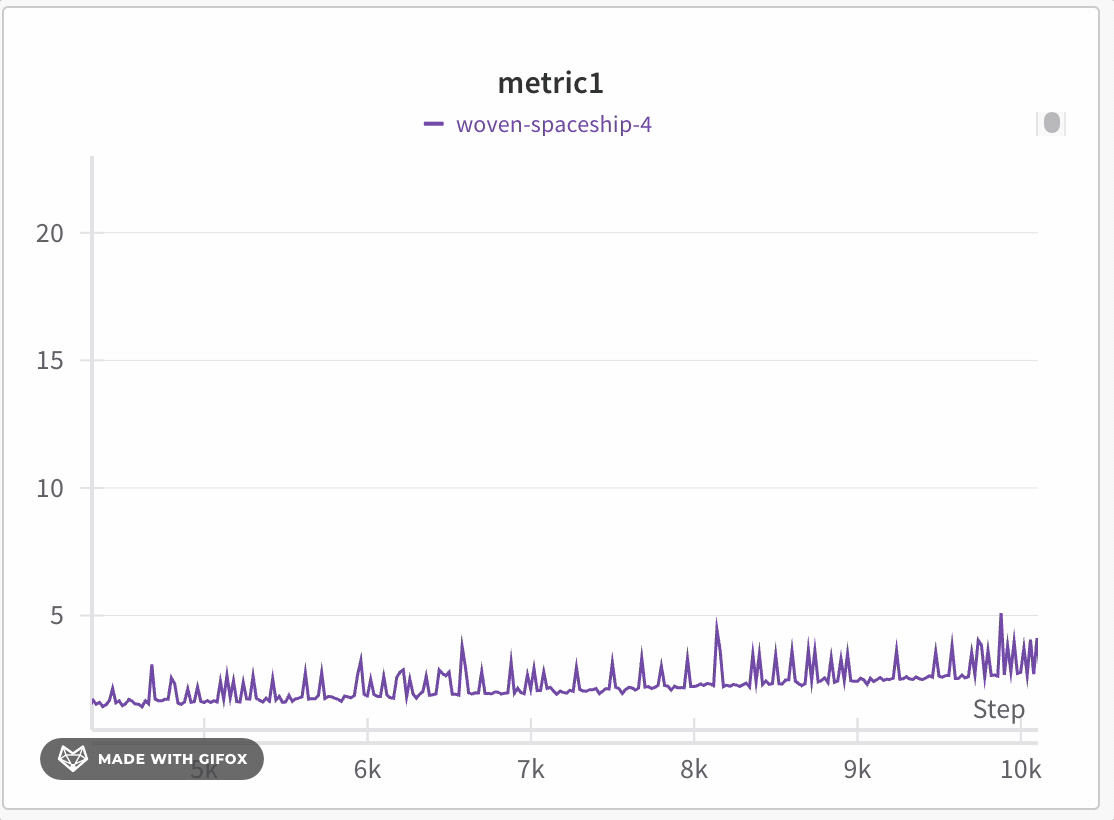
- Minimum : la valeur la plus basse de ce bucket (utilisée pour l’ombrage).
- Maximum : la valeur la plus élevée de ce bucket (utilisée pour l’ombrage).
- Line value : la dernière valeur de ce bucket, utilisée pour tracer la ligne.
- Accédez à votre projet W&B
- Sélectionnez l’icône Workspace dans la barre latérale gauche
- Si vous le souhaitez, ajoutez un panneau de graphique linéaire à votre Workspace ou accédez à un panneau de graphique linéaire existant.
- Cliquez et faites glisser pour sélectionner une zone spécifique sur laquelle zoomer.
Regroupement de graphiques en courbes et expressionsLorsque vous utilisez le regroupement de graphiques en courbes, W&B applique les éléments suivants selon le mode sélectionné :
- Échantillonnage sans fenêtrage (regroupement) : aligne les points entre les Runs sur l’axe des x. Une moyenne est calculée si plusieurs points partagent la même valeur x ; sinon, ils apparaissent comme des points distincts.
- Échantillonnage fenêtré (regroupement et expressions) : divise l’axe des x soit en 250 buckets, soit selon le nombre de points de la ligne la plus longue (la plus petite des deux valeurs étant retenue). W&B calcule la moyenne des points dans chaque bucket.
- Fidélité totale (regroupement et expressions) : similaire à l’échantillonnage sans fenêtrage, mais récupère jusqu’à 500 points par run afin d’équilibrer les performances et le niveau de détail.
Échantillonnage aléatoire
Activer l’échantillonnage aléatoire
- Tous les graphiques d’un Workspace
- Graphique individuel dans un Workspace
- Accédez à votre projet W&B
- Sélectionnez l’icône Workspace dans l’onglet de gauche
- Sélectionnez l’icône d’engrenage dans le coin supérieur droit de l’écran, à gauche du bouton Add panels.
- Dans le volet qui s’affiche, sélectionnez Graphiques en courbes
- Choisissez Échantillonnage aléatoire dans la section Agrégation des points