Paramètres des données
Axe X
wandb.Run.log().
Options d’axe X basées sur le temps disponibles :
- Étape: S’incrémente à chaque appel de
wandb.Run.log(). Reflète le nombre d’étapes d’entraînement enregistrées par votre modèle. (Par défaut) - Temps relatif (horloge): Temps écoulé depuis le démarrage du processus. Si vous démarrez un run, le mettez en pause pendant une journée, puis le reprenez et enregistrez, ce point apparaît à 24 heures.
- Temps relatif (processus): Temps écoulé dans le processus en cours d’exécution. Si vous démarrez un run, l’exécutez pendant 10 secondes, le mettez en pause pendant une journée, puis le reprenez, ce point apparaît à 10 secondes.
- Temps réel: Minutes écoulées depuis le début du premier run sur le graphique.
- Plage X: Va par défaut de la plus petite à la plus grande valeur de votre axe X. Vous pouvez personnaliser les valeurs minimale et maximale.
Axe Y
wandb.Run.log(). Indiquez une valeur unique, un tableau de valeurs ou un histogramme de valeurs. Si vous avez enregistré plus de 1500 points pour une variable, W&B en échantillonne 1500.
Personnalisez la couleur des lignes de l’axe y en modifiant la couleur du run dans la Runs table.
- Plage Y : Par défaut, elle s’étend de la plus petite valeur positive de vos métriques (0 inclus) à la plus grande. Vous pouvez personnaliser les valeurs minimale et maximale.
Méthode d’agrégation des points
- Échantillonnage aléatoire (par défaut) : Voir Échantillonnage aléatoire.
- Fidélité totale : Voir Fidélité totale.
Lissage
- EMA pondérée dans le temps (par défaut) : technique de lissage des données de séries temporelles qui réduit de façon exponentielle le poids des points précédents.
- Moyenne mobile : remplace un point par la moyenne des points d’une fenêtre située avant et après la valeur x donnée.
- Gaussienne : calcule une moyenne pondérée des points, où les poids correspondent à une distribution gaussienne dont l’écart type est défini comme paramètre de lissage.
- Aucun lissage
Ignorer les valeurs aberrantes
- Mode d’échantillonnage aléatoire : ignorer les valeurs aberrantes omet du graphique les points en dessous de 5 % et au-dessus de 95 %.
- Mode de fidélité totale : ignorer les valeurs aberrantes affiche tous les points, ramenés à la dernière valeur de chaque bucket, et grise la zone en dessous de 5 % et au-dessus de 95 %.
Nombre maximal de runs ou de groupes
Un Workspace ne peut afficher que 1000 runs maximum, quelle que soit sa configuration.
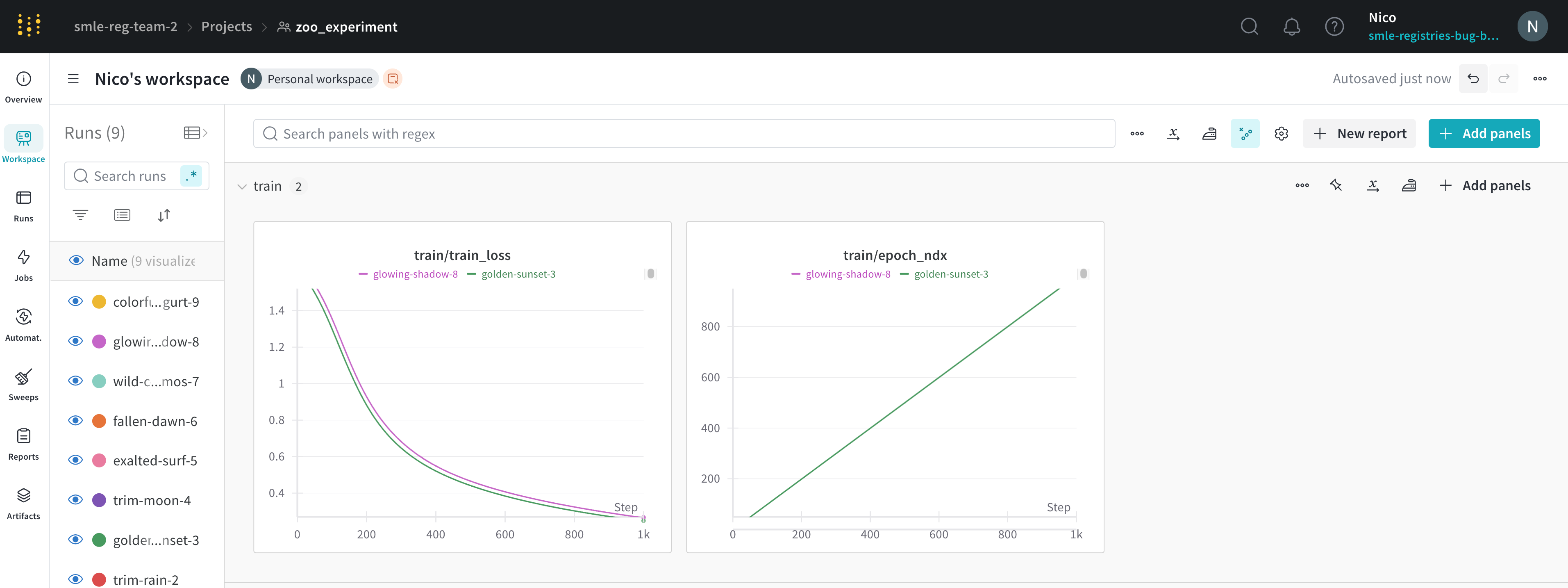
Type de graphique
- Graphique en courbes
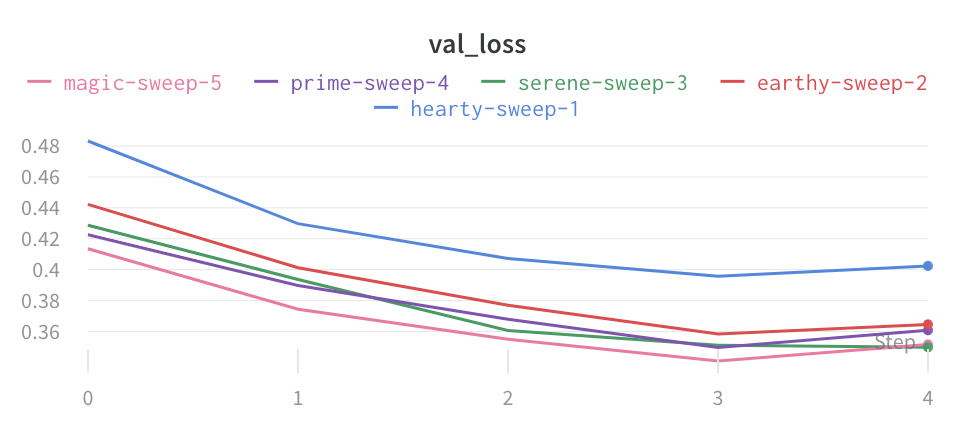
- Graphique en aires
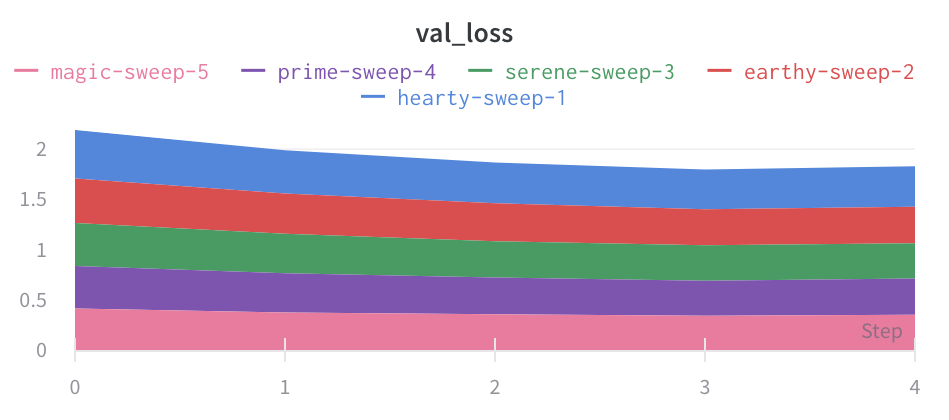
- Graphique en aires en pourcentage :
Paramètres de regroupement
- Regrouper les runs : Active le regroupement des runs dans le graphique. Requis pour configurer la zone ombrée du graphique ci-dessous.
- Regrouper par : Sélectionnez éventuellement une colonne. Tous les runs ayant la même valeur dans cette colonne sont regroupés ensemble.
- Agrégation : La valeur de la courbe sur le graphique. Les options sont la moyenne, la médiane, le minimum et le maximum du groupe.
- Plage : Configurez la zone ombrée d’un graphique en courbes complet. Les options sont Min/Max, écart-type, erreur standard ou aucune.
Paramètres du graphique
- Titre du panneau : Titre affiché en haut du panneau.
- Titre de l’axe x : Libellé de l’axe x.
- Titre de l’axe y : Libellé de l’axe y.
- Légende : Affichez ou masquez la légende et configurez sa position.
Paramètres de la légende
Modèle de légende
- Cliquez sur l’icône d’engrenage pour ouvrir les paramètres du graphique.
- Accédez à l’onglet Préférences d’affichage.
- Développez Légende avancée, puis indiquez le modèle de légende.
- Cliquez sur Appliquer.
${run:displayName} - ${config:dropout} produit un nom de légende comme royal-sweep - 0.5, où royal-sweep est le nom de l’exécution et 0.5 est le paramètre de configuration appelé dropout.
Valeurs spécifiques à un point
[[ ]] pour afficher des valeurs spécifiques à un point dans le réticule lorsque vous survolez un graphique.
- Cliquez sur l’icône d’engrenage pour ouvrir les paramètres du graphique.
- Accédez à l’onglet Préférences d’affichage.
- En bas de l’onglet, configurez des valeurs spécifiques à un point pour une ou plusieurs métriques du graphique.
- Cliquez sur Appliquer.
[[ $x: $y ($original) ]] affiche quelque chose comme “2: 3 (2.9)”
Valeurs prises en charge entre [[ ]] :
| Valeur | Signification |
|---|---|
${x} | Valeur X |
${y} | Valeur Y (y compris l’ajustement du lissage) |
${original} | Valeur Y sans l’ajustement du lissage |
${mean} | Moyenne des runs groupés |
${stddev} | Écart type des runs groupés |
${min} | Minimum des runs groupés |
${max} | Maximum des runs groupés |
${percent} | Pourcentage du total (pour les graphiques en aires empilées) |
Expressions
Expressions de l’axe Y
1-accuracy ou d’autres expressions arithmétiques. Pour le moment, cela fonctionne uniquement lorsque vous tracez une seule métrique.
Opérateurs pris en charge : +, -, *, /, % et ** (pour les puissances).
Vous pouvez calculer des lignes personnalisées à partir à la fois de métriques enregistrées et de valeurs de configuration telles que des hyperparamètres.
Expressions de l’axe X
_step: La valeur par défaut de l’axe X.${summary:value}: Valeurs de référence du résumé.
Expressions de panneau à plusieurs métriques
- Au lieu de créer des panneaux distincts pour les métriques de chaque couche, vous pouvez les afficher ensemble dans un seul panneau. Par exemple, si vous consignez des métriques avec un schéma de nommage cohérent, comme
layer_0_loss,layer_1_lossetlayer_2_loss, vous pouvez utiliser une expression régulière commelayer_\d+_losspour afficher toutes les pertes des couches sur un même graphique. - Faites correspondre toutes les métriques qui partagent un schéma de nommage commun. Par exemple :
train_.*correspond à toutes les métriques d’entraînement commetrain_loss,train_accuracy,train_f1_score.*_accuracycorrespond aux métriques d’accuracy sur différents jeux de données commetrain_accuracy,val_accuracy,test_accuracy
- Utilisez l’alternance pour faire correspondre uniquement les métriques souhaitées. Par exemple, le groupe non capturant
(?:layer_0|layer_10)_losscorrespond uniquement aux pertes de la première et de la dixième couche, en excluant les couches intermédiaires.
Groupes de capture
-
Les groupes de capture créent plusieurs panneaux
Lorsque votre expression régulière contient des parenthèses formant un groupe de capture, l’UI crée un panneau distinct pour chaque valeur unique capturée par ce groupe.
Par exemple, l’expression
(layer_0|layer_10)_losscontient un groupe de capture et créera deux panneaux distincts :- Un panneau pour les métriques correspondant à
layer_0. - Un panneau pour les métriques correspondant à
layer_10.
- Un panneau pour les métriques correspondant à
-
Les groupes non capturants conservent les métriques ensemble
Pour faire correspondre plusieurs alternatives sans créer de panneaux distincts, utilisez un groupe non capturant avec la syntaxe
?:. L’expression(?:layer_0|layer_10)_losscorrespond aux mêmes métriques que dans l’exemple précédent, mais les affiche ensemble dans un seul panneau.
(layer_0|layer_10)_loss- Crée deux panneaux, un pour chaque couche.(?:layer_0|layer_10)_loss- Crée un panneau affichant les deux couches ensemble.