これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクから利用できます:
PII データを含む Weave の使用方法
- PII データを特定してマスキングするための 正規表現。
- Python ベースのデータ保護 SDK である Microsoft の Presidio。このツールはマスキングおよび置換機能を提供します。
- PII データを匿名化するために Presidio と組み合わせて使用する、偽データ生成用 Python ライブラリ Faker。
weave.op の入出力ログのカスタマイズ と autopatch_settings を利用して、PII のマスキングおよび匿名化をワークフローに統合する方法も説明します。詳細は、ログされる入力と出力をカスタマイズするを参照してください。
開始するには、次の手順を実行します。
- 概要 セクションを確認します。
- 前提条件 を満たします。
- PII データを特定、マスキング、匿名化するための 利用可能な方法 を確認します。
- Weave 呼び出しにこれらの方法を適用します。
概要
weave.op を使用した入力および出力ログの記録方法の概要と、Weave で PII データを扱う際のベストプラクティスについて説明します。
weave.op を使って入出力のロギングをカスタマイズする
weave.op() の引数として渡しています。
PII データとともに Weave を使用する際のベストプラクティス
テスト時
- 匿名化したデータを記録して、PII 検出を確認する
- Weave Traces を使って PII 処理プロセスを追跡する
- 実際の PII をさらすことなく、匿名化処理の性能を測定する
本番環境で
- 生の PII をログに記録しない
- ログに記録する前に機微なフィールドを暗号化する
暗号化のヒント
- 後で復号する必要があるデータには、可逆暗号化を使用する
- 逆変換する必要のない一意の ID には、一方向ハッシュを適用する
- 暗号化したまま分析する必要があるデータには、その用途に特化した暗号化方式の利用を検討する
前提条件
- まず、必要なパッケージをインストールしてください。
- 次の場所でAPIキーを作成します:
- Weave プロジェクトを初期化します。
- 10個のテキストブロックを含むデモ用PIIデータセットを読み込みます。
マスキング方法の概要
- 正規表現 を使って PII データを特定し、マスキングします。
- Microsoft Presidio は、マスキングおよび置換機能を提供する Python ベースのデータ保護 SDK です。
- Faker は、ダミーデータを生成するための Python ライブラリです。
方法 1: 正規表現を使ったフィルタリング
方法 2: Microsoft Presidio を使用してマスクする
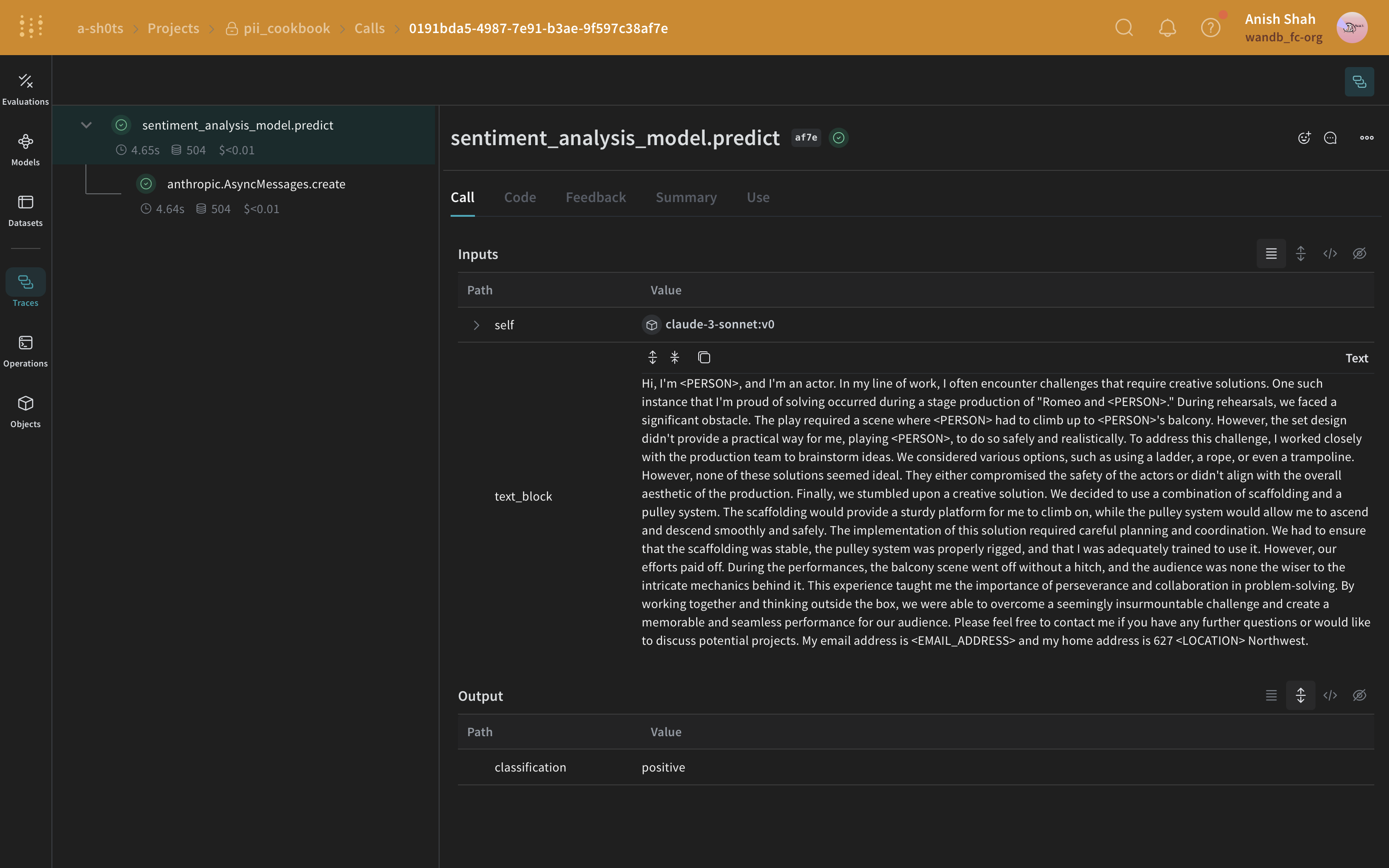
"My name is Alex" の中の Alex を <PERSON> に置き換えます。
Presidio には、一般的なエンティティ に対する組み込みサポートがあります。以下の例では、PHONE_NUMBER、PERSON、LOCATION、EMAIL_ADDRESS、US_SSN であるすべてのエンティティをマスクします。Presidio の処理は 1 つの関数としてカプセル化されています。
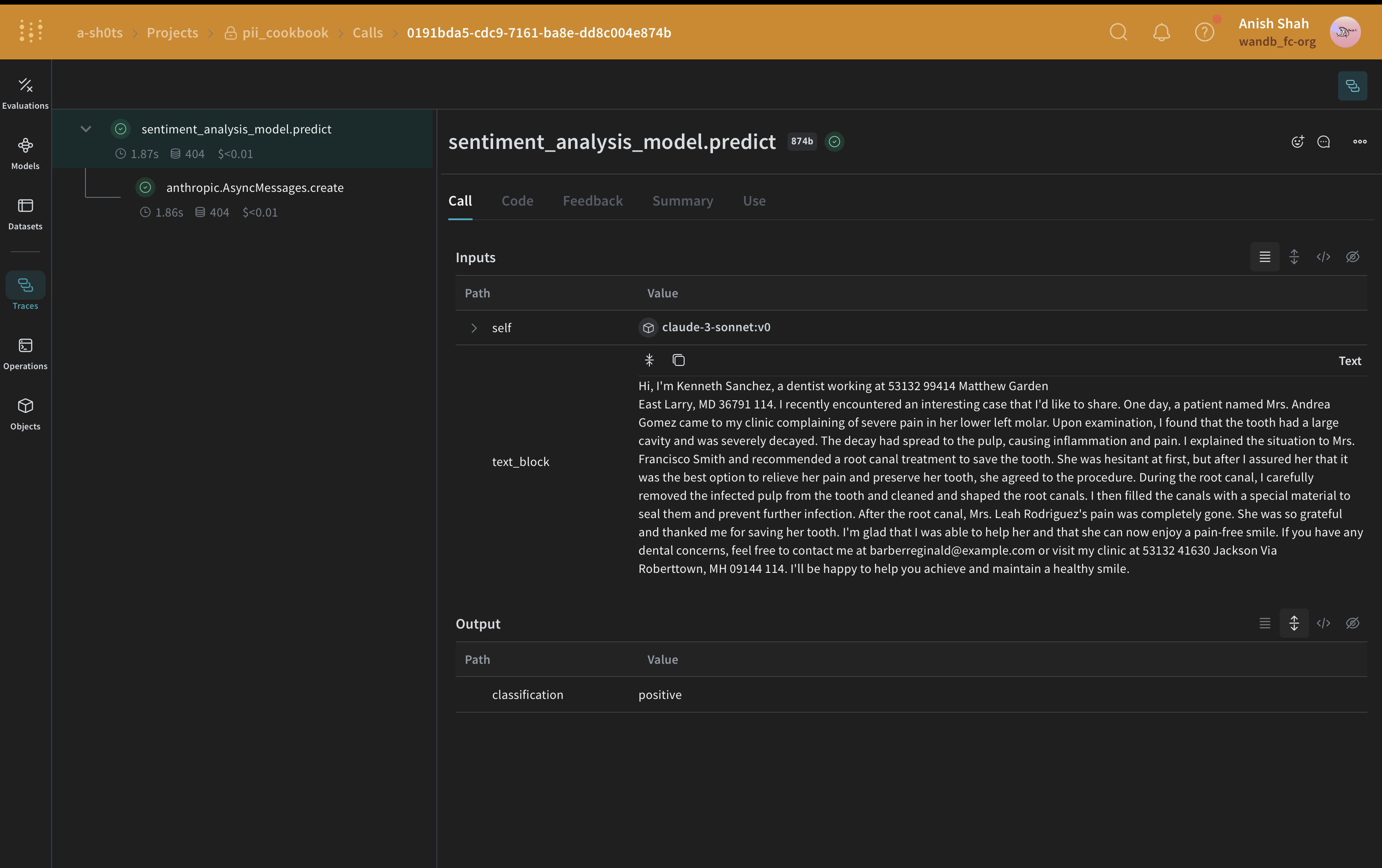
Method 3: Faker と Presidio を使った置換による匿名化
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
このデータを Presidio と Faker を使って処理すると、次のようになります:
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Presidio と Faker を効果的に組み合わせて使うには、カスタムオペレーターへの参照を指定する必要があります。これらのオペレーターによって、PII を偽データに置き換える役割を持つ Faker の関数をどれにするかを Presidio に指示します。
メソッド 4: autopatch_settings を使用する
autopatch_settings を使用して、サポートされている 1 つ以上の LLM インテグレーションに対する PII 処理を、初期化時に直接設定できます。この方法の利点は次のとおりです。
- PII 処理ロジックを初期化時点で一元管理しスコープを明確にできるため、各所にカスタムロジックを散在させる必要が減ります。
- 特定のインテグレーションごとに、PII 処理ワークフローをカスタマイズしたり、完全に無効化したりできます。
autopatch_settings を使用して PII 処理を設定するには、サポートされている任意の LLM インテグレーションの op_settings に postprocess_inputs および / または postprocess_output を定義します。
Weave 呼び出しにこれらの手法を適用する
predict 関数を含めます。Anthropic の Claude Sonnet を使用して感情分析を行い、Traces を使って LLM 呼び出しをトレースします。Claude Sonnet はテキストのブロックを受け取り、次のいずれかの感情分類を出力します: positive、negative、neutral。さらに、PII データが LLM に送信される前にマスキングまたは匿名化されるよう、後処理用の関数も含めます。
このコードを実行すると、Weave のプロジェクトページへのリンクと、実行した特定のトレース(LLM 呼び出し)へのリンクが表示されます。
Regex メソッド
Presidio によるマスキング方法
Faker と Presidio を使った置換方法
autopatch_settings メソッド
anthropic 向けの postprocess_inputs に postprocess_inputs_regex() 関数を設定します。postprocess_inputs_regex 関数は、Method 1: Regular Expression Filtering で定義した redact_with_regex メソッドを適用します。これにより、すべての anthropic モデルへの入力に redact_with_regex が適用されるようになります。
(オプション)データを暗号化する
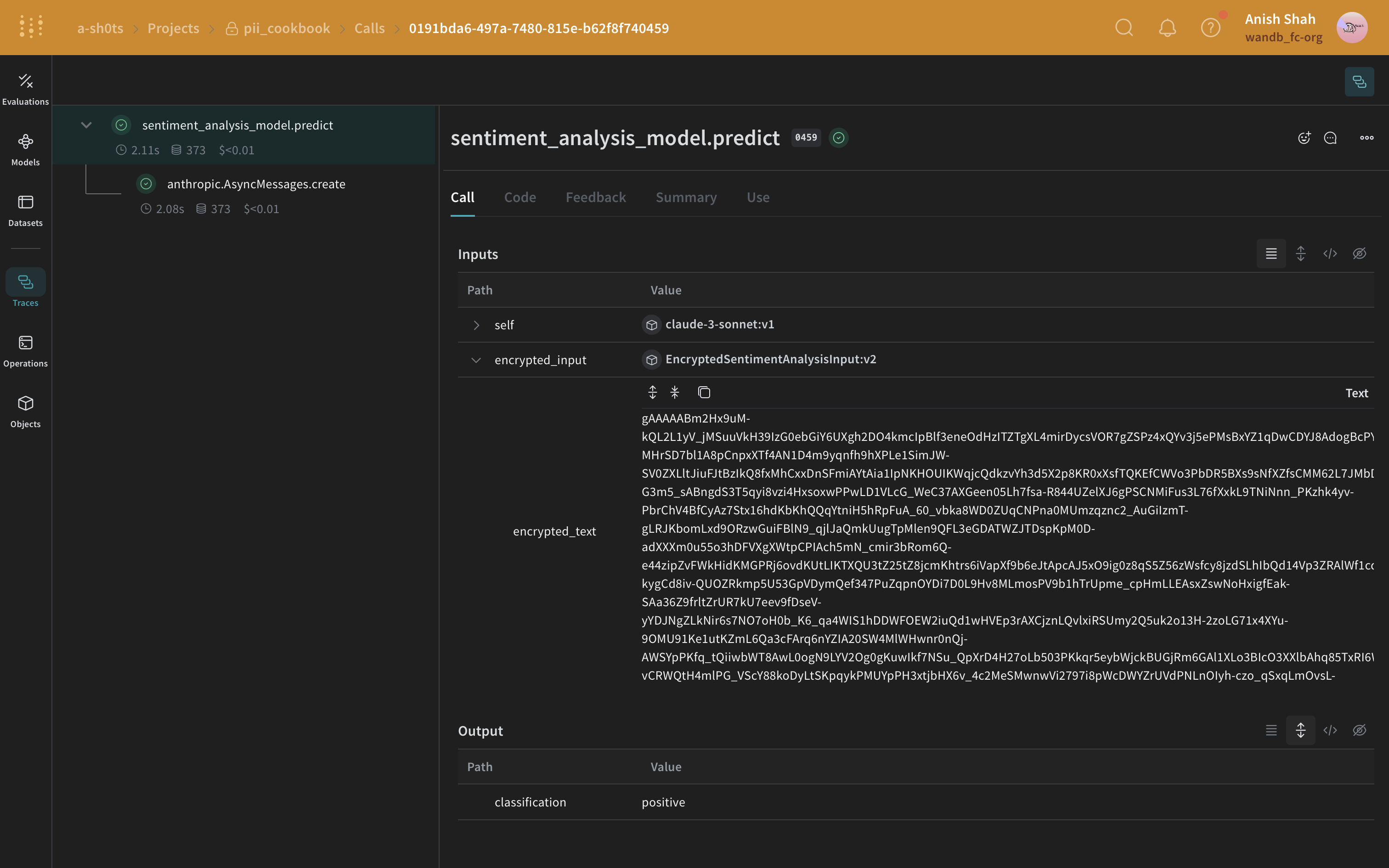
cryptography ライブラリの Fernet 対称鍵暗号を使ってデータを暗号化し、セキュリティをさらに強化できます。この方法により、匿名化されたデータが第三者に傍受されたとしても、暗号鍵がなければ内容を読み取ることはできません。