
Ce que vous trouverez dans ce notebook
Installer, importer et se connecter
Étape 0 : Installer W&B
wandb s’installe facilement avec pip.
Étape 1 : Importer W&B et vous connecter
Définir l’expérience et le pipeline
Suivre les métadonnées et les hyperparamètres avec wandb.init
config
(ou un objet similaire)
puis d’y accéder au besoin.
Dans cet exemple, nous ne faisons varier que quelques hyperparamètres
et codons le reste à la main.
Mais n’importe quelle partie de votre modèle peut faire partie de config.
Nous incluons également quelques métadonnées : nous utilisons le jeu de données MNIST et une architecture
convolutionnelle. Si, plus tard, nous travaillons par exemple avec
des architectures entièrement connectées sur CIFAR dans le même projet,
cela nous aidera à différencier nos runs.
- nous commençons par
makeun modèle, ainsi que les données et l’optimiseur associés, puis - nous
trainle modèle en conséquence et enfin - nous le
testpour voir comment l’entraînement s’est déroulé.
wandb.init.
L’appel à cette fonction établit un canal de communication
entre votre code et nos serveurs.
Le fait de passer le dictionnaire config à wandb.init
enregistre immédiatement toutes ces informations,
afin que vous sachiez toujours quelles valeurs d’hyperparamètres
vous avez choisi d’utiliser pour votre expérience.
Pour vous assurer que les valeurs que vous avez choisies et enregistrées sont toujours bien celles qui sont utilisées
dans votre modèle, nous vous recommandons d’utiliser la copie run.config de votre objet.
Consultez la définition de make ci-dessous pour voir quelques exemples.
Remarque : nous veillons à exécuter notre code dans des processus séparés,
afin que tout problème de notre côté
(par exemple, si un énorme monstre marin attaque nos centres de données)
ne fasse pas planter votre code.
Une fois le problème résolu, par exemple lorsque le Kraken retourne dans les profondeurs,
vous pouvez synchroniser les données avec wandb sync.
Définir le chargement des données et le modèle
wandb,
donc nous ne nous y attarderons pas.
wandb, rien ne change,
donc on va s’en tenir à une architecture ConvNet standard.
N’hésitez pas à faire quelques essais et à tester différentes variantes —
tous vos résultats seront enregistrés sur wandb.ai.
Définir la logique d’entraînement
model_pipeline, il est temps de préciser comment nous entraînons.
Deux fonctions wandb entrent en jeu ici : watch et log.
Suivre les gradients avec run.watch() et tout le reste avec run.log()
run.watch journalisera les gradients et les paramètres de votre modèle
toutes les log_freq étapes de l’entraînement.
Il vous suffit de l’appeler avant de commencer l’entraînement.
Le reste du code d’entraînement reste le même :
nous parcourons les époques et les lots,
en effectuant des passes avant et arrière
et en appliquant notre optimizer.
run.log().
run.log() attend un dictionnaire dont les clés sont des chaînes de caractères.
Ces chaînes identifient les objets enregistrés, qui constituent les valeurs.
Vous pouvez aussi indiquer, de façon facultative, à quelle step d’entraînement vous en êtes.
Remarque : j’aime utiliser le nombre d’exemples que le modèle a vus,
car cela facilite la comparaison entre différentes tailles de batch,
mais vous pouvez utiliser les étapes brutes ou le nombre de batches. Pour des runs d’entraînement plus longs, il peut aussi être pertinent de journaliser par epoch.
Définir la logique de test
(Facultatif) Appelez run.save()
exporter notre modèle au
format Open Neural Network eXchange (ONNX).
En passant ce nom de fichier à run.save(), vous vous assurez que les paramètres du modèle
sont enregistrés sur les serveurs de W&B : fini les pertes de repères pour savoir quel fichier .h5 ou .pb
correspond à quel run d’entraînement.
Pour des fonctionnalités wandb plus avancées pour le stockage, la gestion des versions et la distribution de
modèles, consultez nos outils Artifacts.
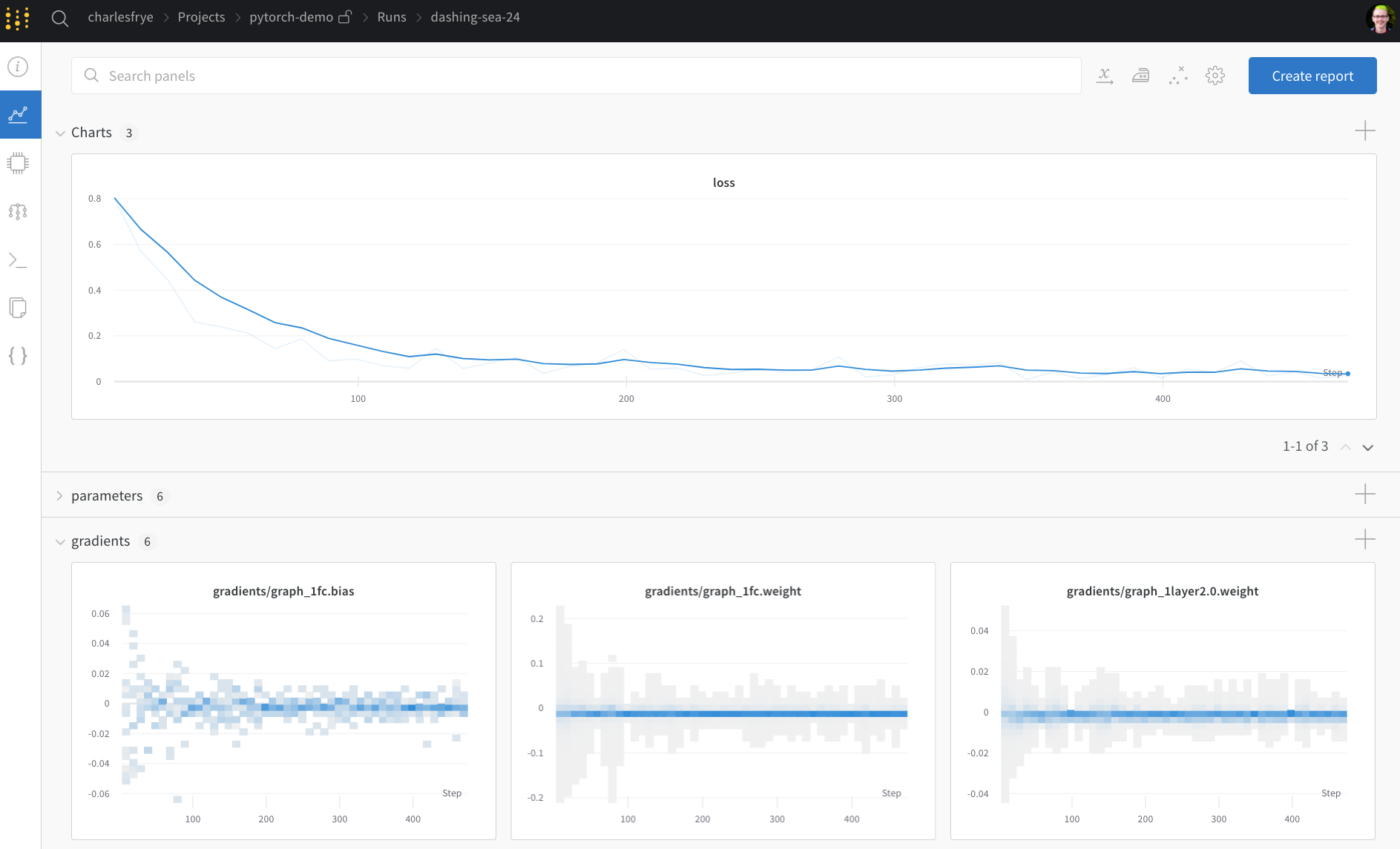
Exécutez l’entraînement et suivez vos métriques en direct sur wandb.ai
- Charts, où les gradients du modèle, les valeurs des paramètres et la perte sont enregistrés tout au long de l’entraînement
- System, qui contient diverses métriques système, notamment l’utilisation des E/S du disque, les métriques CPU et GPU (regardez cette température grimper), et bien plus encore
- Logs, qui contient une copie de tout ce qui a été envoyé vers la sortie standard pendant l’entraînement
- Files, où, une fois l’entraînement terminé, vous pouvez cliquer sur
model.onnxpour visualiser notre réseau avec le visualiseur de modèles Netron.
with wandb.init,
nous afficherons également un résumé des résultats dans la sortie de la cellule.
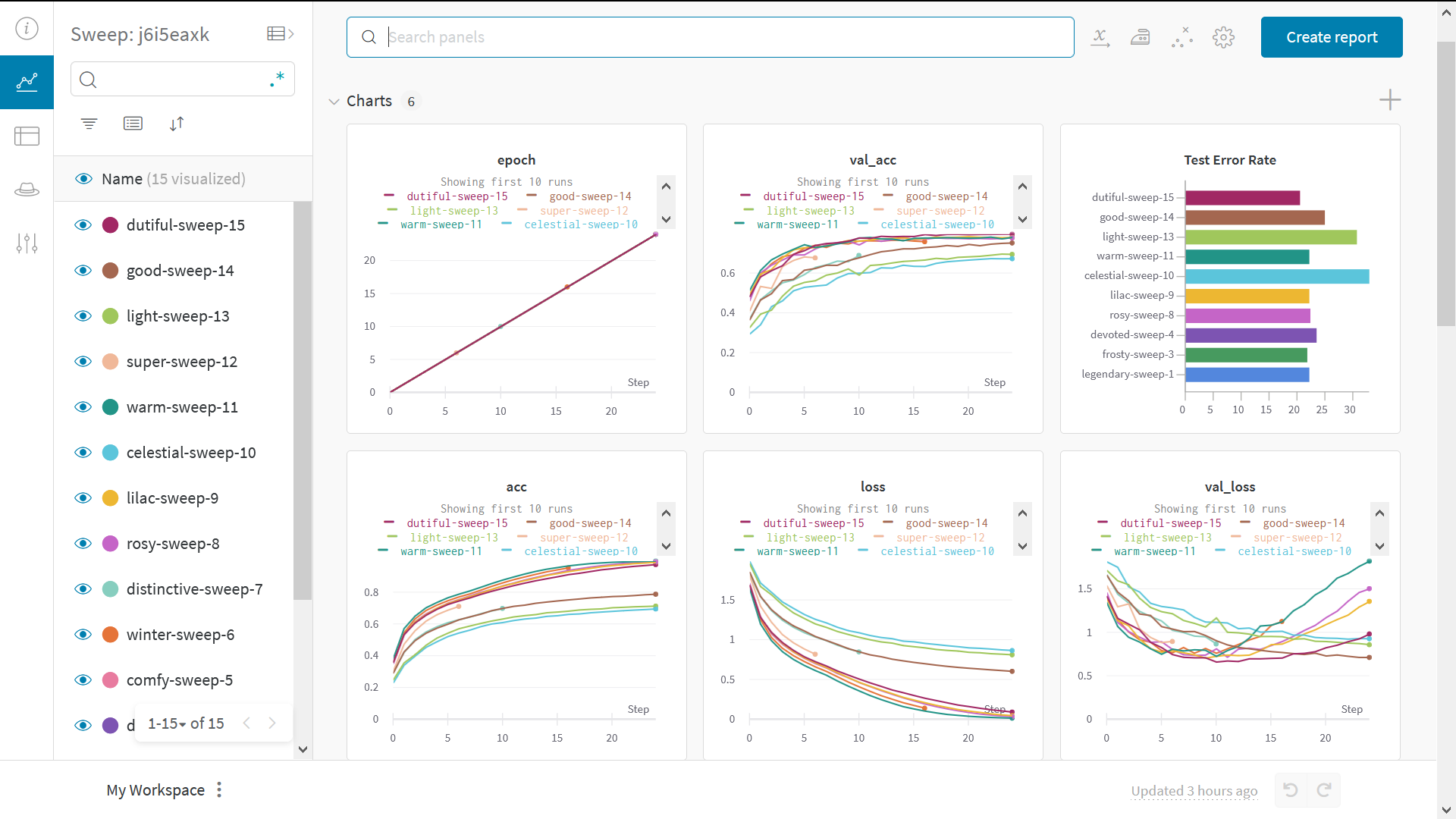
Tester des hyperparamètres avec Sweeps
- Définir le balayage : pour cela, créez un dictionnaire ou un fichier YAML qui spécifie les paramètres à explorer, la stratégie de recherche, la métrique d’optimisation, etc.
-
Initialiser le balayage :
sweep_id = wandb.sweep(sweep_config) -
Exécuter l’agent de balayage :
wandb.agent(sweep_id, function=train)
Galerie d’exemples
Configuration avancée
- Variables d’environnement : définissez des clés API dans les variables d’environnement pour pouvoir lancer des entraînements sur un cluster géré.
- Mode hors ligne : utilisez le mode
dryrunpour entraîner hors ligne et synchroniser les résultats plus tard. - Sur site : installez W&B dans un cloud privé ou sur des serveurs isolés du réseau au sein de votre propre infrastructure. Nous proposons des déploiements locaux pour tous les profils, du monde universitaire aux équipes d’entreprise.
- Sweeps : configurez rapidement une recherche d’hyperparamètres avec notre outil léger de réglage.