WandbLogger.
Intégrer Lightning
- Logger PyTorch
- Logger Fabric
Utilisation de wandb.log() : Le
WandbLogger envoie les journaux vers W&B en utilisant le global_step du Trainer. Si vous effectuez des appels supplémentaires à wandb.log directement dans votre code, n’utilisez pas l’argument step dans wandb.log().À la place, enregistrez le global_step du Trainer comme vos autres métriques :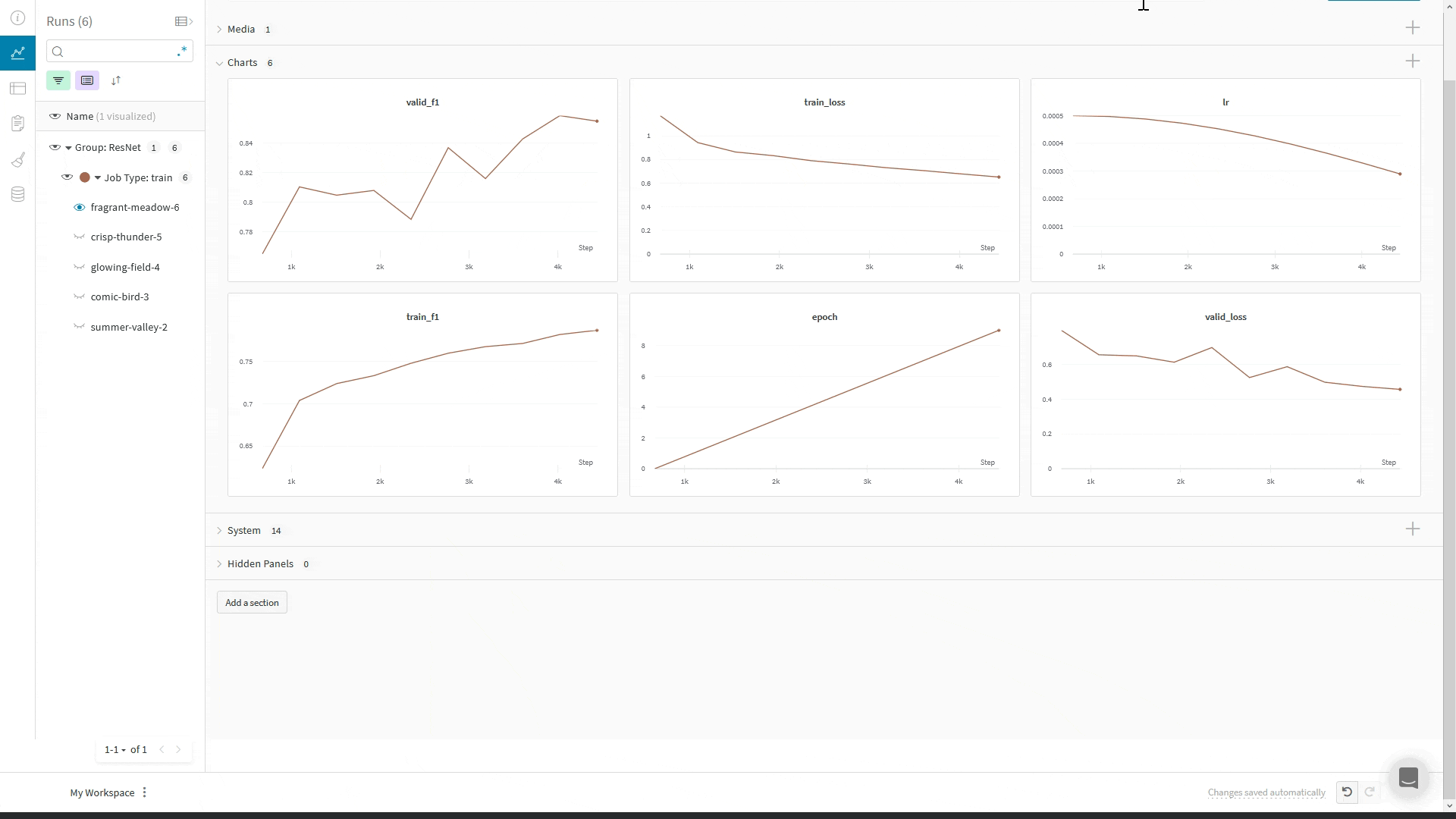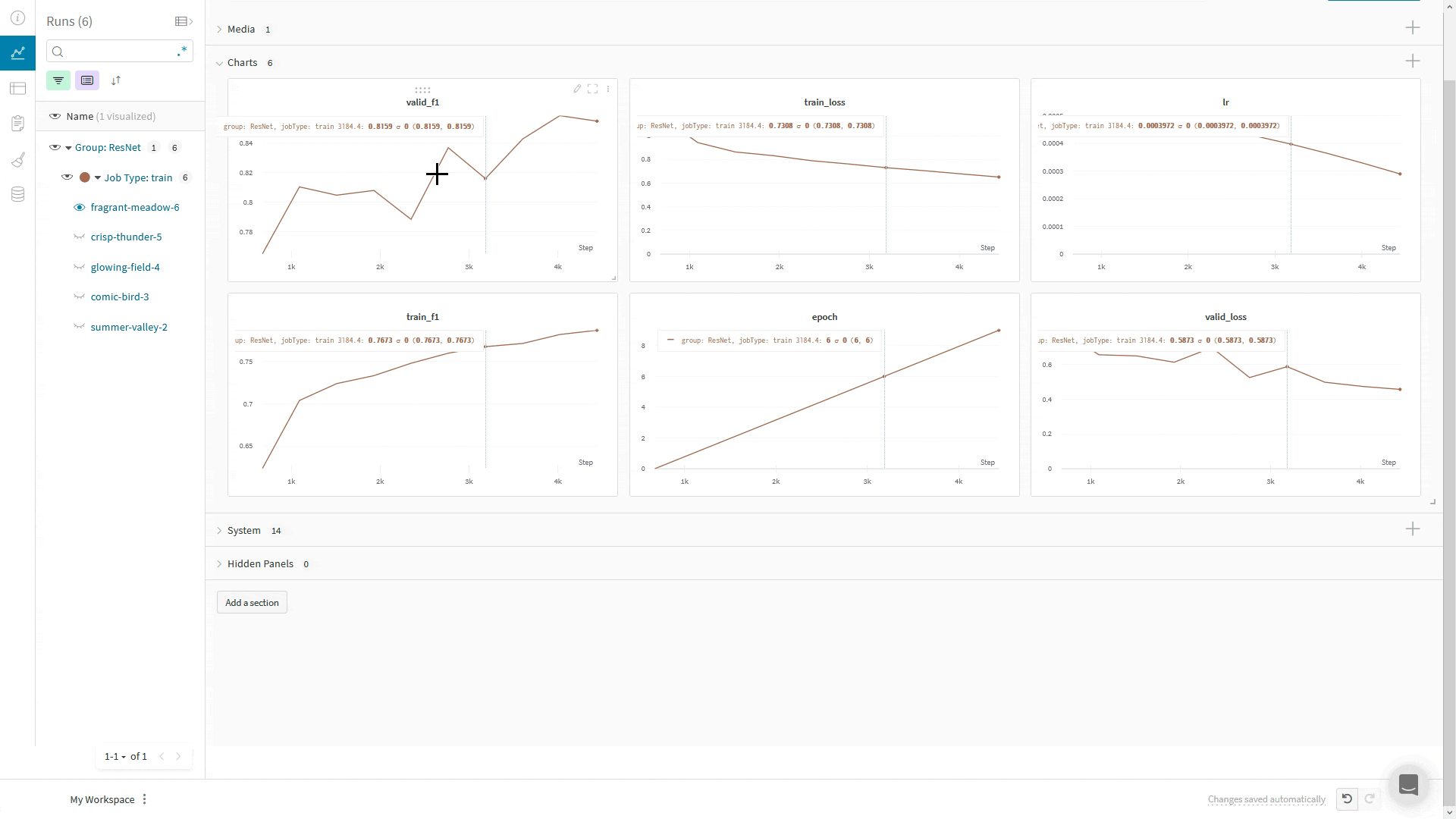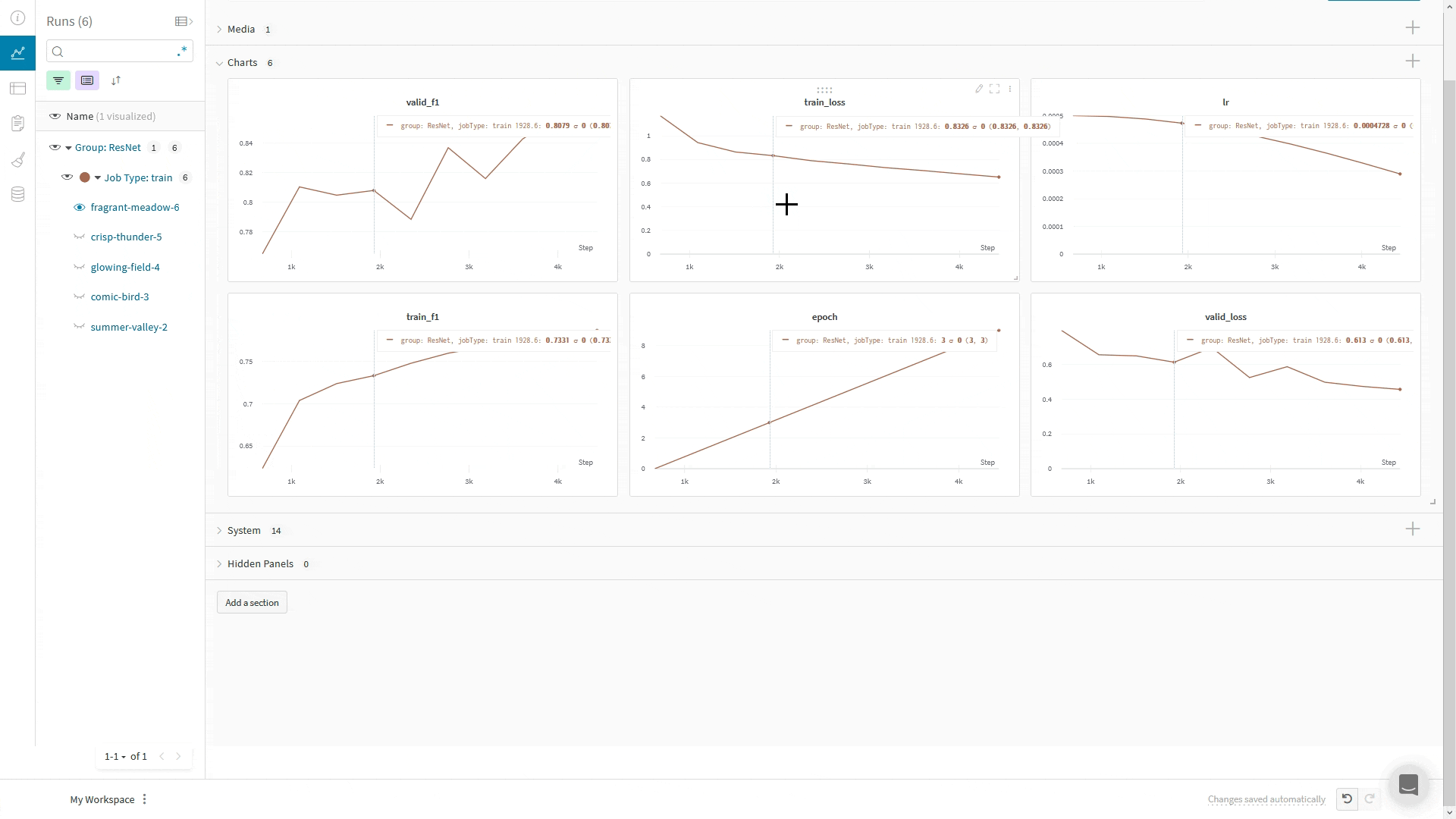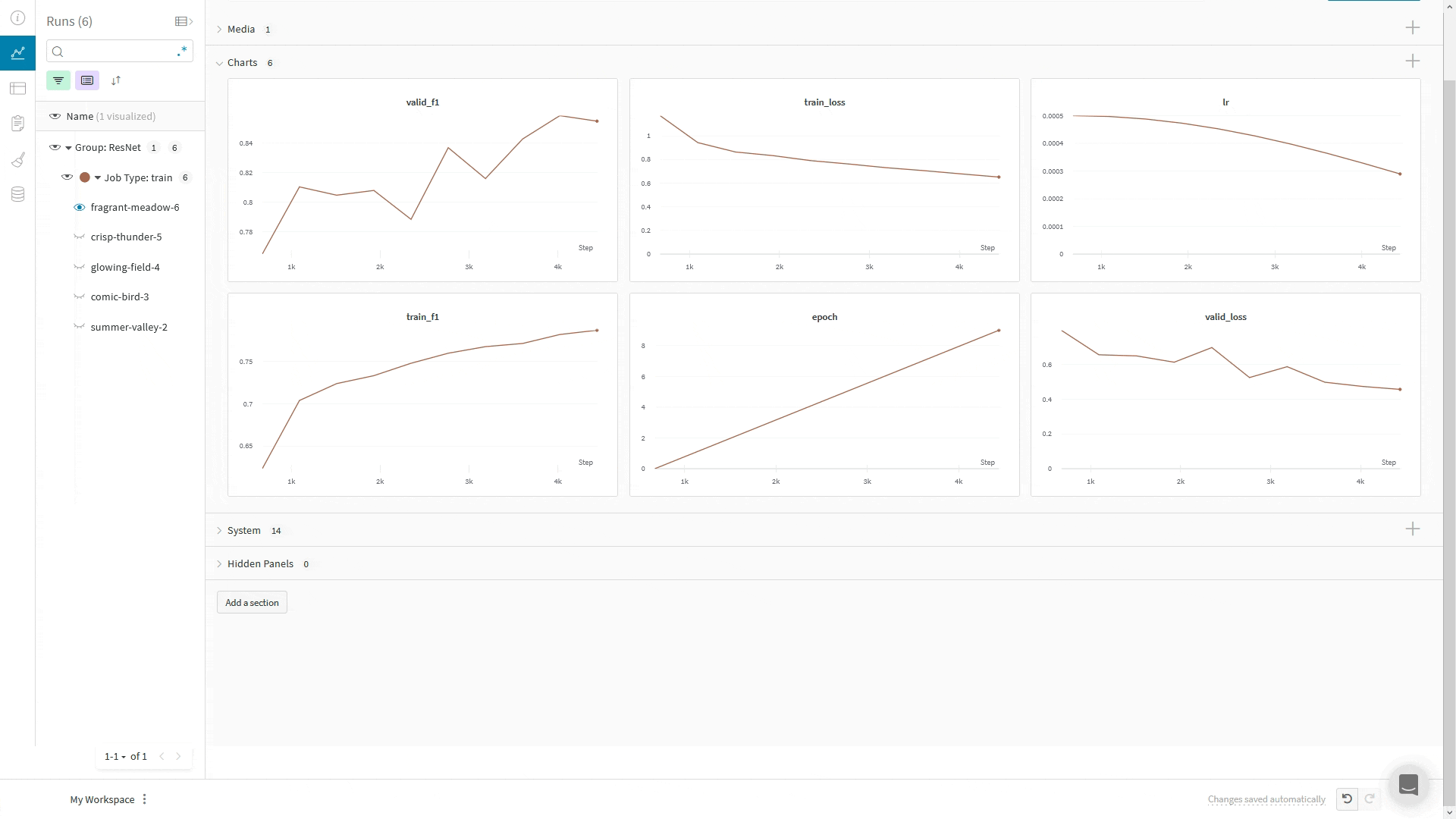
Inscrivez-vous et créez une clé API
Pour une méthode plus directe, créez une clé API en accédant directement aux Paramètres utilisateur. Copiez immédiatement la clé API nouvellement créée et conservez-la dans un endroit sûr, par exemple dans un gestionnaire de mots de passe.
- Cliquez sur l’icône de votre profil en haut à droite.
- Sélectionnez Paramètres utilisateur, puis faites défiler jusqu’à la section Clés API.
Installez la bibliothèque wandb et connectez-vous
wandb localement et vous connecter :
- Ligne de commande
- Python
- Python notebook
-
Définissez la variable d’environnement
WANDB_API_KEYsur votre clé API. -
Installez la bibliothèque
wandbet connectez-vous.
Utiliser le WandbLogger de PyTorch Lightning
WandbLogger pour consigner des métriques, ainsi que les poids du modèle, des médias, et bien plus encore.
Pour l’utiliser avec Lightning, instanciez WandbLogger, puis transmettez-le à Trainer ou à Fabric de Lightning.
- Logger PyTorch
- Logger Fabric
Arguments courants du logger
WandbLogger. Consultez la documentation de PyTorch Lightning pour en savoir plus sur tous les arguments du logger.
| Paramètre | Description |
|---|---|
project | Définit dans quel projet wandb journaliser |
name | Donne un nom à votre run wandb |
log_model | Journalise tous les modèles si log_model="all", ou à la fin de l’entraînement si log_model=True |
save_dir | Chemin où les données sont enregistrées |
Journalisez vos hyperparamètres
- Logger PyTorch
- Logger Fabric
Journalisez des paramètres de configuration supplémentaires
Journaliser les gradients, l’histogramme des paramètres et la topologie du modèle
wandblogger.watch() pour surveiller les gradients et les paramètres de votre modèle pendant l’entraînement. Voir la documentation de WandbLogger pour PyTorch Lightning
Journaliser des métriques
- Logger PyTorch
- Fabric Logger
Vous pouvez journaliser vos métriques dans W&B lorsque vous utilisez
WandbLogger en appelant self.log('my_metric_name', metric_vale) dans votre LightningModule, par exemple dans les méthodes training_step ou validation_step.L’extrait de code ci-dessous montre comment définir votre LightningModule pour journaliser vos métriques ainsi que les hyperparamètres de votre LightningModule. Cet exemple utilise la bibliothèque torchmetrics pour calculer vos métriques.Journaliser les valeurs min/max d’une métrique
define_metric de wandb, vous pouvez définir si vous souhaitez que votre métrique de synthèse W&B affiche la valeur minimale, maximale, moyenne ou la meilleure valeur pour cette métrique. Si define_metric _ n’est pas utilisé, la dernière valeur enregistrée apparaîtra dans vos métriques de synthèse. Voir la documentation de référence de define_metric ici et le guide ici pour en savoir plus.
Pour indiquer à W&B de suivre la précision de validation maximale dans la métrique de synthèse W&B, appelez wandb.define_metric une seule fois, au début de l’entraînement :
- Logger PyTorch
- Logger Fabric
Créer un point de contrôle d’un modèle
ModelCheckpoint et définissez l’argument log_model dans WandbLogger.
- Logger PyTorch
- Logger Fabric
- Via Logger
- Via wandb
- Logger PyTorch
- Logger Fabric
Journaliser des images, du texte et plus encore
WandbLogger fournit les méthodes log_image, log_text et log_table pour journaliser des médias.
Vous pouvez aussi appeler directement wandb.log ou trainer.logger.experiment.log pour journaliser d’autres types de médias comme Audio, les molécules, les nuages de points, les objets 3D, etc.
- Journaliser des images
- Journaliser du texte
- Journaliser des tableaux
WandbLogger. Dans cet exemple, nous journalisons un échantillon de nos images de validation et de nos prédictions :
Utiliser plusieurs GPU avec Lightning et W&B
wandb.run, et pour les processus de rang non nul : wandb.run = None. Cela peut faire échouer vos processus non nuls. Une telle situation peut vous placer dans un interblocage, car le processus de rang 0 attendra que les processus de rang non nul le rejoignent, alors qu’ils ont déjà planté.
Pour cette raison, faites attention à la façon dont vous configurez votre code d’entraînement. La méthode recommandée consiste à rendre votre code indépendant de l’objet wandb.run.
Exemples
Foire aux questions
Comment W&B s’intègre-t-il à Lightning ?
loggers, qui vous permet d’écrire une grande partie de votre code de journalisation de manière indépendante du framework. Les Logger sont transmis au Lightning Trainer et sont déclenchés par le riche système de hooks et de callbacks de cette API. Cela permet de bien séparer votre code de recherche du code d’ingénierie et de journalisation.
Que journalise l’intégration sans code supplémentaire ?
Que faire si j’ai besoin d’utiliser wandb.run dans ma configuration d’entraînement ?
os.environ["WANDB_DIR"] pour configurer le répertoire des points de contrôle du modèle. Ainsi, tout processus de rang non nul peut accéder à wandb.run.dir.