Une journalisation avancée en seulement deux lignes
Pour commencer
-
Installez
diffusers,transformers,accelerateetwandb.-
Ligne de commande :
-
Notebook :
-
Ligne de commande :
-
Utilisez
autologpour initialiser un run W&B et suivre automatiquement les entrées et les sorties de tous les appels de pipeline pris en charge. Vous pouvez appeler la fonctionautolog()avec le paramètreinit, qui accepte un dictionnaire de paramètres requis parwandb.init(). Lorsque vous appelezautolog(), un run W&B est initialisé et les entrées ainsi que les sorties de tous les appels de pipeline pris en charge sont automatiquement suivies.- Chaque appel de pipeline est suivi dans son propre tableau dans le Workspace, et les configurations associées à cet appel sont ajoutées à la liste des flux de travail dans la configuration de ce run.
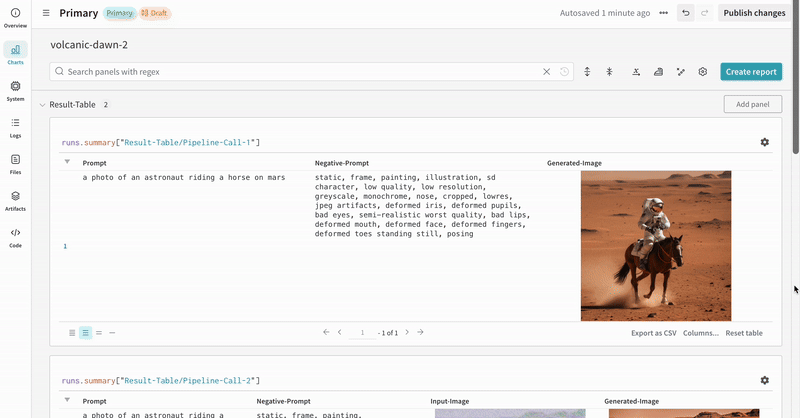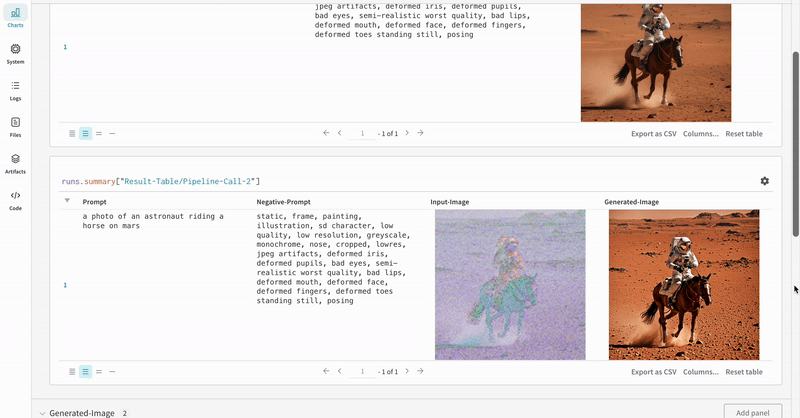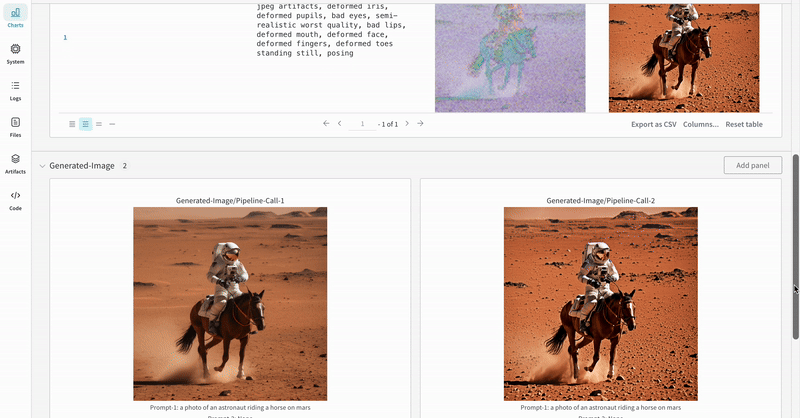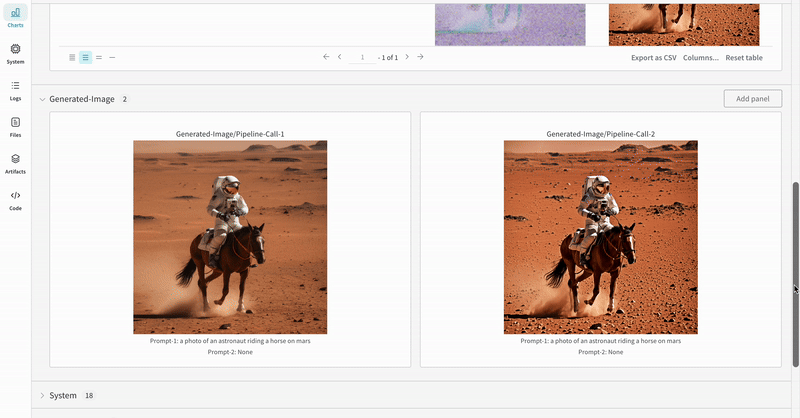
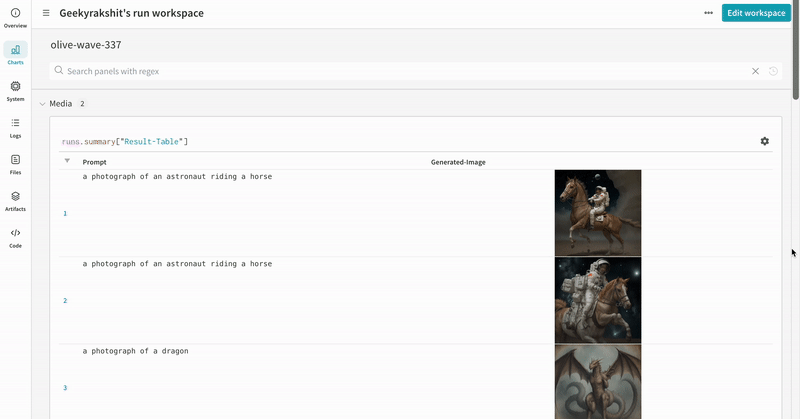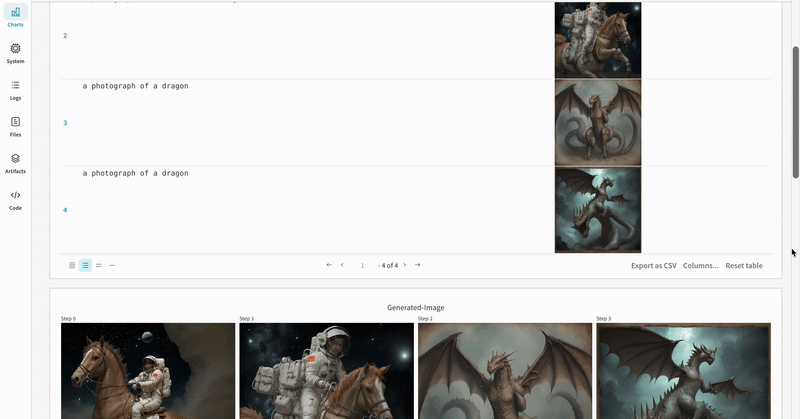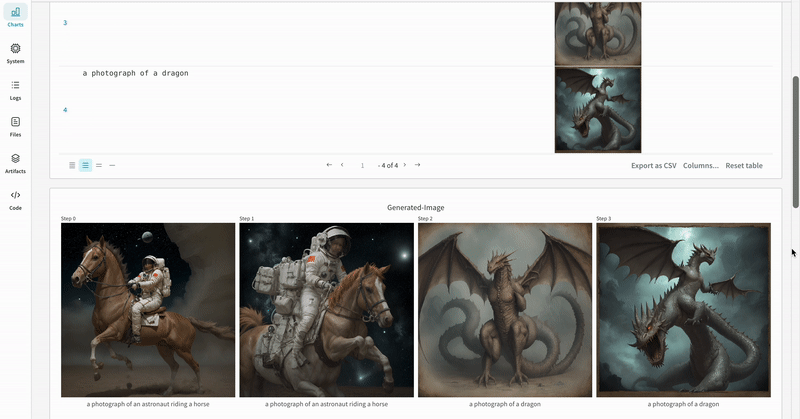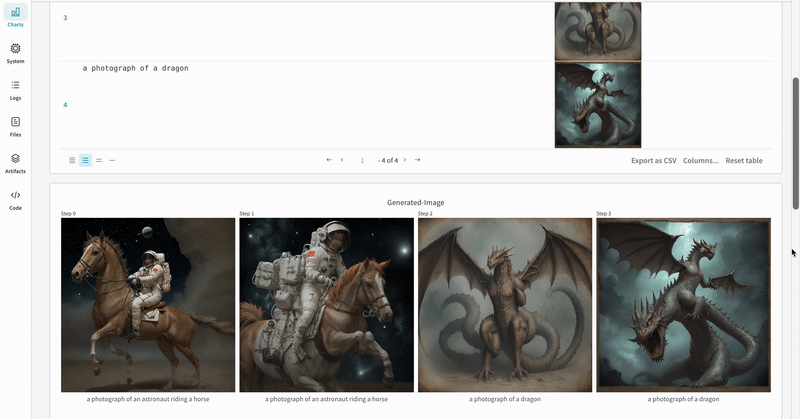
- Les prompts, les prompts négatifs et les médias générés sont enregistrés dans un
wandb.Table. - Toutes les autres configurations associées à l’expérience, y compris la seed et l’architecture du pipeline, sont stockées dans la section de configuration du run.
- Les médias générés pour chaque appel de pipeline sont également enregistrés dans les panneaux multimédias du run.
Vous trouverez une liste des appels de pipeline pris en charge. Si vous souhaitez demander une nouvelle fonctionnalité pour cette intégration ou signaler un bug associé, ouvrez une issue sur la page GitHub issues de W&B.
Exemples
Autologging
- Script
- Notebook
-
Les résultats d’une seule expérience :
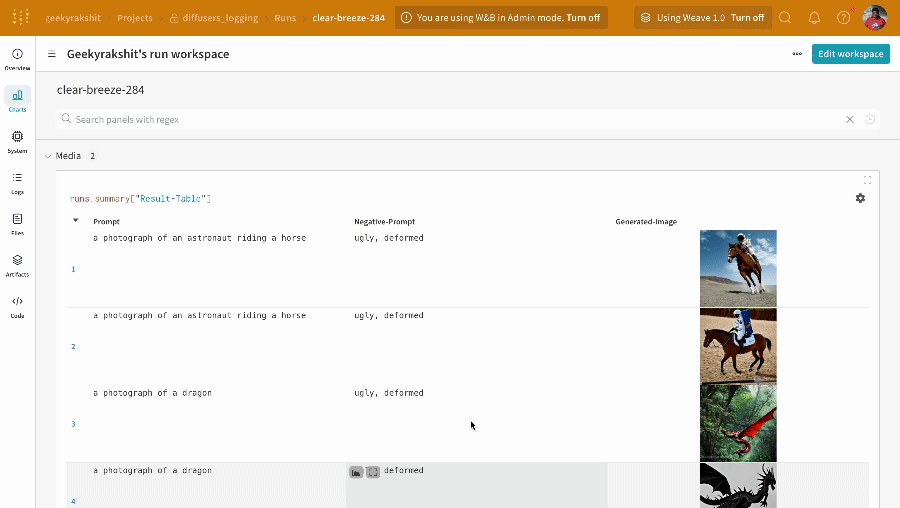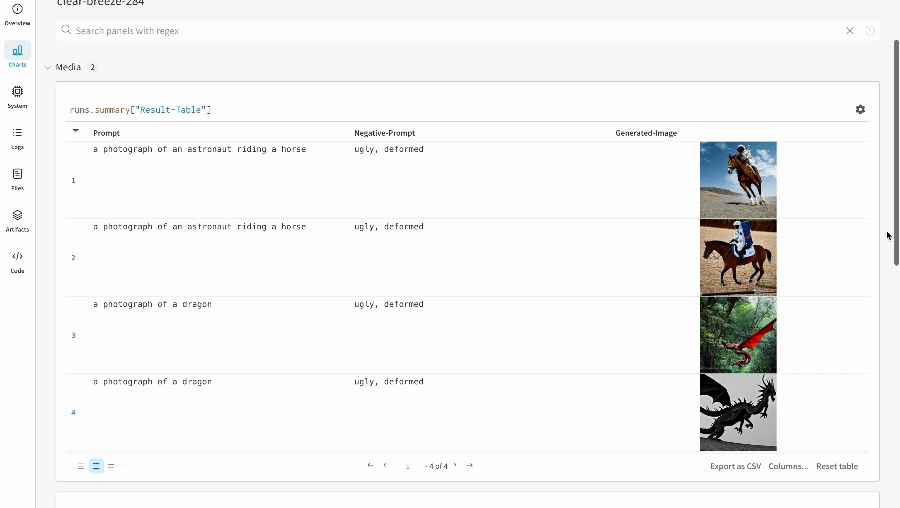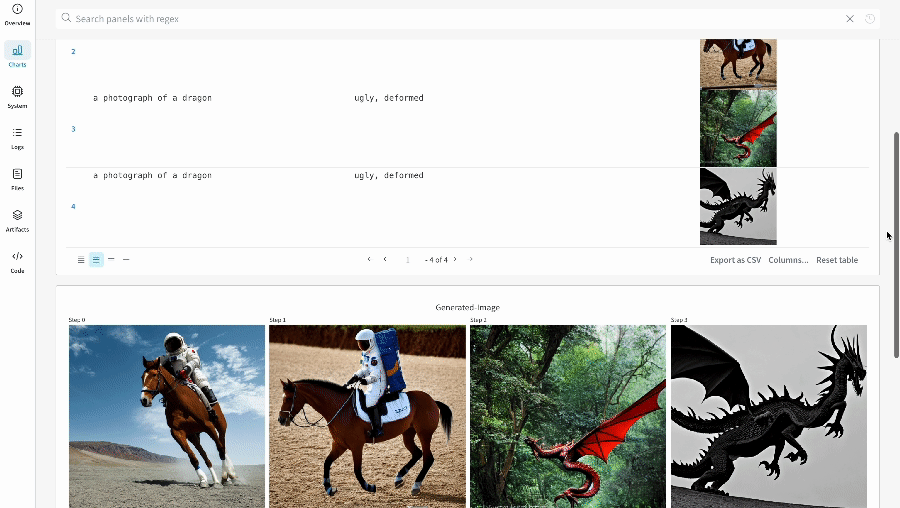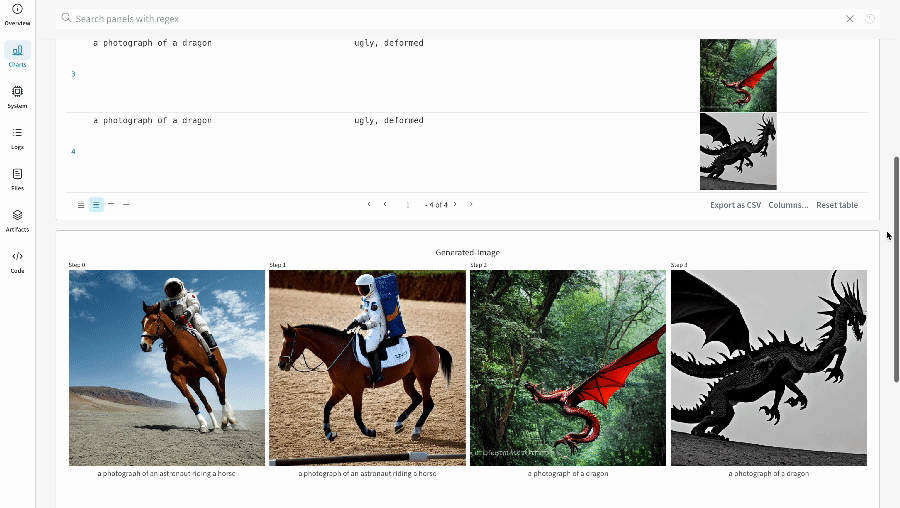
-
Les résultats de plusieurs expériences :
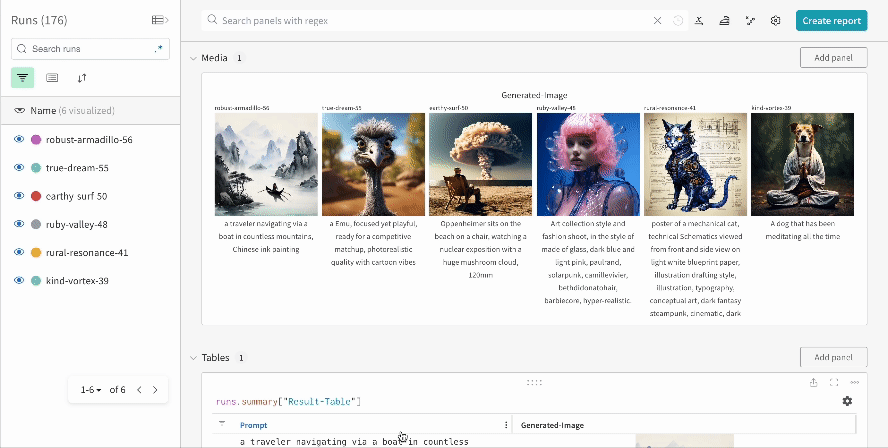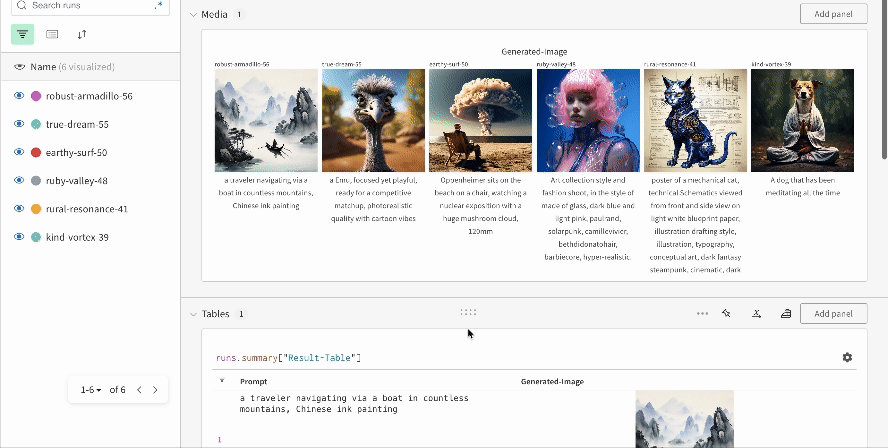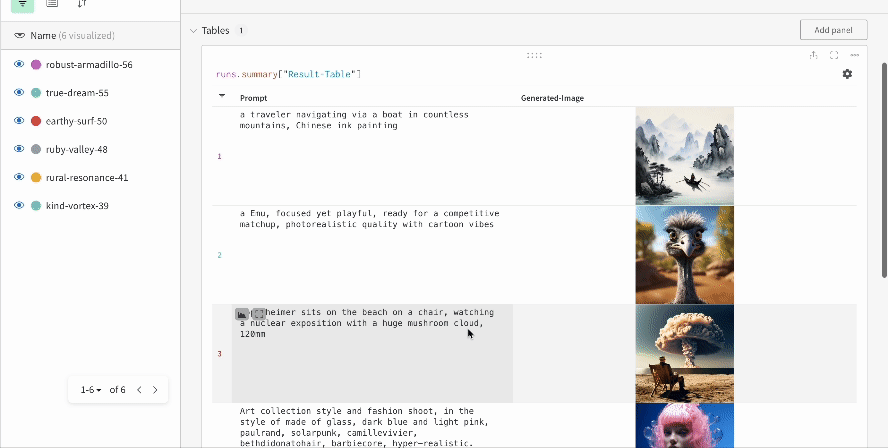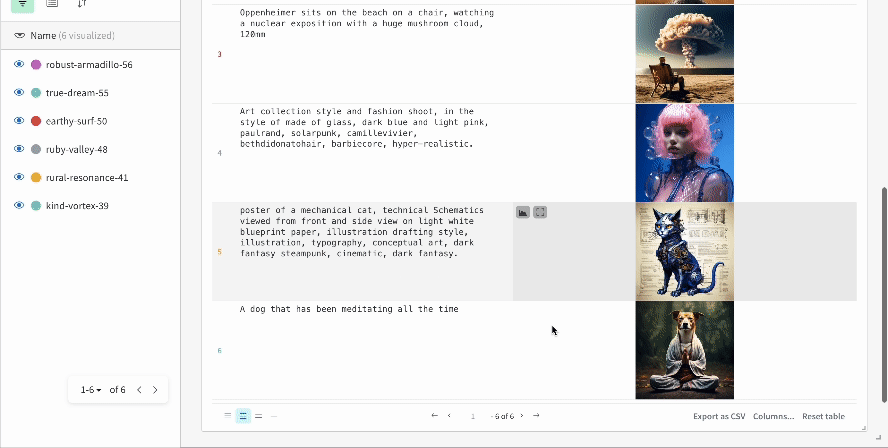
-
La configuration d’une expérience :
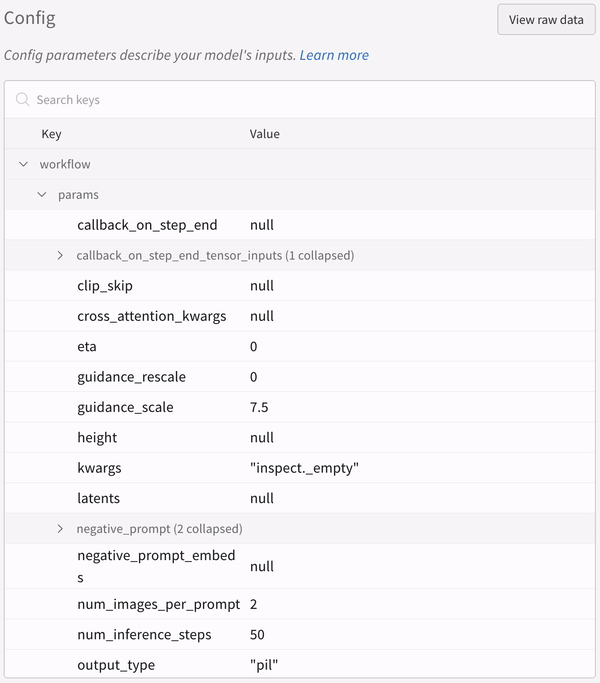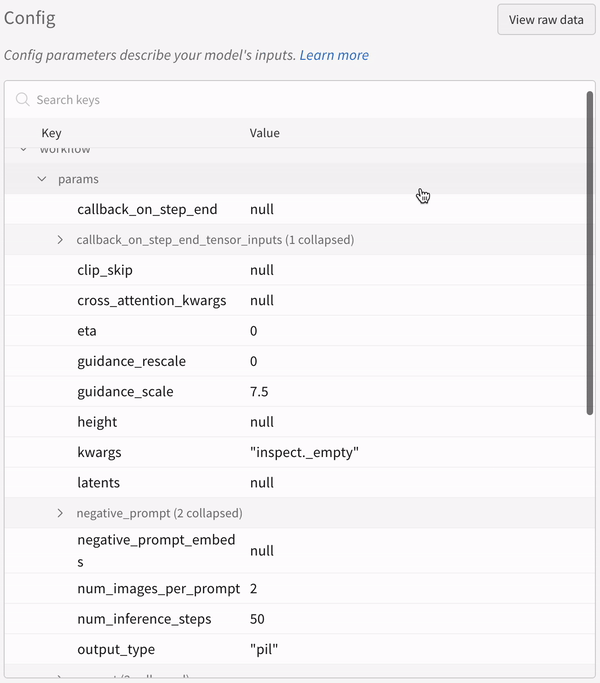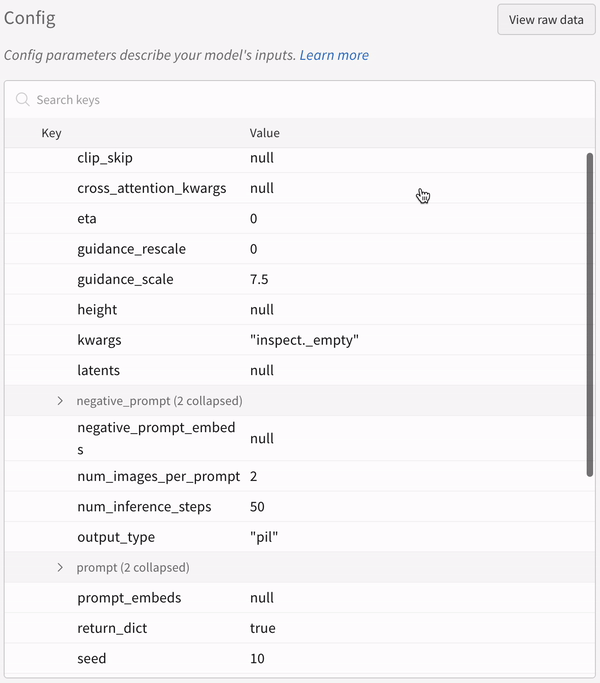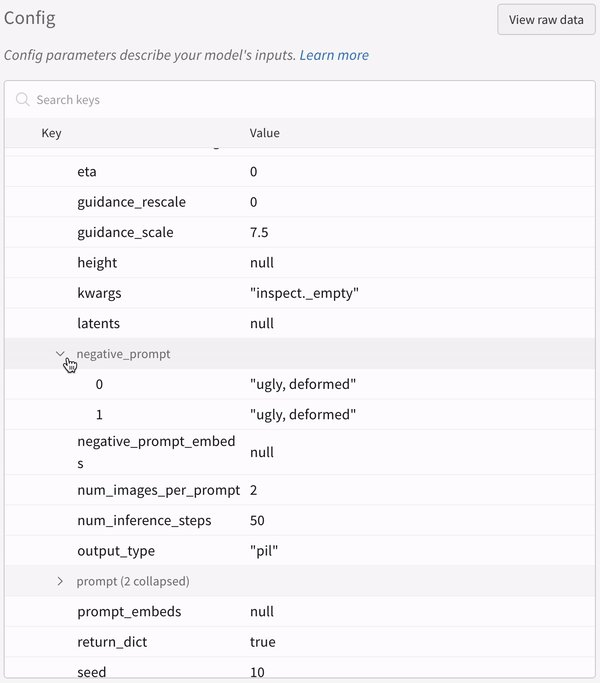
Vous devez appeler explicitement
wandb.Run.finish() lorsque vous exécutez le code dans un environnement de notebook IPython après avoir appelé le pipeline. Cela n’est pas nécessaire lors de l’exécution de scripts Python.Suivi des flux de travail à plusieurs pipelines
StableDiffusionXLPipeline sont affinées par le refiner correspondant.
- Script en Python
- Notebook
- Exemple d’expérience Stable Diffusion XL + Refiner :