Pourquoi utiliser W&B ?

- Tableau de bord unifié : dépôt central pour toutes les métriques et prédictions de votre modèle
- Léger : aucune modification du code n’est nécessaire pour intégrer Hugging Face
- Accessible : gratuit pour les particuliers et les équipes universitaires
- Sécurisé : tous les projets sont privés par défaut
- Fiable : utilisé par des équipes de machine learning chez OpenAI, Toyota, Lyft, et bien d’autres
Installer, importer et se connecter
- Hugging Face Transformers: Modèles et jeux de données pour le traitement du langage naturel
- W&B: Suivi des expériences et visualisation
- GLUE dataset: Jeu de données de référence pour la compréhension du langage
- GLUE script: Script d’entraînement du modèle pour la classification de séquences
Saisissez votre clé API
Entraîner le modèle
Visualisez les résultats dans le tableau de bord
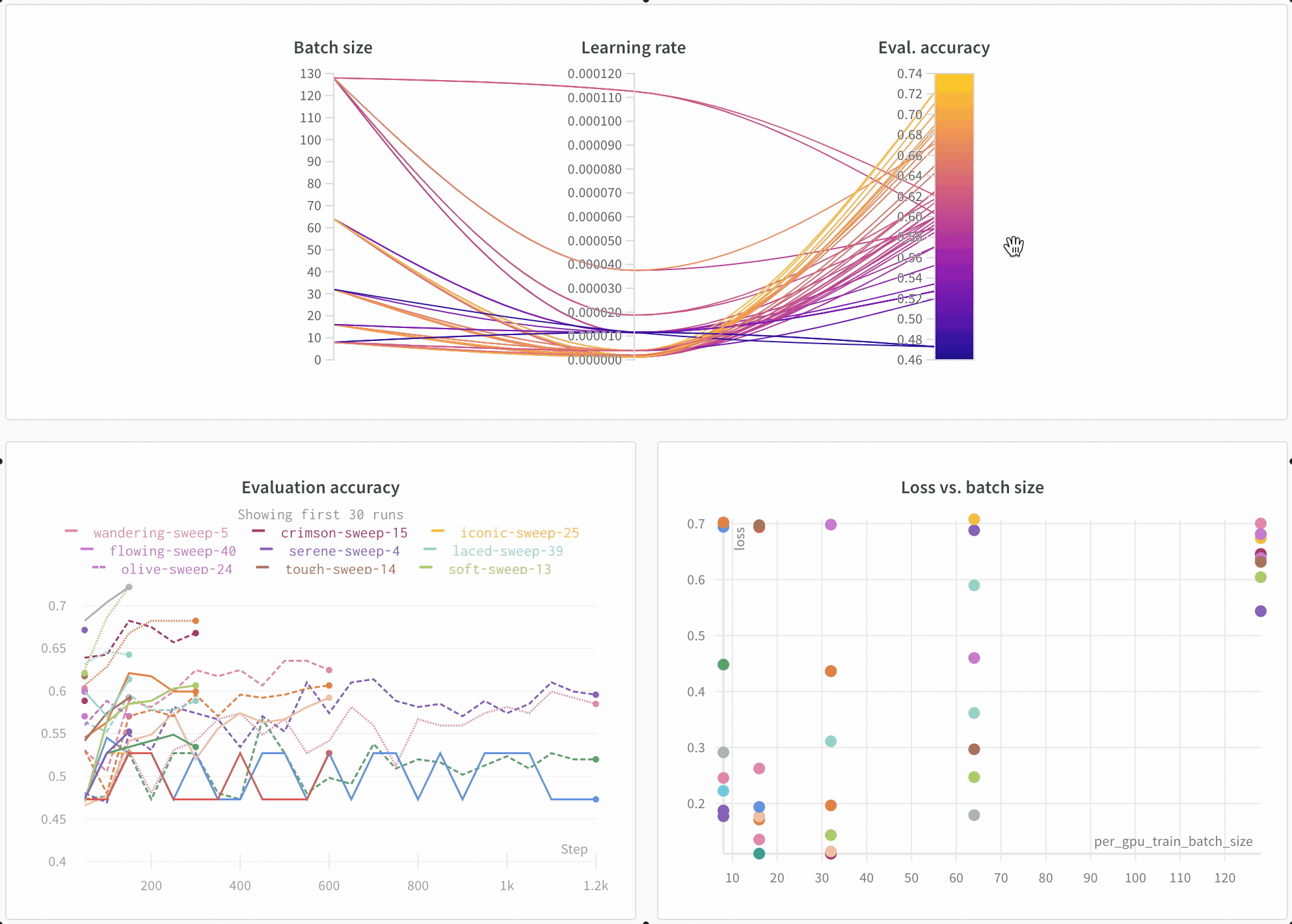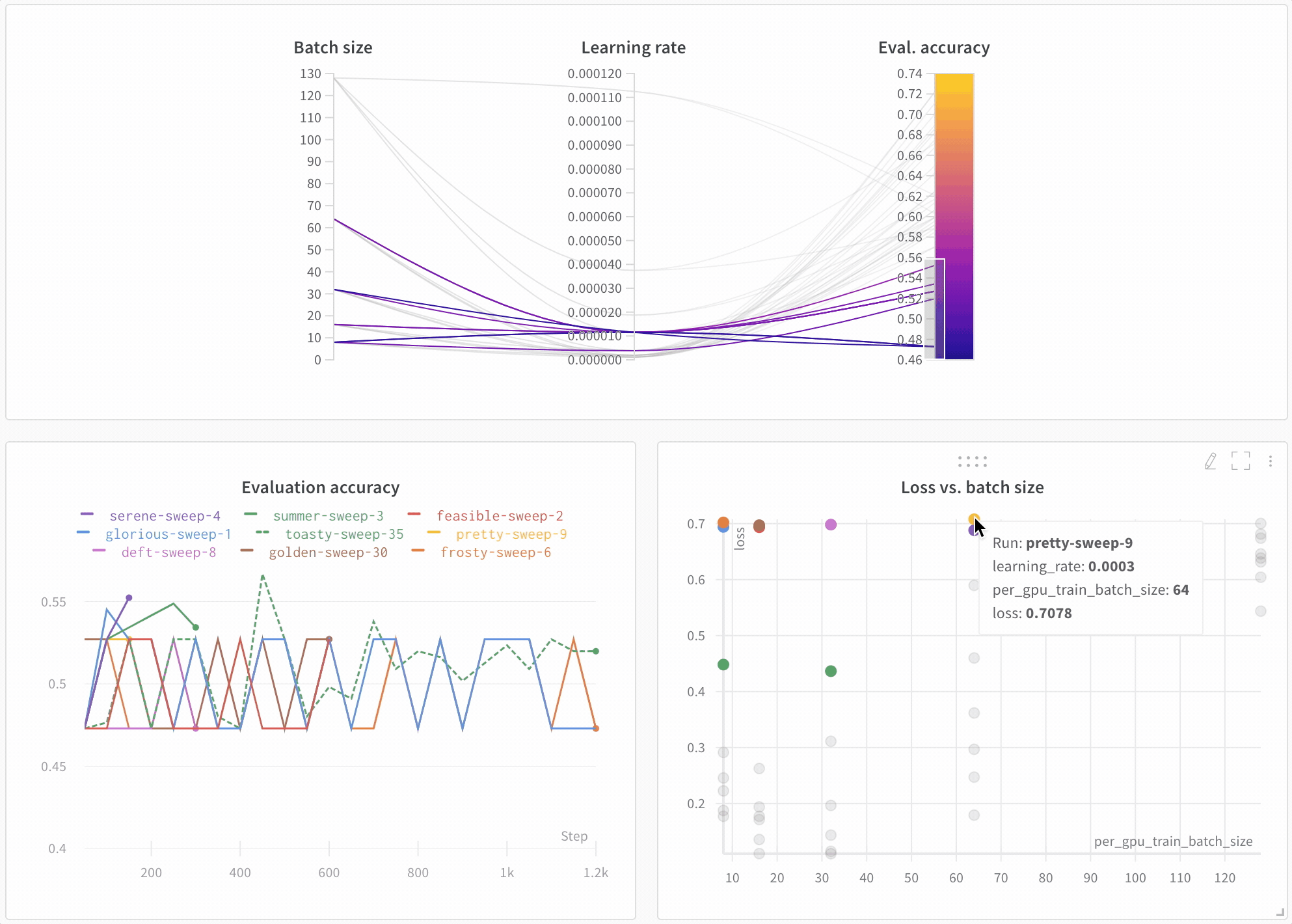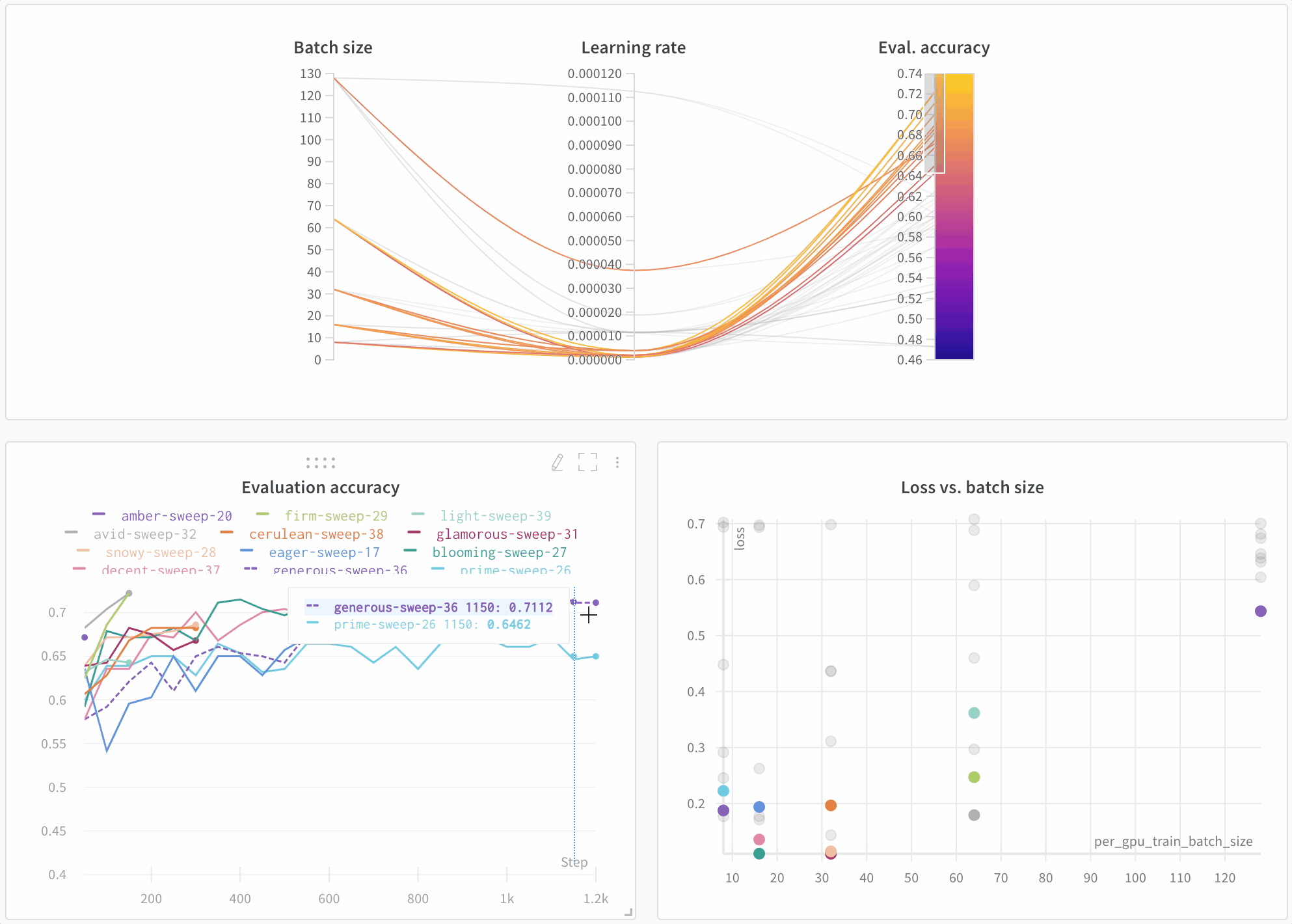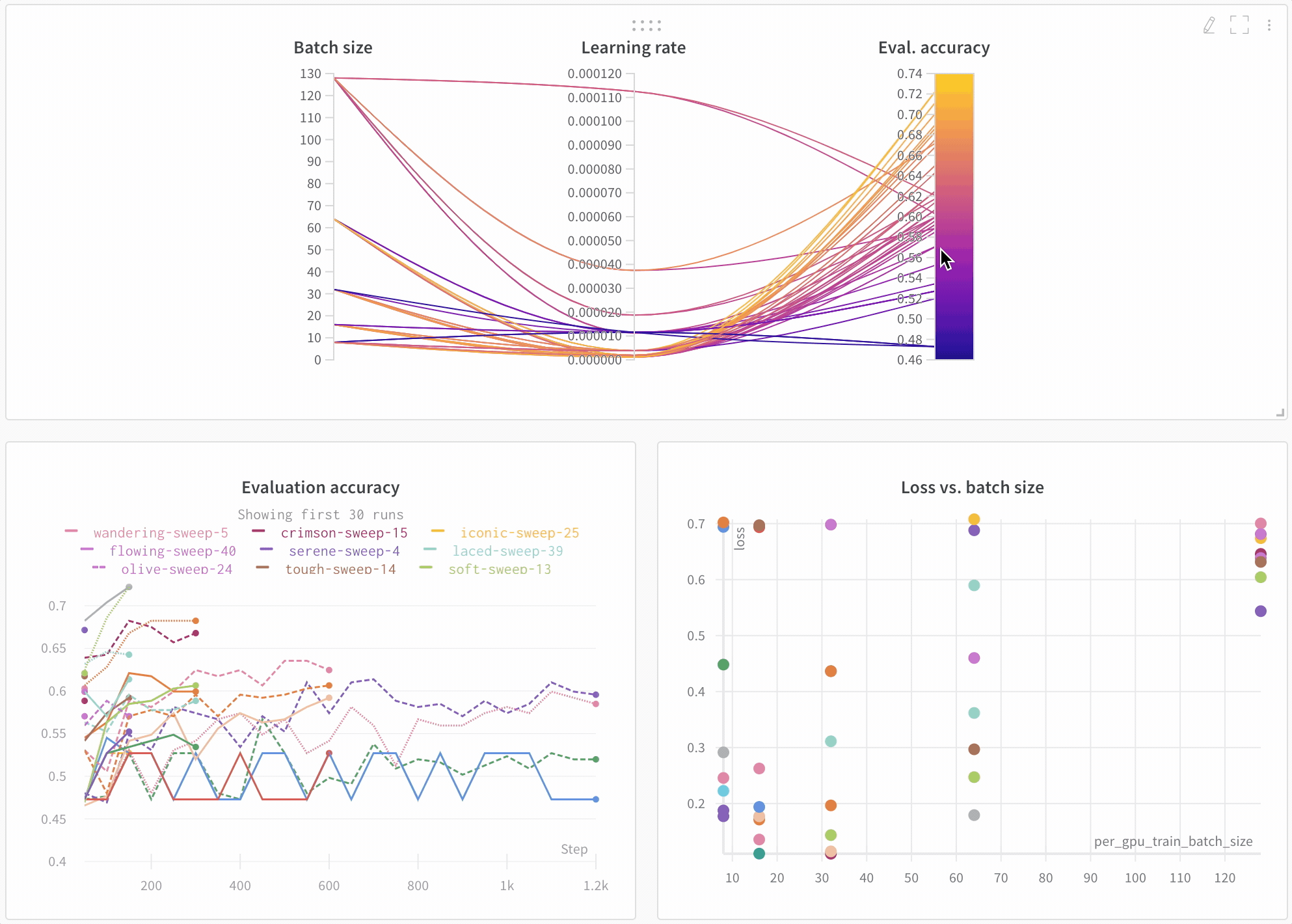
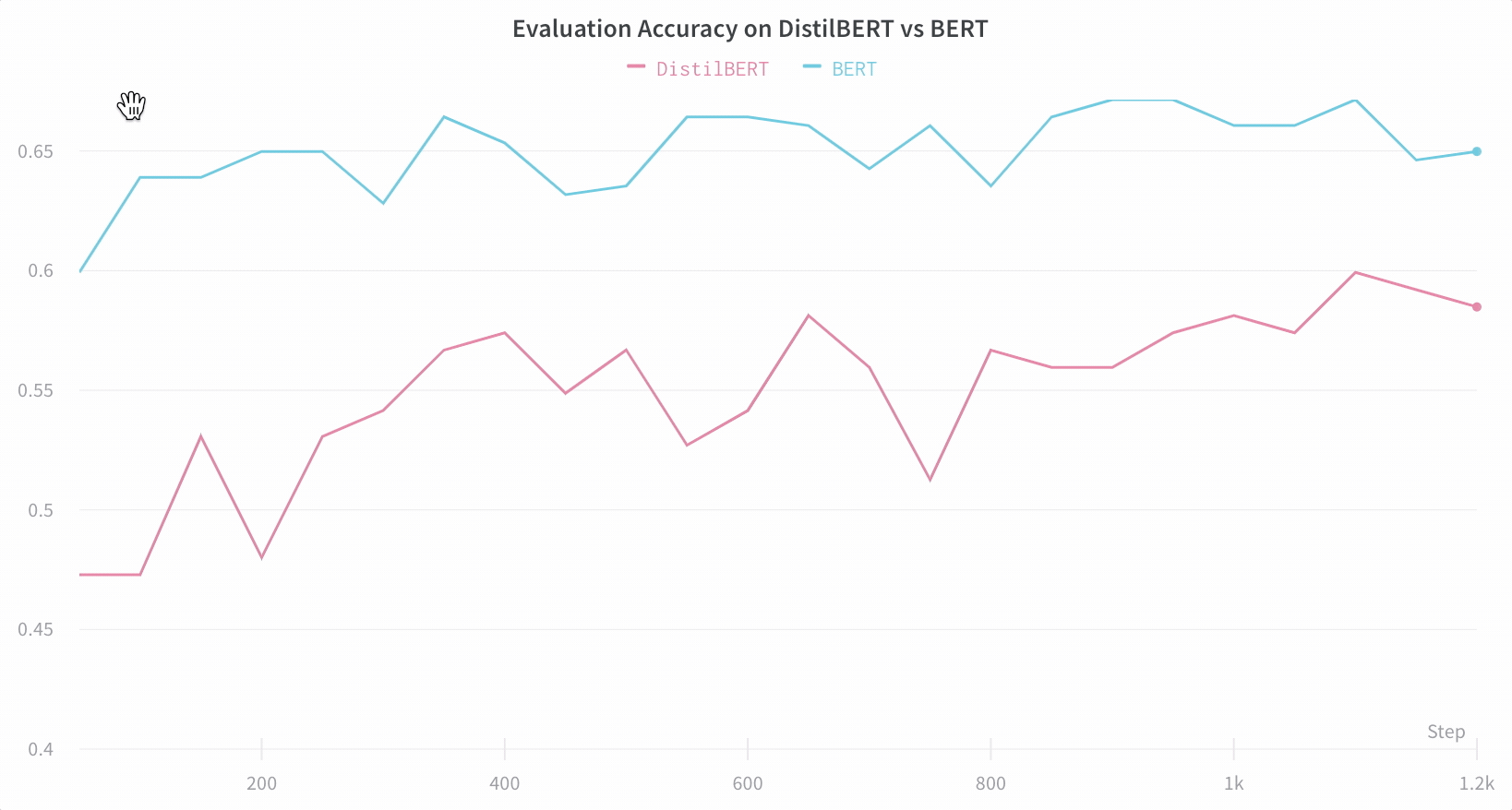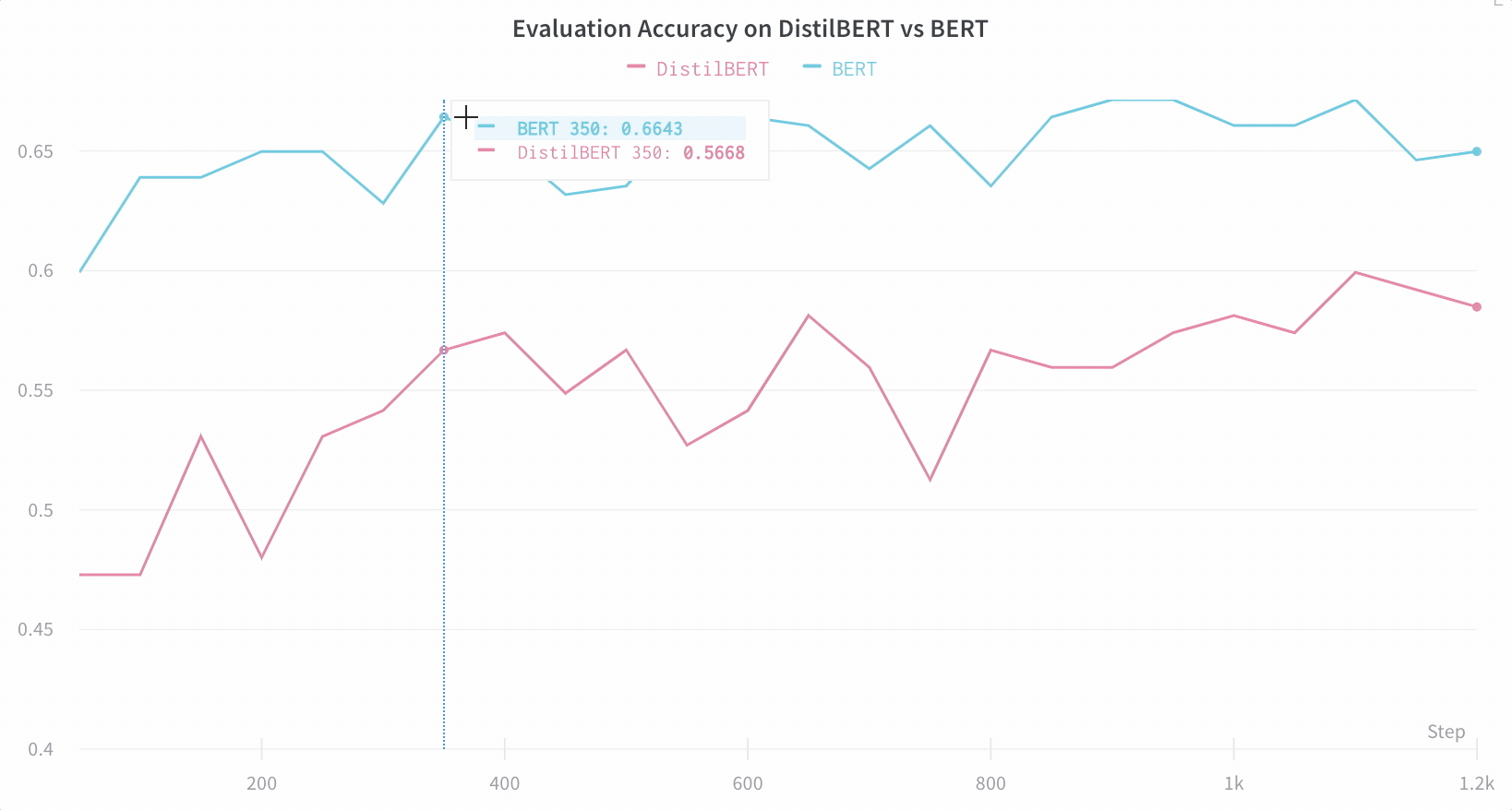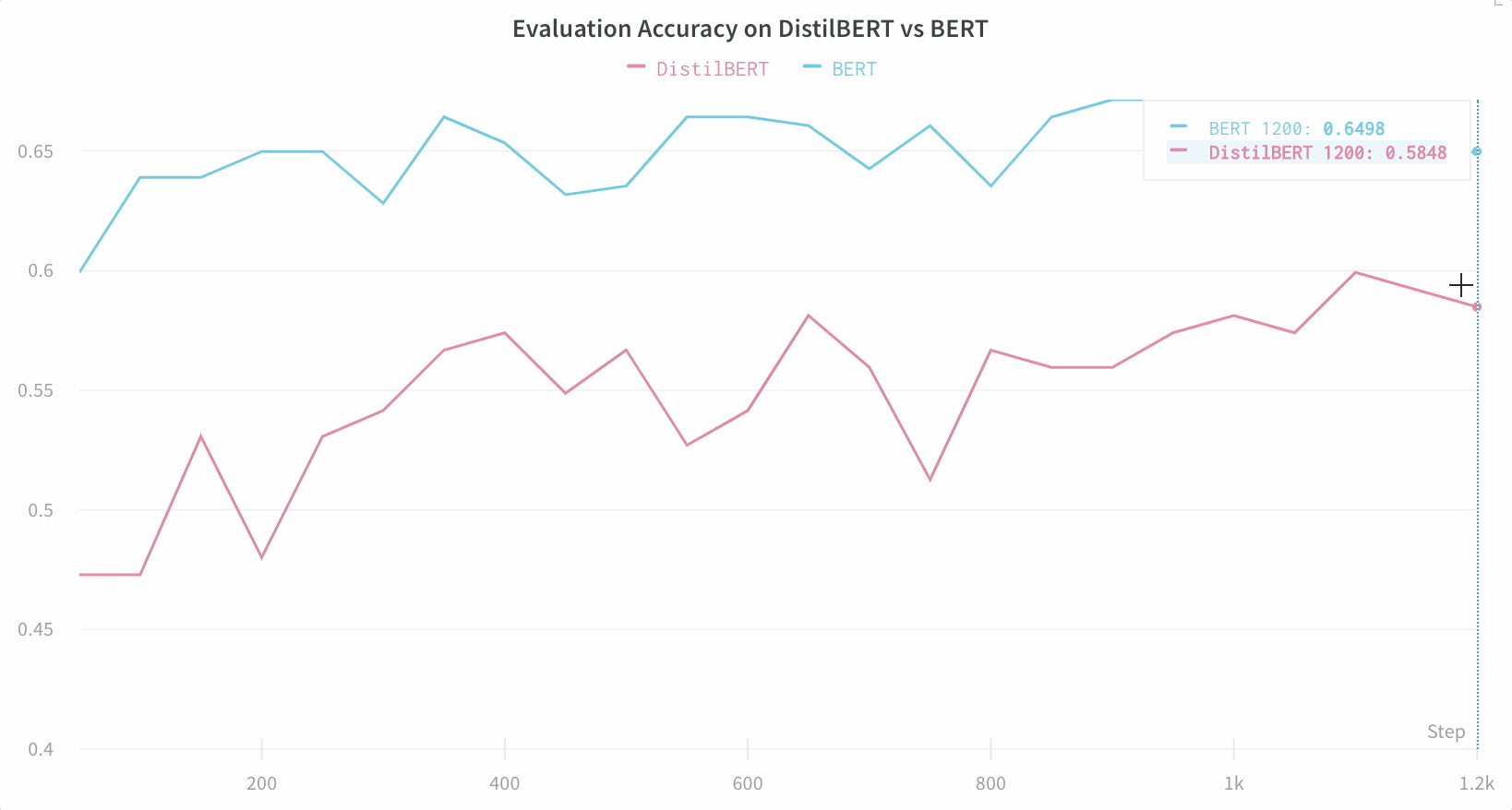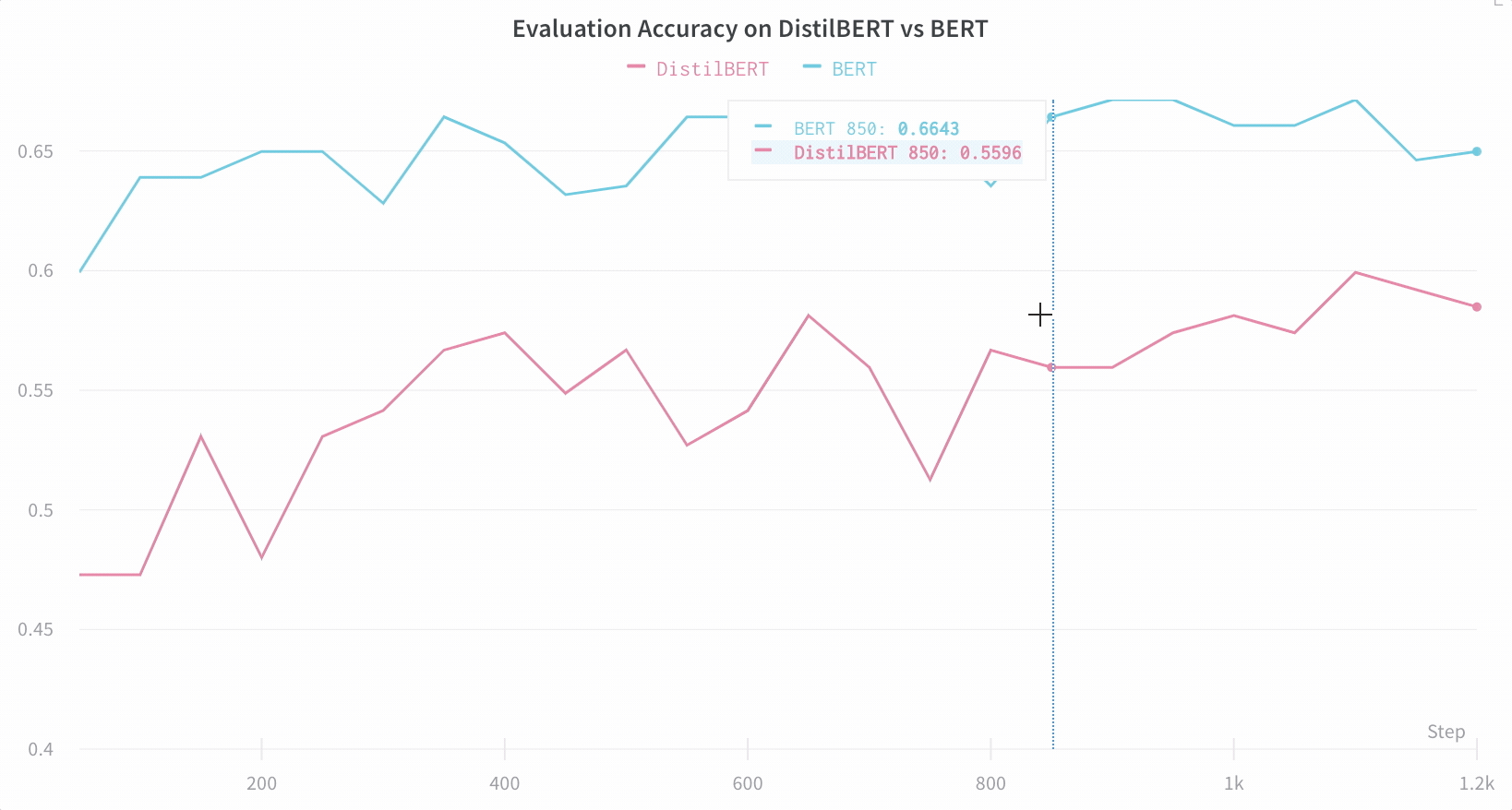
Suivez automatiquement les informations essentielles
- Hyperparamètres : les paramètres de votre modèle sont enregistrés dans Config
- Métriques du modèle : les séries temporelles de métriques reçues en continu sont enregistrées dans Log
- Journaux du terminal : les sorties de la ligne de commande sont enregistrées et disponibles dans un onglet
- Métriques système : utilisation du GPU et du CPU, mémoire, température, etc.