- Python
- TypeScript
Scorer는 평가 시
weave.Evaluation 객체에 전달됩니다. Weave에는 두 가지 종류의 Scorer가 있습니다.- 함수 기반 Scorer:
@weave.op으로 데코레이트된 간단한 Python 함수입니다. - 클래스 기반 Scorer: 더 복잡한 평가를 위해
weave.Scorer를 상속하는 Python 클래스입니다.
나만의 Scorer 만들기
함수 기반 Scorer
- Python
- TypeScript
@weave.op 데코레이터가 적용되어 사전을 반환하는 함수입니다. 다음과 같은 간단한 평가에 적합합니다:evaluate_uppercase는 텍스트가 모두 대문자인지 확인합니다.클래스 기반 Scorer
- Python
- TypeScript
더 고급 평가가 필요할 때, 특히 추가 Scorer 메타데이터를 추적하거나 LLM 평가자에 대해 다른 프롬프트를 시도하거나 여러 번 함수를 호출해야 하는 경우에는 이 클래스는 원문과 비교하여 요약의 품질을 평가합니다.
Scorer 클래스를 사용할 수 있습니다.요구 사항:weave.Scorer를 상속합니다.@weave.op데코레이터가 적용된score메서드를 정의합니다.score메서드는 반드시 사전을 반환해야 합니다.
Scorer가 동작하는 방식
Scorer 키워드 인자
- Python
- TypeScript
Scorer는 AI 시스템의 출력과 데이터셋 행의 입력 데이터를 모두 사용할 수 있습니다.Weave
때로는 이제
- Input: Scorer에서 “label” 또는 “target” 컬럼 같은 데이터셋 행의 데이터를 사용하려면, scorer 정의에
label또는target키워드 인자를 추가해 해당 데이터를 scorer에서 사용할 수 있게 하면 됩니다.
score 클래스 메서드)는 다음과 같은 형태의 파라미터 목록을 갖습니다:Evaluation이 실행되면, AI 시스템의 출력은 output 파라미터로 전달됩니다. Evaluation은 또한 추가 scorer 인자의 이름을 데이터셋 컬럼 이름과 자동으로 매칭하려고 시도합니다. Scorer 인자나 데이터셋 컬럼을 커스터마이즈하기 어렵다면, 컬럼 매핑을 사용할 수 있습니다. 자세한 내용은 아래를 참조하세요.- Output: AI 시스템의 출력을 사용하려면 scorer 함수의 시그니처에
output파라미터를 포함하세요.
column_map으로 컬럼 이름 매핑하기
때로는 score 메서드의 인자 이름이 데이터셋의 컬럼 이름과 일치하지 않을 수 있습니다. 이때는 column_map을 사용해 해결할 수 있습니다.클래스 기반 scorer를 사용하는 경우, scorer 클래스를 초기화할 때 Scorer의 column_map 속성에 사전을 전달하세요. 이 사전은 {scorer_keyword_argument: dataset_column_name} 형식으로 score 메서드의 인자 이름을 데이터셋 컬럼 이름에 매핑합니다.예시:score 메서드의 text 인자는 news_article 데이터셋 컬럼의 값을 받게 됩니다.참고:- 컬럼을 매핑하는 또 다른 동등한 방법은
Scorer를 상속(subclass)한 뒤, 컬럼을 명시적으로 매핑하도록score메서드를 오버로드하는 것입니다.
스코어링 프롬프트에서 op의 변수에 접근하기
| Variable | Description |
|---|---|
{article} | 입력 인수 article의 값 |
{max_length} | 입력 인수 max_length의 값 |
{inputs} | 모든 입력 인수를 포함한 JSON 사전 |
{output} | op이 반환한 결과 |
스코어러의 최종 요약
- Python
- TypeScript
평가 시 스코어러는 데이터셋의 각 행에 대해 계산됩니다. 평가에 대한 최종 점수를 제공하기 위해, 출력 타입에 따라 동작하는
auto_summarize를 제공합니다.- 수치형 컬럼에는 평균이 계산됩니다.
- 불리언 컬럼에는 개수와 비율이 계산됩니다.
- 그 외 컬럼 타입은 무시됩니다.
Scorer 클래스의 summarize 메서드를 오버라이드하여 최종 점수를 계산하는 방식을 직접 정의할 수 있습니다. summarize 함수는 다음을 기대합니다.- 단일 파라미터
score_rows: 사전들의 리스트로, 각 사전에는 데이터셋의 단일 행에 대해score메서드가 반환한 점수가 들어 있습니다. - 요약된 점수가 들어 있는 사전을 반환해야 합니다.
이 예시에서 기본 auto_summarize는 True의 개수와 비율을 반환했을 것입니다.
더 자세히 알고 싶다면 CorrectnessLLMJudge의 구현을 참고하십시오.호출에 Scorer 적용하기
.call() 메서드를 사용해야 합니다. 이를 통해 Weave의 데이터베이스에서 특정 호출과 scorer 결과를 연결할 수 있습니다.
.call() 메서드 사용 방법에 대한 자세한 내용은 Calling Ops 가이드를 참고하세요.
- Python
- TypeScript
기본 예제는 다음과 같습니다:동일한 호출에 여러 scorer를 적용할 수도 있습니다:참고:
- scorer 결과는 Weave의 데이터베이스에 자동으로 저장됩니다.
- scorer는 메인 연산이 완료된 이후 비동기적으로 실행됩니다.
- UI에서 scorer 결과를 확인하거나 API를 통해 조회할 수 있습니다.
preprocess_model_input 사용하기
preprocess_model_input 파라미터를 사용할 수 있습니다.
사용 방법과 예시는 평가 전에 데이터셋 행을 포맷하기 위해 preprocess_model_input 사용하기를 참고하세요.
점수 분석
단일 호출 점수 분석
단일 Call API
get_call 메서드를 사용합니다.
단일 Call UI
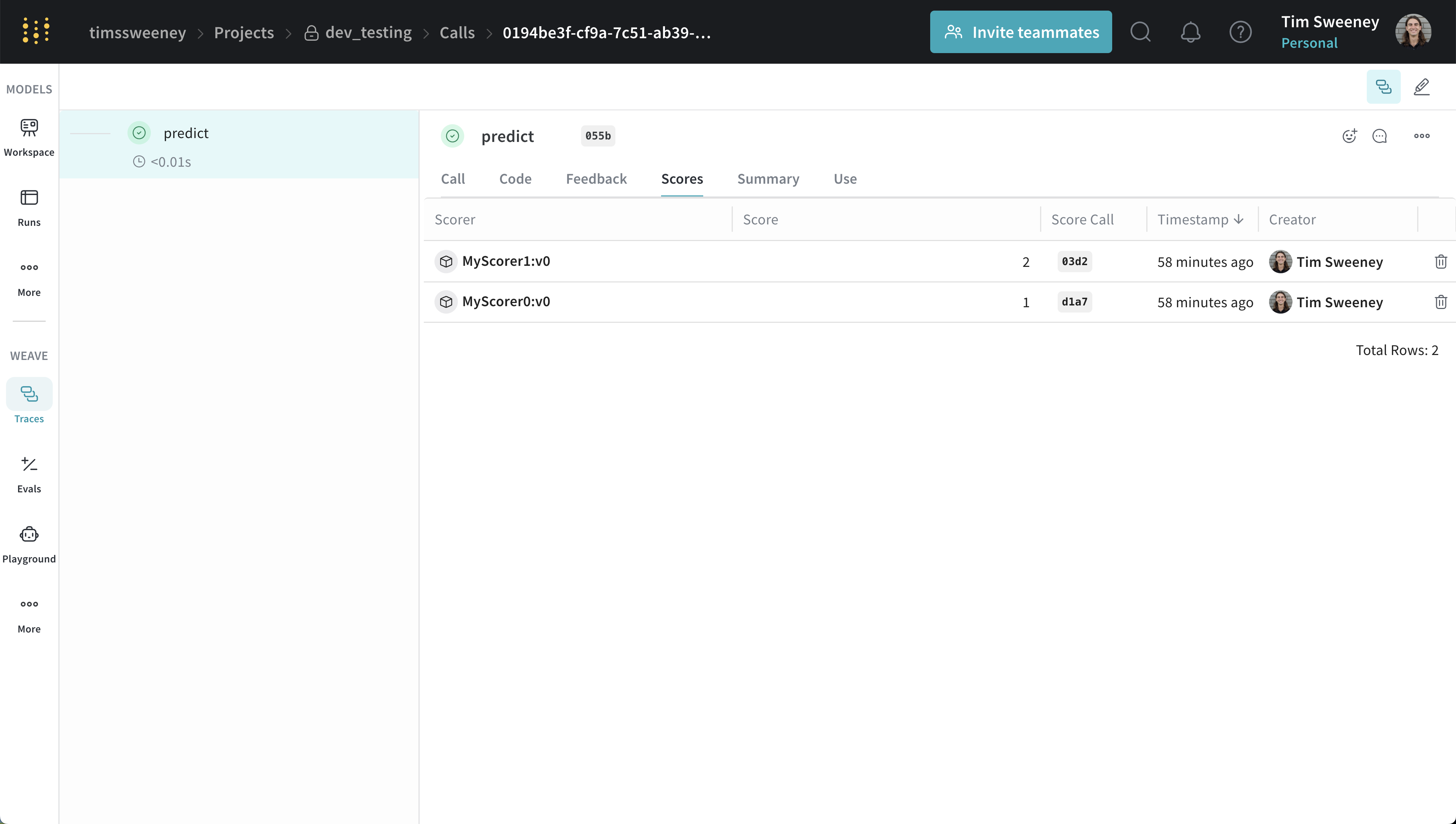
여러 호출의 점수 분석
Multiple Calls API
get_calls 메서드를 사용합니다.
다중 호출 UI
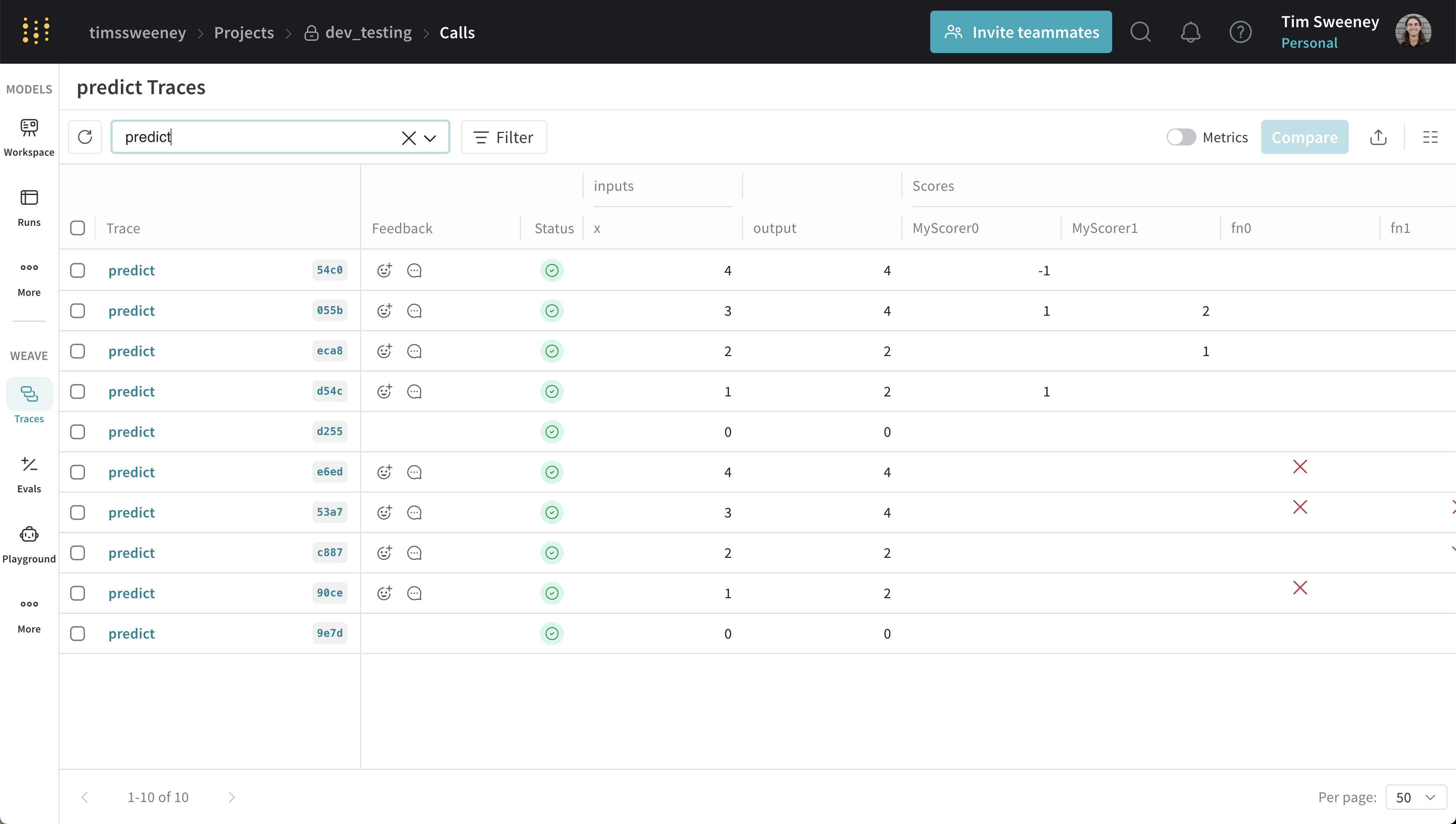
특정 Scorer가 채점한 모든 Call 분석
Scorer별 모든 Call API
get_calls 메서드를 사용하세요.
Scorer별 전체 Call UI
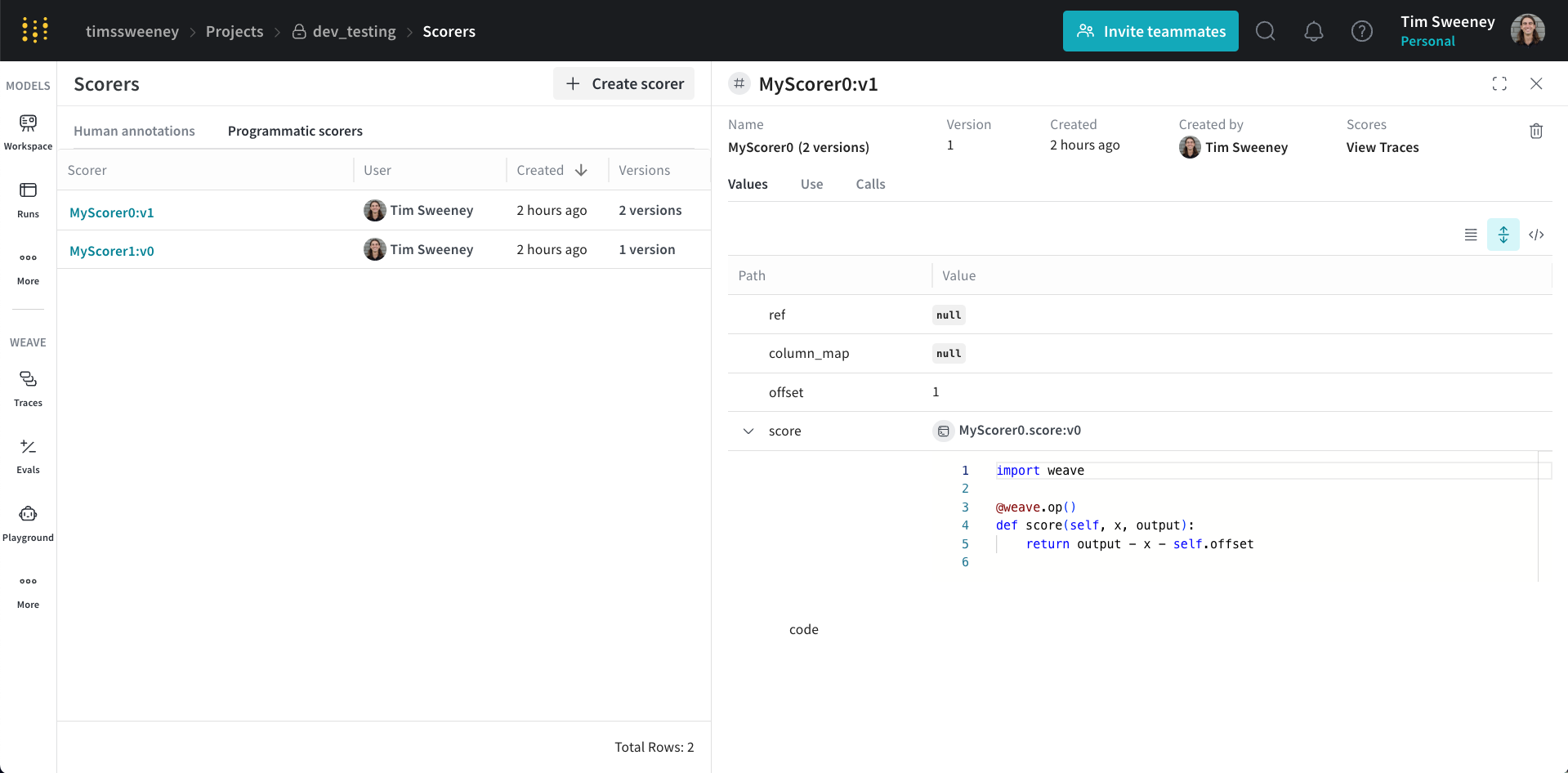
Scores 아래에 있는 View Traces 버튼을 클릭해 Scorer가 채점한 모든 call을 확인합니다.