- 모델 성능 회귀(성능 저하) 추적
- 공유 평가 워크플로우 조율
리더보드 생성은 Weave UI 및 Weave Python SDK에서만 사용할 수 있습니다. TypeScript 사용자는 Weave UI를 사용하여 리더보드를 생성하고 관리할 수 있습니다.
리더보드 생성
UI 사용하기
- Weave UI에서 Leaders 섹션으로 이동합니다. 보이지 않으면 More → Leaders를 클릭합니다.
- + New Leaderboard를 클릭합니다.
- Leaderboard Title 필드에 설명적인 이름을 입력합니다(예:
summarization-benchmark-v1). - 필요하다면, 이 리더보드가 무엇을 비교하는지 설명을 추가합니다.
- 표시할 평가와 메트릭을 정의하기 위해 열을 추가합니다.
- 레이아웃이 마음에 들면 리더보드를 저장하고 게시하여 다른 사람과 공유합니다.
열 추가
- Evaluation: 드롭다운에서 평가 run을 선택합니다(먼저 생성되어 있어야 합니다).
- Scorer: 해당 평가에서 사용된 스코어링 함수(예:
jaccard_similarity,simple_accuracy)를 선택합니다. - Metric: 표시할 요약 메트릭(예:
mean,true_fraction등)을 선택합니다.
⋯)를 클릭합니다. 다음 작업을 수행할 수 있습니다:
- Move before / after – 열 순서 변경
- Duplicate – 열 정의 복사
- Delete – 열 삭제
- Sort ascending – 리더보드의 기본 정렬 순서 설정(다시 클릭하면 내림차순으로 전환됩니다)
Python
-
테스트 데이터셋을 정의합니다. 내장된
Dataset을 사용하거나, 입력과 타깃 목록을 수동으로 정의할 수 있습니다: -
하나 이상의 scorer를 정의합니다:
-
Evaluation을 생성합니다: -
평가할 모델을 정의합니다:
-
평가를 실행합니다:
-
리더보드를 생성합니다:
-
리더보드를 게시합니다.
-
결과를 조회합니다:
End-to-End Python 예제
리더보드 보기 및 해석하기
- Weave UI에서 Leaders 탭으로 이동합니다. 보이지 않으면 More를 클릭한 다음 Leaders를 선택합니다.
- 리더보드 이름(예:
Summarization Model Comparison)을 클릭합니다.
model_humanlike, model_vanilla, model_messy)을 나타냅니다. mean 열에는 해당 모델의 출력과 기준 요약(reference summaries) 간의 평균 Jaccard similarity가 표시됩니다.
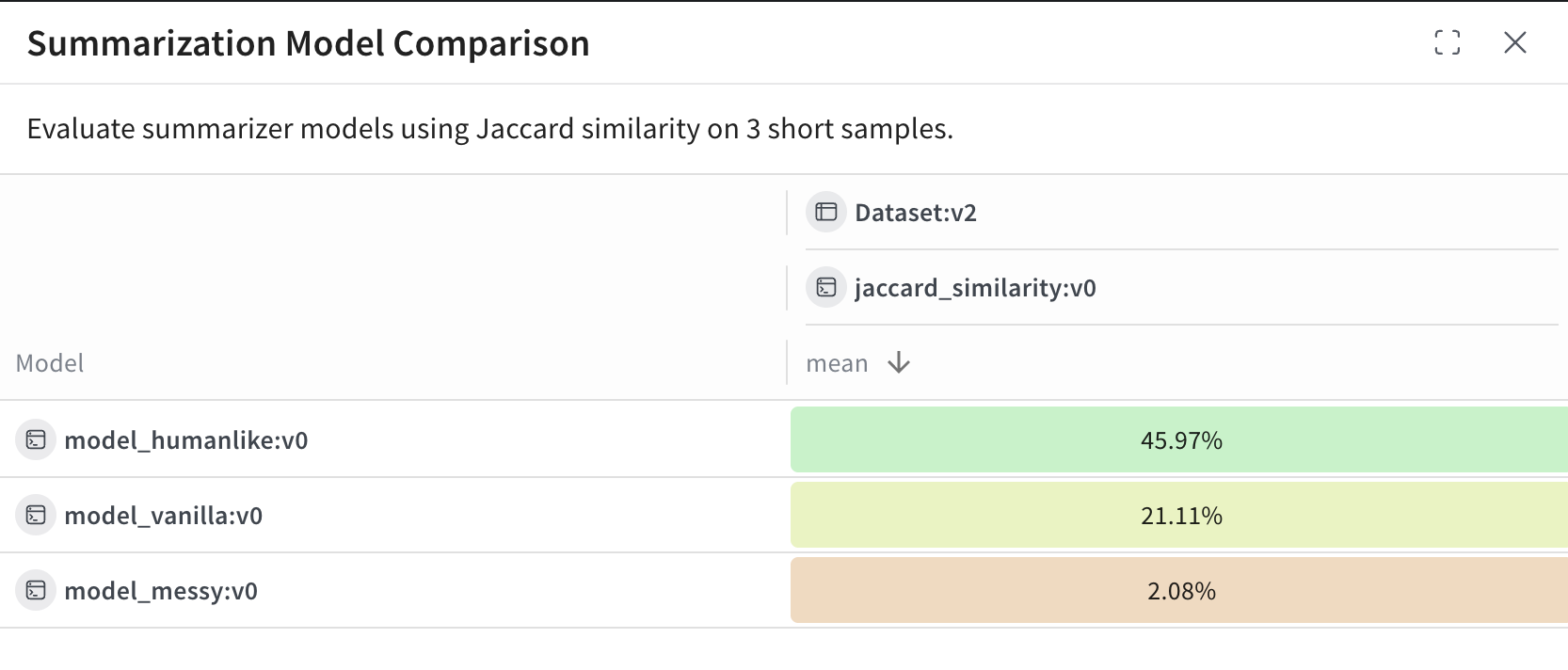
model_humanlike이(가) 약 46%의 겹치는 비율(overlap)로 가장 좋은 성능을 보입니다.model_vanilla(단순 잘라내기 방식, naive truncation)는 약 21%를 기록합니다.model_messy는 의도적으로 성능이 낮게 설계한 모델로, 약 2%에 그칩니다.