Dataset은 프로그래밍 방식과 UI에서 모두 생성하고 사용할 수 있습니다.
이 페이지에서는 다음을 다룹니다:
- Python과 TypeScript에서 기본적인
Dataset작업과 시작하는 방법 - Weave calls 같은 객체로부터 Python과 TypeScript에서
Dataset을 생성하는 방법 - UI에서
Dataset에 대해 사용할 수 있는 작업
Dataset 퀵스타트
Dataset 작업을 수행하는 방법을 보여줍니다. SDK를 사용하면 다음을 수행할 수 있습니다:
Dataset생성Dataset게시Dataset조회Dataset에서 특정 예제에 접근
- Python
- TypeScript
다른 객체에서 Dataset 만들기
- Python
- TypeScript
Python에서는 그런 다음
Dataset을 calls 같은 일반적인 Weave 객체나 pandas.DataFrame과 같은 Python 객체로부터도 생성할 수 있습니다. 이 기능은 특정 예시들로부터 예제 Dataset을 만들고 싶을 때 유용합니다.Weave call
하나 이상의 Weave call로부터Dataset을 생성하려면, call 객체를 가져온 뒤 from_calls 메서드에 리스트로 전달하면 됩니다.Pandas DataFrame
PandasDataFrame 객체로부터 Dataset을 생성하려면 from_pandas 메서드를 사용합니다.Dataset을 다시 변환하려면 to_pandas를 사용합니다.Hugging Face Datasets
Hugging Facedatasets.Dataset 또는 datasets.DatasetDict 객체로부터 Dataset을 생성하려면, 먼저 필요한 의존성이 설치되어 있는지 확인합니다:from_hf 메서드를 사용합니다. 여러 개의 split(예: ‘train’, ‘test’, ‘validation’)을 가진 DatasetDict를 전달하면, Weave는 자동으로 ‘train’ split을 사용하고 경고를 출력합니다. ‘train’ split이 없으면 오류를 발생시킵니다. 특정 split을 직접 제공할 수도 있습니다(예: hf_dataset_dict['test']).weave.Dataset을 Hugging Face Dataset로 다시 변환하려면 to_hf 메서드를 사용합니다.UI에서 Dataset 생성, 편집 및 삭제
Dataset을 생성, 편집, 삭제할 수 있습니다.
새 Dataset 만들기
- 편집하려는 Weave 프로젝트로 이동합니다.
- 사이드바에서 Traces를 선택합니다.
-
새
Dataset을 만들고 싶은 호출을 하나 이상 선택합니다. - 오른쪽 상단 메뉴에서 Add selected rows to a dataset 아이콘(휴지통 아이콘 옆에 있음)을 클릭합니다.
- Choose a dataset 드롭다운에서 Create new를 선택합니다. Dataset name 필드가 표시됩니다.
-
Dataset name 필드에 데이터셋 이름을 입력합니다. 그러면 Configure dataset fields 옵션이 표시됩니다.
데이터셋 이름은 영문자 또는 숫자로 시작해야 하며, 영문자, 숫자, 하이픈, 밑줄만 포함할 수 있습니다.
-
(선택 사항) Configure dataset fields에서 데이터셋에 포함할 호출의 필드를 선택합니다.
- 선택한 각 필드에 대해 열 이름을 사용자 지정할 수 있습니다.
- 새
Dataset에 포함할 필드의 부분 집합을 선택하거나, 모든 필드를 선택 해제할 수 있습니다.
-
데이터셋 필드를 구성했으면 Next를 클릭합니다. 새
Dataset의 미리 보기가 표시됩니다. - (선택 사항) Dataset 내에서 편집 가능한 필드를 클릭하여 항목을 수정합니다.
- Create dataset을 클릭합니다. 새 데이터셋이 생성됩니다.
-
확인 팝업에서 View the dataset을 클릭하여 새
Dataset을 확인합니다. 또는 Datasets 탭으로 이동합니다.
Dataset 편집하기
-
편집하려는
Dataset이 포함된 Weave 프로젝트로 이동합니다. -
사이드바에서 Datasets를 선택합니다. 사용 가능한
Dataset들이 표시됩니다.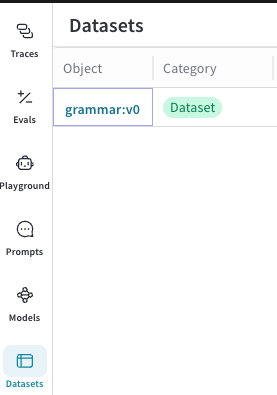
-
Object 열에서 편집하려는
Dataset의 이름과 버전을 클릭합니다. 이름, 버전, 작성자,Dataset행 등Dataset정보를 보여주는 팝업 모달이 표시됩니다.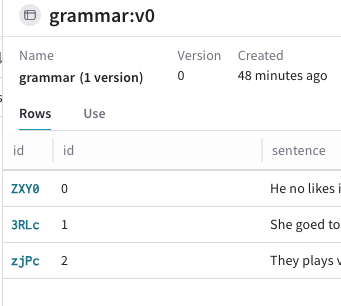
-
모달 오른쪽 상단에서 Edit dataset 버튼(연필 아이콘)을 클릭합니다. 모달 하단에 + Add row 버튼이 표시됩니다.

-
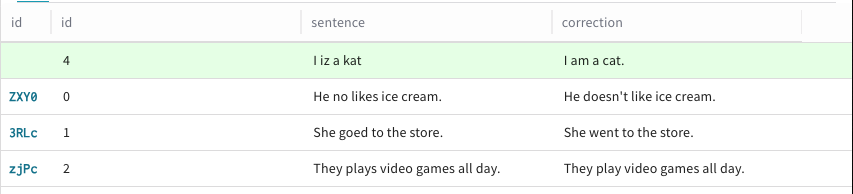
+ Add row를 클릭합니다. 기존
Dataset행의 맨 위에 초록색 행이 표시되며,Dataset에 새 행을 추가할 수 있음을 나타냅니다.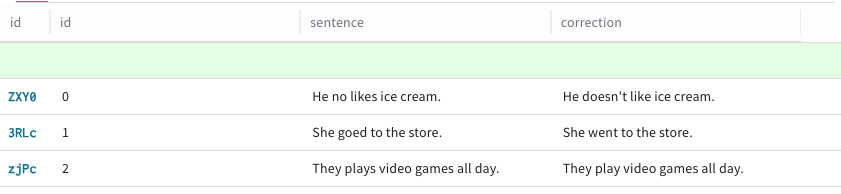
-
새 행에 데이터를 추가하려면 해당 행에서 원하는 열을 클릭합니다.
Dataset행의 기본 id 열은 Weave가 생성 시 자동으로 할당하므로 편집할 수 없습니다. 서식을 지정할 수 있도록 Text, Code, Diff 옵션이 있는 편집 모달이 나타납니다.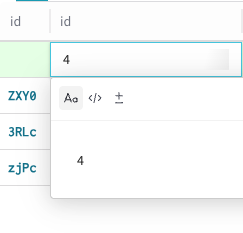
-
새 행에 데이터를 추가하려는 각 열에 대해 6단계를 반복합니다.
-
Dataset에 추가하려는 각 행에 대해 5단계를 반복합니다. -
편집을 마쳤으면 모달 오른쪽 상단의 Publish를 클릭하여
Dataset을 게시합니다. 변경 사항을 게시하지 않으려면 Cancel을 클릭합니다.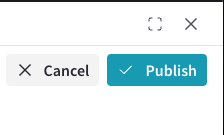
Dataset을 UI에서 확인할 수 있습니다.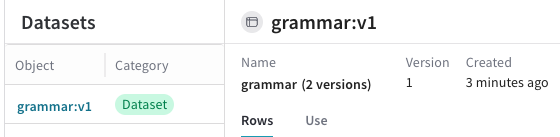

Dataset 삭제하기
-
편집하려는
Dataset이 포함된 Weave 프로젝트로 이동합니다. -
사이드바에서 Datasets를 선택합니다. 사용 가능한
Dataset목록이 표시됩니다. -
Object 열에서 삭제하려는
Dataset의 이름과 버전을 클릭합니다. 이름, 버전, 작성자,Dataset행 등의 정보를 보여주는 모달 창이 오른쪽에 슬라이드되어 나타납니다. -
모달의 오른쪽 상단 모서리에서 휴지통 아이콘을 클릭합니다.
Dataset삭제를 확인하라는 팝업 모달이 표시됩니다.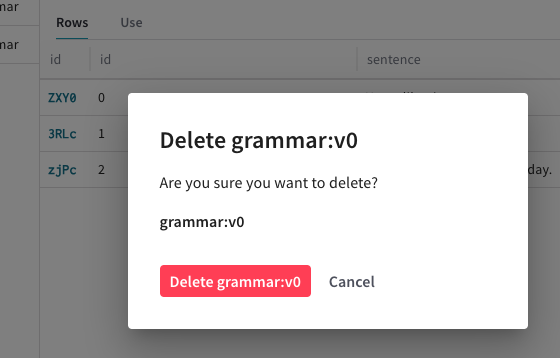
-
팝업 모달에서 빨간색 Delete 버튼을 클릭해
Dataset을 삭제합니다.Dataset을 삭제하지 않으려면 Cancel을 클릭합니다. 이제Dataset이 삭제되며, Weave 대시보드의 Datasets 탭에서 더 이상 보이지 않습니다.
Dataset에 새 예제 추가하기
- 수정하려는 Weave 프로젝트로 이동합니다.
- 사이드바에서 Traces를 선택합니다.
-
새 예제를 만들고 싶은
Datasets가 연결된 호출을 하나 이상 선택합니다. - 오른쪽 상단 메뉴에서 Add selected rows to a dataset 아이콘(휴지통 아이콘 옆에 있음)을 클릭합니다. 필요하면 Show latest versions 토글을 끄고, 사용 가능한 모든 데이터셋의 모든 버전을 표시할 수 있습니다.
-
Choose a dataset 드롭다운에서 예제를 추가하려는
Dataset을 선택합니다. 그러면 Configure field mapping 옵션이 표시됩니다. - (선택 사항) Configure field mapping에서 호출의 필드를 해당 데이터셋 열에 매핑하는 방식을 조정할 수 있습니다.
-
필드 매핑 구성을 마쳤다면 Next를 클릭합니다. 새
Dataset의 미리 보기가 표시됩니다. - 비어 있는 행(초록색)에 새 예제 값을 추가합니다. id 필드는 수정할 수 없으며, Weave에서 자동으로 생성된다는 점에 유의하세요.
- Add to dataset을 클릭합니다. 또는 Configure field mapping 화면으로 돌아가려면 Back을 클릭합니다.
-
확인 팝업에서 View the dataset을 클릭해 변경 내용을 확인합니다. 또는 Datasets 탭으로 이동하여
Dataset에 대한 업데이트를 확인할 수도 있습니다.
기타 데이터셋 작업
- Python
- TypeScript