Weave에서 모니터를 생성하는 방법
- W&B UI를 연 다음, Weave 프로젝트를 엽니다.
- Weave 사이드 내비게이션에서 Monitors를 선택한 다음 + New Monitor 버튼을 클릭합니다. 그러면 Create new monitor 모달 대화 상자가 열립니다.
-
Create new monitor 메뉴에서 다음 필드를 설정합니다:
- Name: 문자 또는 숫자로 시작해야 합니다. 문자, 숫자, 하이픈, 밑줄만 포함할 수 있습니다.
- Description (선택 사항): 모니터가 무엇을 하는지 설명합니다.
- Active monitor 토글: 모니터를 켜거나 끕니다.
- Calls to monitor:
- Operations: 모니터링할 하나 이상의
@weave.op을 선택합니다. 사용 가능한 op 목록에 표시되려면 해당 op를 사용하는 트레이스를 최소 한 번 이상 로깅해야 합니다. - Filter (선택 사항): 예를 들어
max_tokens또는top_p로, 어떤 호출이 모니터링 대상이 될지 범위를 좁힙니다. - Sampling rate: 점수를 매길 호출의 비율입니다(0% ~ 100%).
- Operations: 모니터링할 하나 이상의
- LLM-as-a-judge configuration:
- Scorer name: 문자 또는 숫자로 시작해야 합니다. 문자, 숫자, 하이픈, 밑줄만 포함할 수 있습니다.
- Score Audio: 사용할 수 있는 LLM 모델을 오디오 지원 모델만 표시하도록 필터링하고, Media Scoring JSON Paths 필드를 표시합니다.
- Score Images: 사용할 수 있는 LLM 모델을 이미지 지원 모델만 표시하도록 필터링하고, Media Scoring JSON Paths 필드를 표시합니다.
- Judge model: op에 점수를 매길 모델을 선택합니다. 메뉴에는 W&B 계정에서 설정한 상용 LLM 모델과 W&B Inference models가 포함됩니다. 오디오를 지원하는 모델에는 이름 옆에 Audio Input 레이블이 표시됩니다. 선택한 모델에 대해 다음 설정을 구성합니다:
- Configuration name: 이 모델 설정의 이름입니다.
- System prompt: 예를 들어 “You are an impartial AI judge.”처럼, 평가 모델의 역할과 페르소나를 정의합니다.
- Response format:
json_object또는 일반text와 같이, 평가자가 응답을 출력해야 하는 형식입니다. - Scoring prompt: op에 점수를 매기는 데 사용되는 평가 작업입니다. 스코어링 프롬프트에서 프롬프트 변수를 참조할 수 있습니다. 예: “Evaluate whether
{output}is accurate based on{ground_truth}.”
- Media Scoring JSON Paths: 트레이스 데이터에서 미디어를 추출하기 위한 JSONPath 표현식(RFC 9535)을 지정합니다. 경로를 지정하지 않으면 사용자 메시지에서 평가 가능한 모든 미디어가 포함됩니다. 이 필드는 Score Audio 또는 Score Images를 활성화하면 표시됩니다.
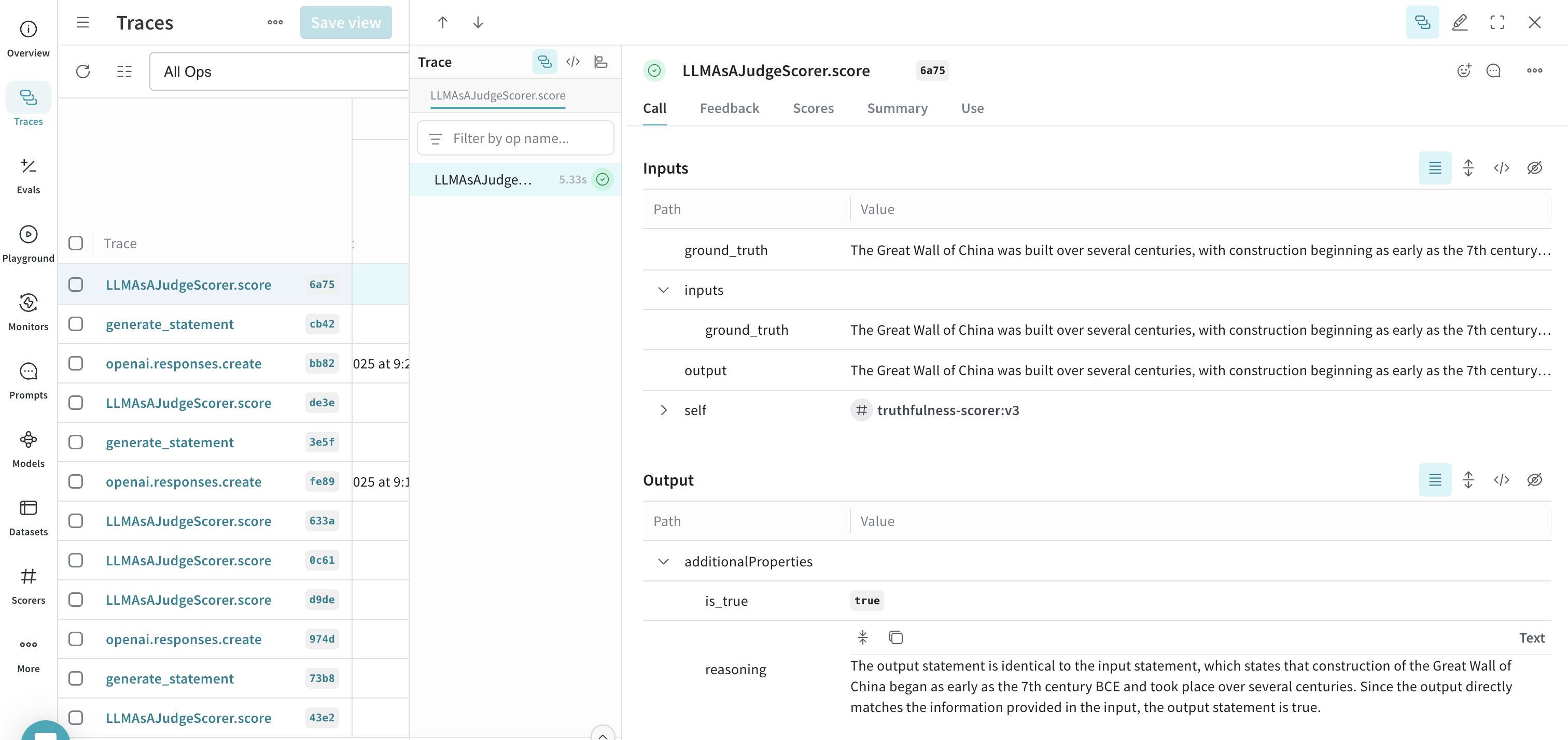
- 모니터의 필드를 모두 설정한 후 Create monitor를 클릭합니다. 그러면 모니터가 Weave 프로젝트에 추가됩니다. 코드에서 트레이스를 생성하기 시작하면, Traces 탭에서 모니터 이름을 선택한 뒤 나타나는 패널의 데이터를 검토하여 점수를 확인할 수 있습니다.
feedback 필드에 자동으로 저장합니다.
예시: 진실성(truthfulness) 모니터 생성하기
- 문장을 생성하는 함수를 정의합니다. 일부 문장은 사실에 기반하고, 일부는 그렇지 않습니다:
- Python
- TypeScript
- 함수를 최소 한 번 이상 실행해 프로젝트에 트레이스를 기록합니다. 이렇게 하면 해당 op를 W&B UI에서 모니터링에 사용할 수 있습니다.
- W&B UI에서 Weave 프로젝트를 열고 사이드 내비게이션에서 Monitors를 선택합니다. 그런 다음 New Monitor를 선택합니다.
-
Create new monitor 메뉴에서 다음 값으로 필드를 구성합니다:
- Name:
truthfulness-monitor - Description:
Evaluates the truthfulness of generated statements. - Active monitor: on으로 토글합니다.
- Operations:
generate_statement를 선택합니다. - Sampling rate: 모든 호출을 스코어링하도록
100%로 설정합니다. - Scorer name:
truthfulness-scorer - Judge model:
o3-mini-2025-01-31 - System prompt:
You are an impartial AI judge. Your task is to evaluate the truthfulness of statements. - Response format:
json_object - Scoring prompt:
- Name:
- Create Monitor를 클릭합니다. 그러면 모니터가 Weave 프로젝트에 추가됩니다.
- 스크립트에서 진실성 수준이 다양한 문장으로 함수를 호출하여 스코어링 함수를 테스트합니다:
- Python
- TypeScript
- 여러 다른 문장으로 스크립트를 실행한 후, W&B UI를 열고 Traces 탭으로 이동합니다. 결과를 확인하려면 임의의 LLMAsAJudgeScorer.score 트레이스를 선택합니다.