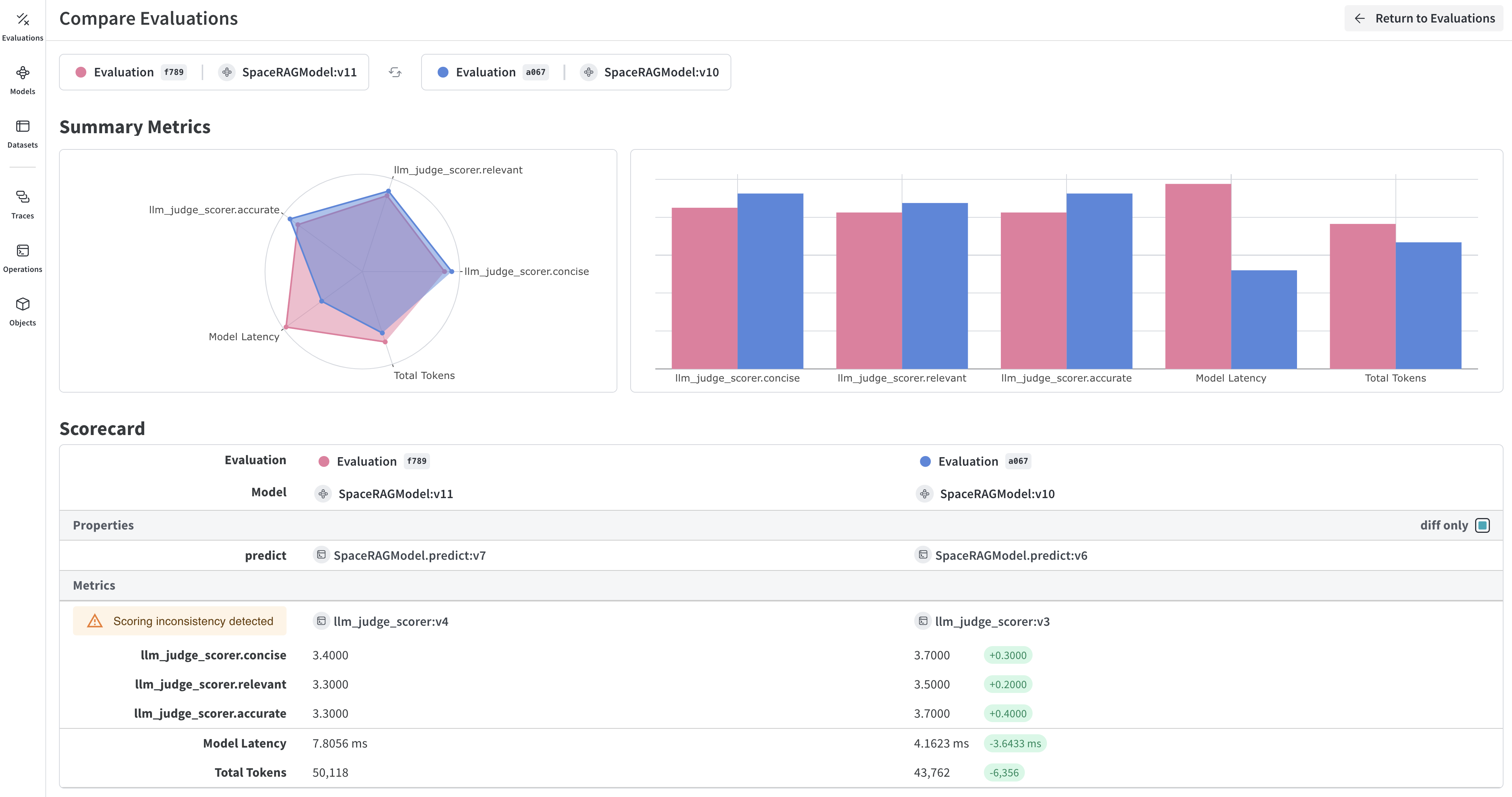
평가는 애플리케이션에 변경을 가한 뒤 일련의 예제를 대상으로 테스트하여 애플리케이션을 반복적으로 개선할 수 있도록 도와줍니다. Weave는 Model 및 Evaluation 클래스를 통해 평가를 추적하기 위한 일급 지원을 제공합니다. 이 API는 전제를 최소화하도록 설계되어, 매우 다양한 사용 사례에 유연하게 대응할 수 있습니다.
Weave에서 Models는 객체로, 모델/에이전트의 동작(로직, 프롬프트, 파라미터)과 버전 관리되는 메타데이터(파라미터, 코드, 마이크로 설정)를 함께 캡처하여, 신뢰성 있게 추적·비교·평가·반복할 수 있도록 해 줍니다.Model을 인스턴스화하면 Weave가 해당 Model의 설정과 동작을 자동으로 캡처하고, 변경 사항이 있을 때마다 버전을 업데이트합니다. 이를 통해 반복적으로 개선해 나가면서 시간에 따른 성능을 추적할 수 있습니다.Model은 Model을 서브클래싱(subclassing)하고, 하나의 예제를 입력으로 받아 응답을 반환하는 predict 함수 정의를 구현하여 선언합니다.다음 예시 모델은 OpenAI를 사용해, 전달된 문장에서 외계 과일의 이름, 색깔, 풍미를 추출합니다.
Python
TypeScript
잘못된 코드 신고
복사
AI에게 묻기
class ExtractFruitsModel(weave.Model): model_name: str prompt_template: str @weave.op() async def predict(self, sentence: str) -> dict: client = openai.AsyncClient() response = await client.chat.completions.create( model=self.model_name, messages=[ {"role": "user", "content": self.prompt_template.format(sentence=sentence)} ], ) result = response.choices[0].message.content if result is None: raise ValueError("No response from model") parsed = json.loads(result) return parsed
잘못된 코드 신고
복사
AI에게 묻기
// 참고: weave.Model은 아직 TypeScript에서 지원되지 않습니다.// 대신, 모델과 유사한 함수를 weave.op으로 래핑하세요.import * as weave from 'weave';import OpenAI from 'openai';const openaiClient = new OpenAI();const model = weave.op(async function myModel({datasetRow}) { const prompt = `Extract fields ("fruit": <str>, "color": <str>, "flavor") from the following text, as json: ${datasetRow.sentence}`; const response = await openaiClient.chat.completions.create({ model: 'gpt-3.5-turbo', messages: [{ role: 'user', content: prompt }], response_format: { type: 'json_object' } }); return JSON.parse(response.choices[0].message.content);});
ExtractFruitsModel 클래스는 Weave가 인스턴스화된 객체를 추적할 수 있도록 weave.Model을 상속(서브클래싱)합니다. @weave.op은 predict 함수를 데코레이터로 감싸 입력과 출력을 추적합니다.Model 객체는 다음과 같이 인스턴스화할 수 있습니다:
Python
TypeScript
잘못된 코드 신고
복사
AI에게 묻기
# 팀과 프로젝트 이름을 설정합니다.weave.init('<team-name>/eval_pipeline_quickstart')model = ExtractFruitsModel( model_name='gpt-3.5-turbo-1106', prompt_template='Extract fields ("fruit": <str>, "color": <str>, "flavor": <str>) from the following text, as json: {sentence}')sentence = "There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy."print(asyncio.run(model.predict(sentence)))# Jupyter Notebook 환경이라면 다음을 실행하세요:# await model.predict(sentence)
잘못된 코드 신고
복사
AI에게 묻기
await weave.init('eval_pipeline_quickstart');const sentence = "There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.";const result = await model({ datasetRow: { sentence } });console.log(result);
다음으로, 모델을 평가할 때 사용할 데이터셋이 필요합니다. Dataset은 Weave 객체로 저장된 예시들의 모음입니다.아래 예시 데이터셋은 세 개의 입력 문장과 그에 해당하는 정답(labels)을 정의한 뒤, 스코어링 함수가 읽을 수 있도록 JSON 테이블 형식으로 포맷합니다.이 예제에서는 코드에서 예시 목록을 만드는 방식이지만, 실행 중인 애플리케이션에서 예시를 하나씩 로그하는 것도 가능합니다.
파이썬
타입스크립트
잘못된 코드 신고
복사
AI에게 묻기
sentences = ["There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.","Pounits are a bright green color and are more savory than sweet.","Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them."]labels = [ {'fruit': 'neoskizzles', 'color': 'purple', 'flavor': 'candy'}, {'fruit': 'pounits', 'color': 'bright green', 'flavor': 'savory'}, {'fruit': 'glowls', 'color': 'pale orange', 'flavor': 'sour and bitter'}]examples = [ {'id': '0', 'sentence': sentences[0], 'target': labels[0]}, {'id': '1', 'sentence': sentences[1], 'target': labels[1]}, {'id': '2', 'sentence': sentences[2], 'target': labels[2]}]
잘못된 코드 신고
복사
AI에게 묻기
const sentences = [ "There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.", "Pounits are a bright green color and are more savory than sweet.", "Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them."];const labels = [ { fruit: 'neoskizzles', color: 'purple', flavor: 'candy' }, { fruit: 'pounits', color: 'bright green', flavor: 'savory' }, { fruit: 'glowls', color: 'pale orange', flavor: 'sour and bitter' }];const examples = sentences.map((sentence, i) => ({ id: i.toString(), sentence, target: labels[i]}));
Weave evaluation을 사용할 때 Weave는 output과 비교할 target이 필요합니다. 아래 스코어링 함수는 두 개의 사전(target과 output)을 받아서, output이 target과 일치하는지를 나타내는 불리언 값의 사전을 반환합니다. @weave.op() 데코레이터는 Weave가 스코어링 함수의 실행을 추적할 수 있도록 해 줍니다.
import * as weave from 'weave';const fruitNameScorer = weave.op( function fruitNameScore({target, output}) { return { correct: target.fruit === output.fruit }; });
직접 스코어링 함수를 작성하려면 Scorers 가이드를 참고하세요.일부 애플리케이션에서는 사용자 정의 Scorer 클래스를 만들고 싶을 수 있습니다. 예를 들어, 특정 파라미터(예: 채팅 모델 또는 프롬프트), 개별 행 스코어링 방식, 그리고 집계 점수 계산을 포함하는 표준화된 LLMJudge 클래스를 만들 수 있습니다. RAG 애플리케이션의 모델 기반 평가에 대한 다음 장의 튜토리얼에서 Scorer 클래스를 정의하는 방법을 확인하세요.
사용자 정의 스코어링 함수와 함께 Weave의 기본 제공 스코어러도 사용할 수 있습니다. 다음 예제에서 weave.Evaluation()은 이전 섹션에서 정의한 fruit_name_score 함수와 F1 점수를 계산하는 기본 제공 스코어러인 MultiTaskBinaryClassificationF1을 함께 사용합니다.다음 예제에서는 fruits 데이터셋에 대해 ExtractFruitsModel을 두 가지 스코어링 함수를 사용해 평가하고, 그 결과를 Weave에 로깅합니다.
import jsonimport asyncioimport openaiimport weavefrom weave.scorers import MultiTaskBinaryClassificationF1# Weave 초기화 (한 번만)weave.init('eval_pipeline_quickstart')# 1. 모델 정의class ExtractFruitsModel(weave.Model): model_name: str prompt_template: str @weave.op() async def predict(self, sentence: str) -> dict: client = openai.AsyncClient() response = await client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": self.prompt_template.format(sentence=sentence)}], ) result = response.choices[0].message.content if result is None: raise ValueError("No response from model") return json.loads(result)# 2. 모델 인스턴스화model = ExtractFruitsModel( model_name='gpt-3.5-turbo-1106', prompt_template='Extract fields ("fruit": <str>, "color": <str>, "flavor": <str>) from the following text, as json: {sentence}')# 3. 데이터셋 생성sentences = ["There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.","Pounits are a bright green color and are more savory than sweet.","Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them."]labels = [ {'fruit': 'neoskizzles', 'color': 'purple', 'flavor': 'candy'}, {'fruit': 'pounits', 'color': 'bright green', 'flavor': 'savory'}, {'fruit': 'glowls', 'color': 'pale orange', 'flavor': 'sour and bitter'}]examples = [ {'id': '0', 'sentence': sentences[0], 'target': labels[0]}, {'id': '1', 'sentence': sentences[1], 'target': labels[1]}, {'id': '2', 'sentence': sentences[2], 'target': labels[2]}]dataset = weave.Dataset(name='fruits', rows=examples)weave.publish(dataset)# 4. 채점 함수 정의@weave.op()def fruit_name_score(target: dict, output: dict) -> dict: return {'correct': target['fruit'] == output['fruit']}# 5. 평가 실행evaluation = weave.Evaluation( name='fruit_eval', dataset=dataset, scorers=[ MultiTaskBinaryClassificationF1(class_names=["fruit", "color", "flavor"]), fruit_name_score ],)print(asyncio.run(evaluation.evaluate(model)))
잘못된 코드 신고
복사
AI에게 묻기
import * as weave from 'weave';import OpenAI from 'openai';// Weave 초기화 (한 번만)await weave.init('eval_pipeline_quickstart');// 1. 모델 정의// 참고: weave.Model은 아직 TypeScript에서 지원되지 않습니다.// 대신, 모델과 유사한 함수를 weave.op으로 래핑하세요.const openaiClient = new OpenAI();const model = weave.op(async function myModel({datasetRow}) { const prompt = `Extract fields ("fruit": <str>, "color": <str>, "flavor": <str>) from the following text, as json: ${datasetRow.sentence}`; const response = await openaiClient.chat.completions.create({ model: 'gpt-3.5-turbo', messages: [{ role: 'user', content: prompt }], response_format: { type: 'json_object' } }); return JSON.parse(response.choices[0].message.content);});// 2. 데이터셋 생성const sentences = [ "There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.", "Pounits are a bright green color and are more savory than sweet.", "Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them."];const labels = [ { fruit: 'neoskizzles', color: 'purple', flavor: 'candy' }, { fruit: 'pounits', color: 'bright green', flavor: 'savory' }, { fruit: 'glowls', color: 'pale orange', flavor: 'sour and bitter' }];const examples = sentences.map((sentence, i) => ({ id: i.toString(), sentence, target: labels[i]}));const dataset = new weave.Dataset({ name: 'fruits', rows: examples});await dataset.save();// 3. 채점 함수 정의const fruitNameScorer = weave.op( function fruitNameScore({target, output}) { return { correct: target.fruit === output.fruit }; });// 4. 평가 실행const evaluation = new weave.Evaluation({ name: 'fruit_eval', dataset: dataset, scorers: [fruitNameScorer],});const results = await evaluation.evaluate(model);console.log(results);