이 노트북은 대화형입니다. 로컬에서 실행하거나 아래 링크를 사용하세요: DSPy와 Weave를 사용한 LLM 워크플로 최적화
- LLM 워크플로를 구축하고 최적화하기 위한 DSPy
- LLM 워크플로를 추적하고 프롬프트 전략을 평가하기 위한 Weave
- Hugging Face Hub에서 Big-Bench Hard 데이터셋에 액세스하기 위한 datasets
!pip install -qU dspy-ai weave datasets
import os
from getpass import getpass
api_key = getpass("OpenAI API 키를 입력하세요: ")
os.environ["OPENAI_API_KEY"] = api_key
weave.init을 추가하면 DSPy 함수가 자동으로 트레이싱되고 Weave UI에서 살펴볼 수 있습니다. 자세한 내용은 DSPy용 Weave 인테그레이션 문서를 참고하세요.
import weave
weave.init(project_name="dspy-bigbench-hard")
weave.Object를 상속한 메타데이터 클래스를 사용합니다.
class Metadata(weave.Object):
dataset_address: str = "maveriq/bigbenchhard"
big_bench_hard_task: str = "causal_judgement"
num_train_examples: int = 50
openai_model: str = "gpt-3.5-turbo"
openai_max_tokens: int = 2048
max_bootstrapped_demos: int = 8
max_labeled_demos: int = 8
metadata = Metadata()
오브젝트 버저닝: Metadata 오브젝트는 이를 사용하는 함수가 트레이싱될 때 자동으로 버전이 관리되고 기록됩니다
weave.Evaluation을 사용해 프롬프트 전략을 평가할 수 있습니다.
import dspy
from datasets import load_dataset
@weave.op()
def get_dataset(metadata: Metadata):
# Huggingface Hub에서 태스크에 해당하는 BIG-Bench Hard 데이터셋 로드
dataset = load_dataset(metadata.dataset_address, metadata.big_bench_hard_task)[
"train"
]
# 트레이닝 및 검증 데이터셋 생성
rows = [{"question": data["input"], "answer": data["target"]} for data in dataset]
train_rows = rows[0 : metadata.num_train_examples]
val_rows = rows[metadata.num_train_examples :]
# `dspy.Example` 객체로 구성된 트레이닝 및 검증 예제 생성
dspy_train_examples = [
dspy.Example(row).with_inputs("question") for row in train_rows
]
dspy_val_examples = [dspy.Example(row).with_inputs("question") for row in val_rows]
# Weave에 데이터셋 게시 - 데이터 버전 관리 및 평가에 활용 가능
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_train", rows=train_rows
)
)
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_val", rows=val_rows
)
)
return dspy_train_examples, dspy_val_examples
dspy_train_examples, dspy_val_examples = get_dataset(metadata)
dspy.OpenAI 추상화를 사용하여 GPT-3.5 Turbo를 호출하는 LLM 호출을 수행합니다.
system_prompt = """
You are an expert in the field of causal reasoning. You are to analyze the a given question carefully and answer in `Yes` or `No`.
You should also provide a detailed explanation justifying your answer.
"""
llm = dspy.OpenAI(model="gpt-3.5-turbo", system_prompt=system_prompt)
dspy.settings.configure(lm=llm)
from pydantic import BaseModel, Field
class Input(BaseModel):
query: str = Field(description="답변할 질문")
class Output(BaseModel):
answer: str = Field(description="질문에 대한 답변")
confidence: float = Field(
ge=0, le=1, description="답변에 대한 신뢰도 점수"
)
explanation: str = Field(description="답변에 대한 설명")
class QuestionAnswerSignature(dspy.Signature):
input: Input = dspy.InputField()
output: Output = dspy.OutputField()
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.TypedPredictor(QuestionAnswerSignature)
@weave.op()
def forward(self, question) -> dict:
return self.prog(input=Input(query=question)).output.dict()
CausalReasoningModule을 테스트해 보자.
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
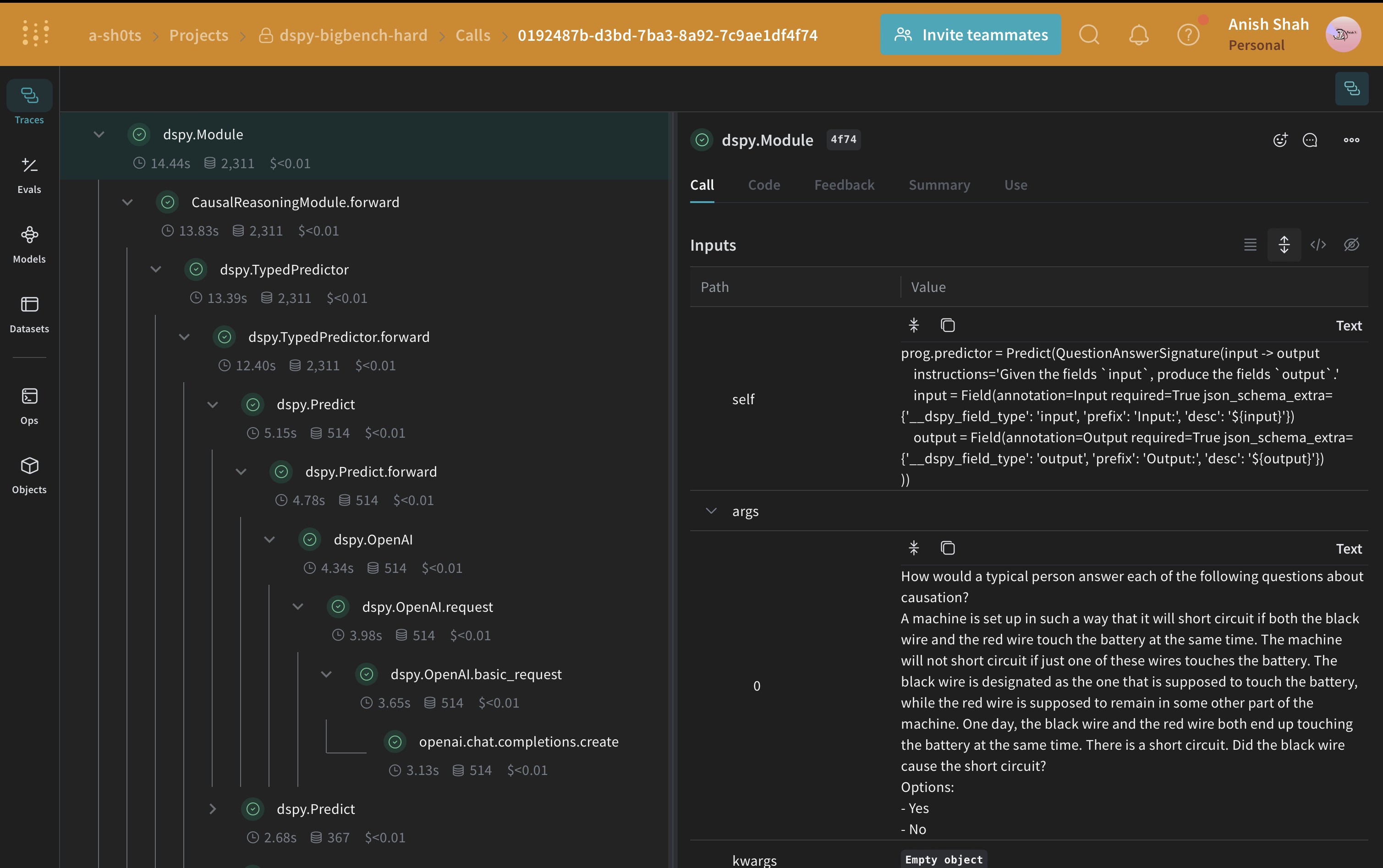
우리 DSPy 프로그램 평가하기
weave.Evaluation으로 이를 평가해 보겠습니다. Weave는 각 예제를 가져와 애플리케이션을 통해 실행한 다음, 여러 개의 사용자 정의 스코어링 함수로 출력 결과에 점수를 매깁니다. 이렇게 하면 애플리케이션의 성능을 한눈에 파악할 수 있고, 각 개별 출력과 점수를 깊이 있게 탐색할 수 있는 풍부한 UI도 제공됩니다.
먼저, 베이스라인 모듈의 출력에서 나온 답이 정답과 같은지 여부를 알려주는 간단한 weave 평가용 스코어링 함수를 만들어야 합니다. 스코어링 함수에는 model_output 키워드 인자가 반드시 필요하지만, 그 외 인자들은 사용자 정의이며 데이터셋 예제에서 가져옵니다. 이 함수는 인자 이름을 키로 사용하는 사전에서 필요한 키만 가져옵니다.
@weave.op()
def weave_evaluation_scorer(answer: str, output: Output) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(baseline_module.forward)
Python 스크립트에서 실행하는 경우 다음 코드를 사용해 평가를 실행할 수 있습니다:import asyncio
asyncio.run(evaluation.evaluate(baseline_module.forward))
causal reasoning 데이터셋에 대한 평가를 실행하면 약 $0.24 상당의 OpenAI 크레딧 비용이 발생합니다.
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
평가용 인과 추론 데이터셋을 실행하면 OpenAI 크레딧으로 약 $0.04의 비용이 발생합니다.
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(optimized_module.forward)



