WandbLogger를 통해 PyTorch Lightning 라이브러리에 이미 통합되어 있습니다.
Lightning과 연동하기
- PyTorch Logger
- Fabric Logger
wandb.log() 사용 시: WandbLogger는 Trainer의 global_step을 사용해 W&B에 로그를 기록합니다. 코드에서 wandb.log를 직접 추가로 호출하는 경우, wandb.log()에서 step 인자를 사용하지 마세요.대신, 다른 메트릭과 마찬가지로 Trainer의 global_step 값을 로그로 기록하세요: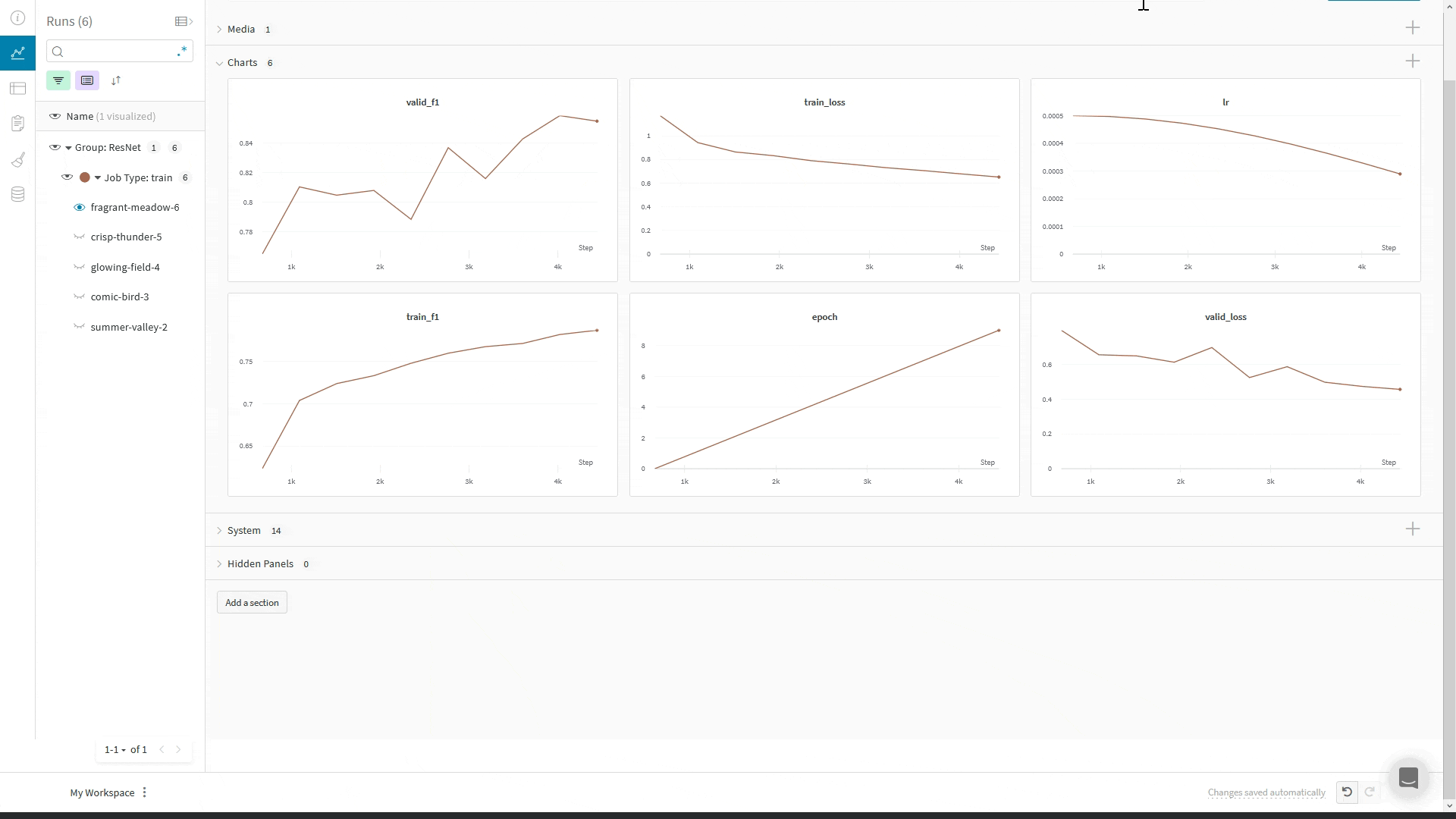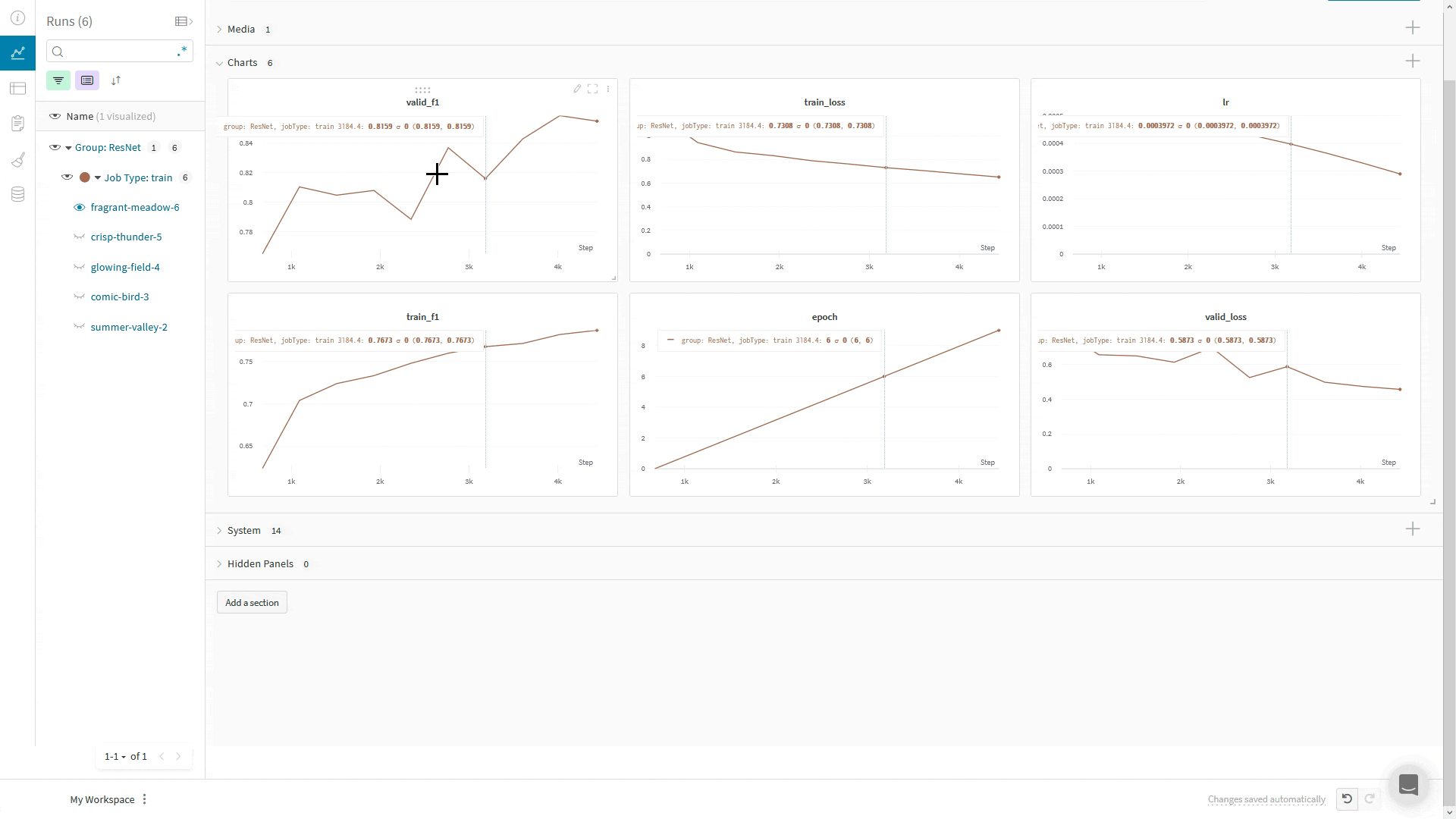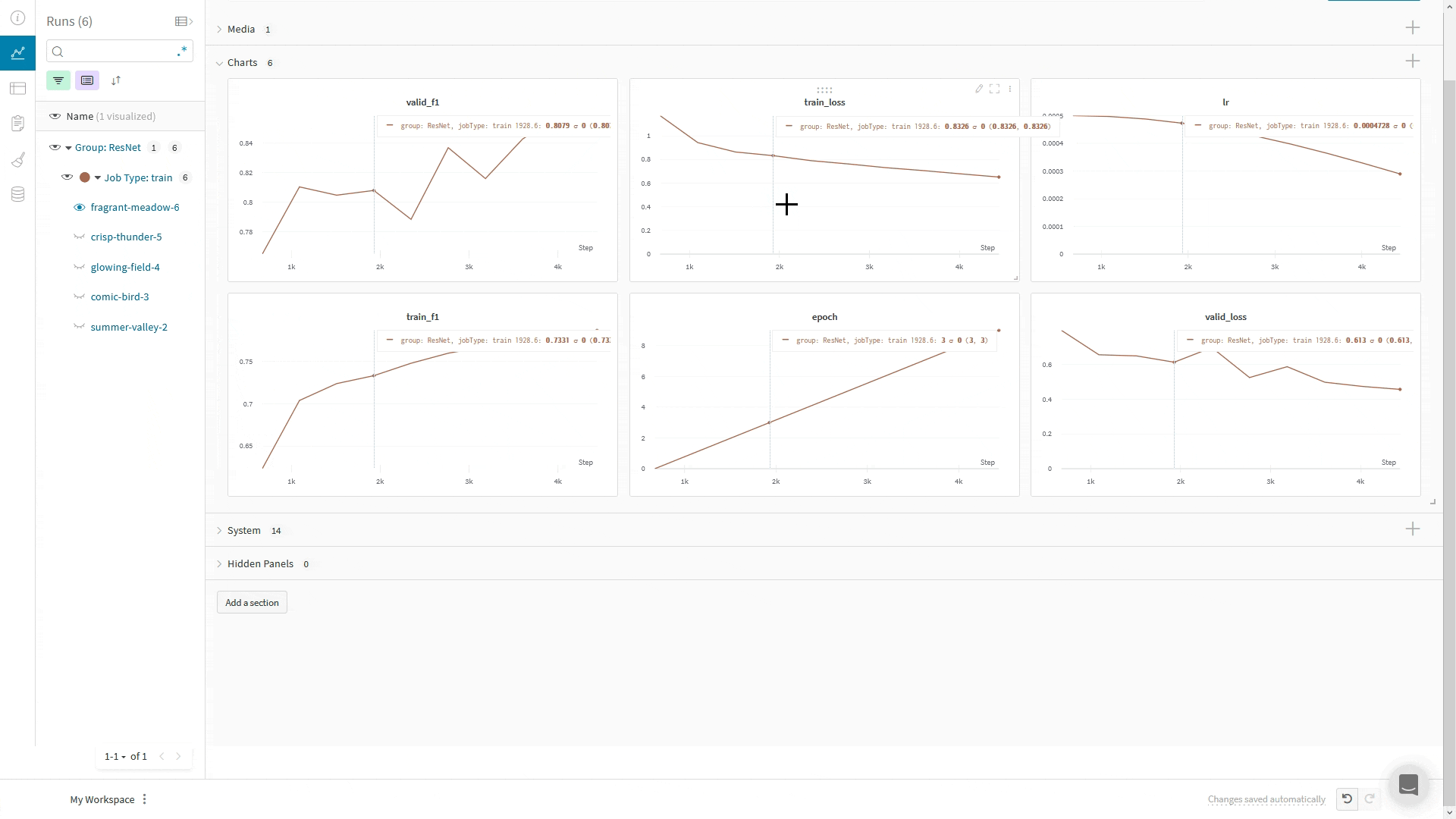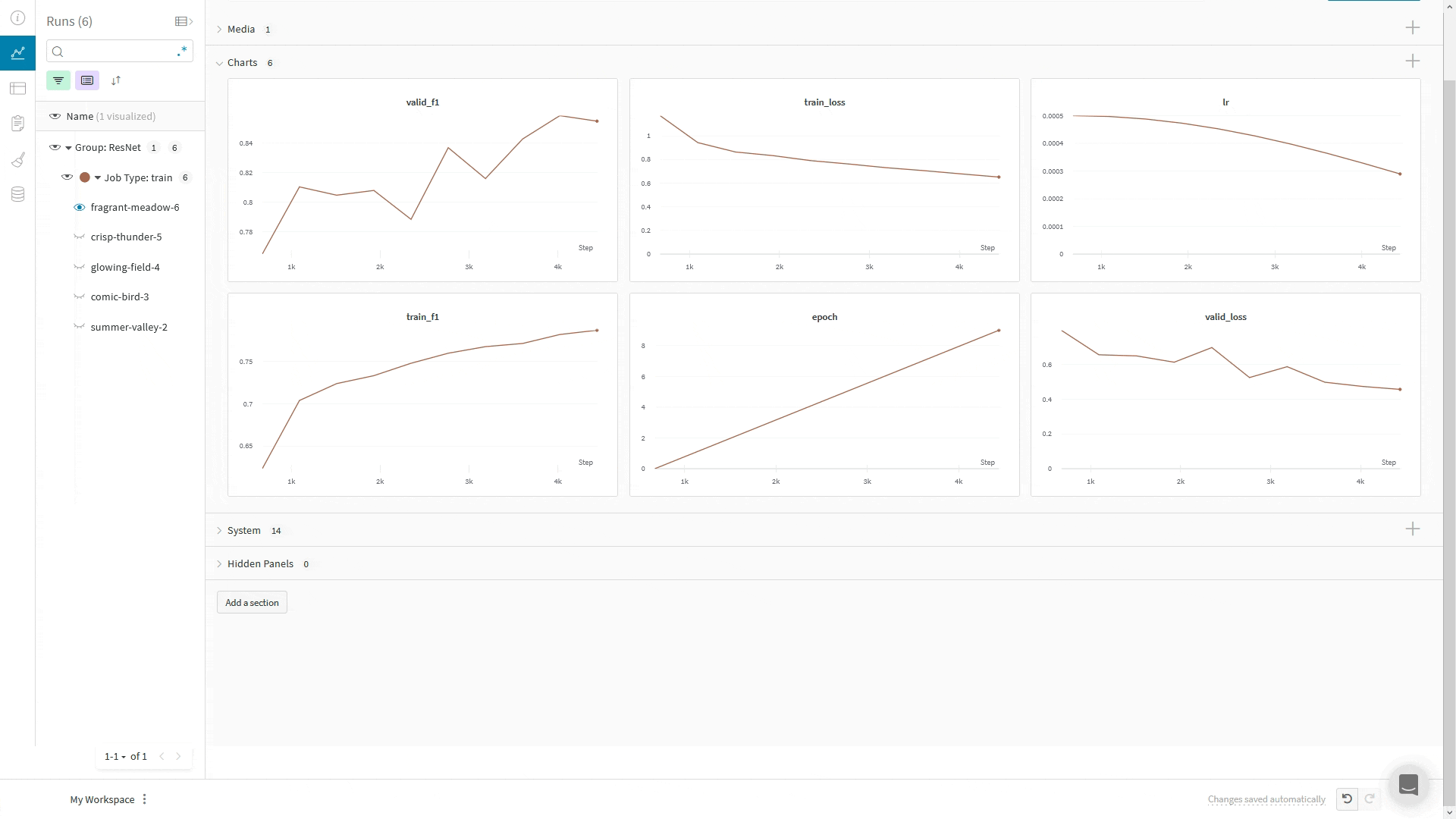
가입 및 API 키 생성하기
더 간편한 방법을 원한다면 User Settings에서 직접 API 키를 생성하세요. 새로 생성된 API 키를 즉시 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
- 오른쪽 상단에서 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션까지 스크롤합니다.
wandb 라이브러리 설치 및 로그인
wandb 라이브러리를 설치하고 로그인하려면 다음을 수행하세요.
- 명령줄
- Python
- Python 노트북
-
WANDB_API_KEY환경 변수를 API 키 값으로 설정합니다. -
wandb라이브러리를 설치하고 로그인합니다.
PyTorch Lightning의 WandbLogger 사용
WandbLogger 클래스를 제공합니다.
Lightning과 통합하려면 WandbLogger를 인스턴스화하고 이를 Lightning의 Trainer 또는 Fabric에 전달하세요.
- PyTorch Logger
- Fabric Logger
공통 로거 인자
WandbLogger에서 가장 많이 사용되는 파라미터입니다. 모든 로거 인자에 대한 자세한 내용은 PyTorch Lightning 문서를 참고하세요.
| Parameter | Description |
|---|---|
project | 로그를 남길 wandb Project를 정의합니다 |
name | wandb run에 사용할 이름을 지정합니다 |
log_model | log_model="all"이면 모든 모델을 로그하고, log_model=True이면 트레이닝 종료 시 모델을 로그합니다 |
save_dir | 데이터가 저장될 경로를 지정합니다 |
하이퍼파라미터 로깅
- PyTorch 로거
- Fabric 로거
추가 설정 파라미터 기록
그래디언트, 파라미터 히스토그램 및 모델 토폴로지 로깅
wandblogger.watch()에 모델 객체를 전달하세요. 자세한 내용은 PyTorch Lightning WandbLogger 문서를 참조하세요.
메트릭 로깅
- PyTorch 로거
- Fabric 로거
WandbLogger를 사용할 때는 LightningModule의 training_step이나 validation_step 메서드 안에서 self.log('my_metric_name', metric_vale)를 호출하여 메트릭을 W&B에 로깅할 수 있습니다.아래 코드 스니펫은 메트릭과 LightningModule 하이퍼파라미터를 로깅하도록 LightningModule을 정의하는 방법을 보여줍니다. 이 예제는 메트릭을 계산하기 위해 torchmetrics 라이브러리를 사용합니다.메트릭의 최소/최대값 로그하기
define_metric 함수를 사용하면 W&B summary 메트릭에 대해 해당 메트릭의 최소값, 최대값, 평균값 또는 베스트값 중 무엇을 표시할지 정의할 수 있습니다. define_metric _ 를 사용하지 않으면 마지막으로 로깅된 값이 summary 메트릭에 표시됩니다. 자세한 내용은 define_metric 레퍼런스 문서와 가이드를 참고하세요.
W&B summary 메트릭에서 최대 검증 정확도를 추적하려면, 트레이닝 시작 시 한 번만 wandb.define_metric 을 호출하세요:
- PyTorch Logger
- Fabric Logger
모델 체크포인트 저장하기
ModelCheckpoint 콜백을 사용하고, WandbLogger의 log_model 매개변수를 설정하세요.
- PyTorch Logger
- Fabric Logger
- Logger 사용
- wandb 사용
- PyTorch Logger
- Fabric Logger
이미지, 텍스트 등 다양한 미디어 로깅하기
WandbLogger에는 미디어를 로깅하기 위한 log_image, log_text, log_table 메서드가 있습니다.
또한 wandb.log 또는 trainer.logger.experiment.log를 직접 호출해 오디오, 분자(Molecules), 포인트 클라우드(Point Clouds), 3D 오브젝트(3D Objects) 등의 다른 미디어 타입도 로깅할 수 있습니다.
- 이미지 로깅
- 텍스트 로깅
- 테이블 로깅
WandbLogger를 통해 W&B에 언제 로깅할지 제어할 수 있으며, 이 예시에서는 검증 이미지와 예측 결과 샘플을 로깅합니다:
Lightning과 W&B로 여러 개의 GPU 사용하기
wandb.run 객체에 접근할 수 있고, 0이 아닌 rank 프로세스에서는 wandb.run = None입니다. 이로 인해 0이 아닌 rank 프로세스가 실패할 수 있습니다. 이런 상황에서는 rank 0 프로세스가 이미 크래시된 0이 아닌 rank 프로세스가 조인하기를 기다리게 되므로, **교착 상태(데드락)**에 빠질 수 있습니다.
이러한 이유로 트레이닝 코드를 구성하는 방식에 주의해야 합니다. 권장되는 방식은 코드가 wandb.run 객체에 의존하지 않도록 작성하는 것입니다.
예시
자주 묻는 질문
W&B는 Lightning과 어떻게 인테그레이션되나요?
loggers API를 기반으로 하며, 이를 통해 로그를 남기는 코드를 특정 프레임워크에 의존하지 않는 방식으로 대부분 작성할 수 있습니다. Logger는 Lightning Trainer에 전달되며, 해당 API의 풍부한 hook-and-callback 시스템에 따라 호출됩니다. 이를 통해 연구 코드를 엔지니어링 및 로깅 코드와 깔끔하게 분리할 수 있습니다.
추가 코드를 작성하지 않아도 이 인테그레이션은 무엇을 기록하나요?
트레이닝 설정에서 wandb.run을 사용해야 하면 어떻게 하나요?
os.environ["WANDB_DIR"]를 사용해 모델 체크포인트 디렉터리를 설정할 수 있습니다. 이렇게 하면 rank가 0이 아닌 프로세스도 wandb.run.dir에 접근할 수 있습니다.