- Accédez à wandb.ai et sélectionnez votre projet.
- Dans la barre latérale du projet Weave, cliquez sur Traces.
- Sélectionnez plusieurs appels à exporter en cochant les lignes correspondantes.
- Dans la barre d’outils du tableau Traces, cliquez sur le bouton d’export/téléchargement.
- Dans la fenêtre modale Export, choisissez Selected rows ou All rows, puis cliquez sur Export.
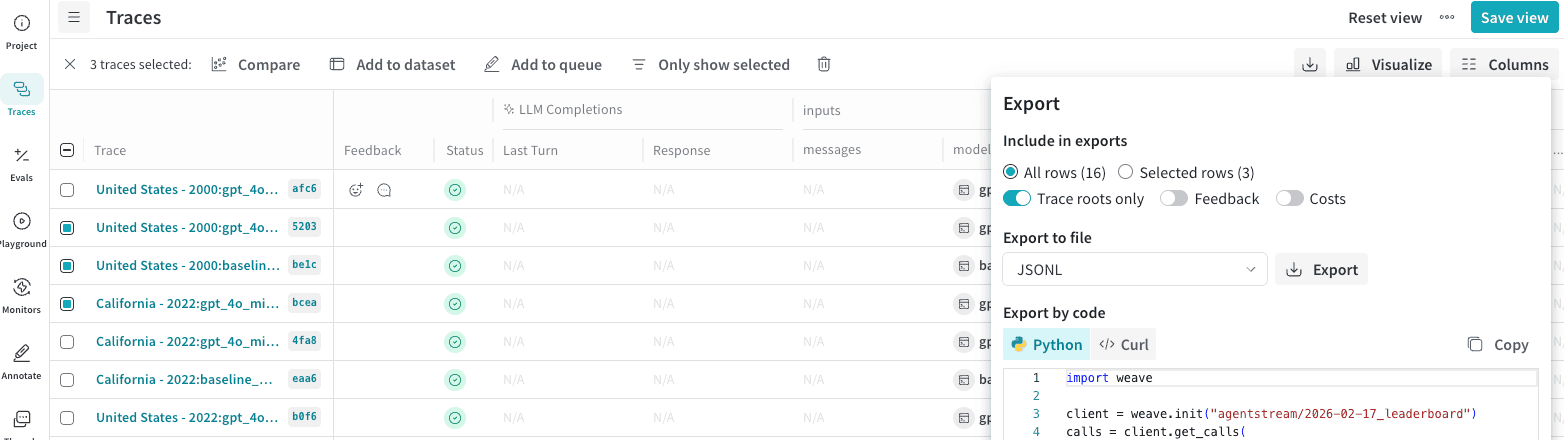
Récupérer les appels par programmation
- Python
- TypeScript
- HTTP API
Pour récupérer des appels avec l’API Python, vous pouvez utiliser la méthode
client.get_calls :Exporter les métriques d’appel
POST /calls/stats de la Service API de Weave pour récupérer des métriques sur vos Appels sans récupérer les données d’Appel elles-mêmes. Cela vous permet de récupérer rapidement et efficacement des informations sur vos Appels, comme la latence et le coût, et de les agréger par somme, moyenne, minimum, maximum et nombre. Par exemple, vous pouvez récupérer :
- L’utilisation totale des tokens
- La latence moyenne
- Le maximum de tokens utilisés
- Le coût total
- Le minimum de tokens d’entrée
- Nom de l’op
- ID de trace
- ID de thread
- ID utilisateur
web_app sur une période de deux jours :
sum, count, avg, min, max et count.
L’endpoint renvoie un objet JSON. L’exemple de réponse suivant montre deux jours de métriques. Chaque jour (bucket) correspond à un objet distinct dans les tableaux usage_buckets et call_buckets. Chaque tableau ventile les métriques différemment :
usage_buckets: regroupe les métriques d’Appel de chaque jour par modèle utilisé.call_buckets: regroupe les métriques d’Appel de chaque jour, quel que soit le modèle utilisé.
granularity (en secondes) dans la requête pour modifier la taille des buckets.