weave.op pour créer des opérations réutilisables afin de suivre tous les appels à un modèle Bedrock. Si vous utilisez des modèles Anthropic, vous pouvez également utiliser l’intégration native de Weave avec Anthropic.
Traces
converse :
Créer vos propres ops
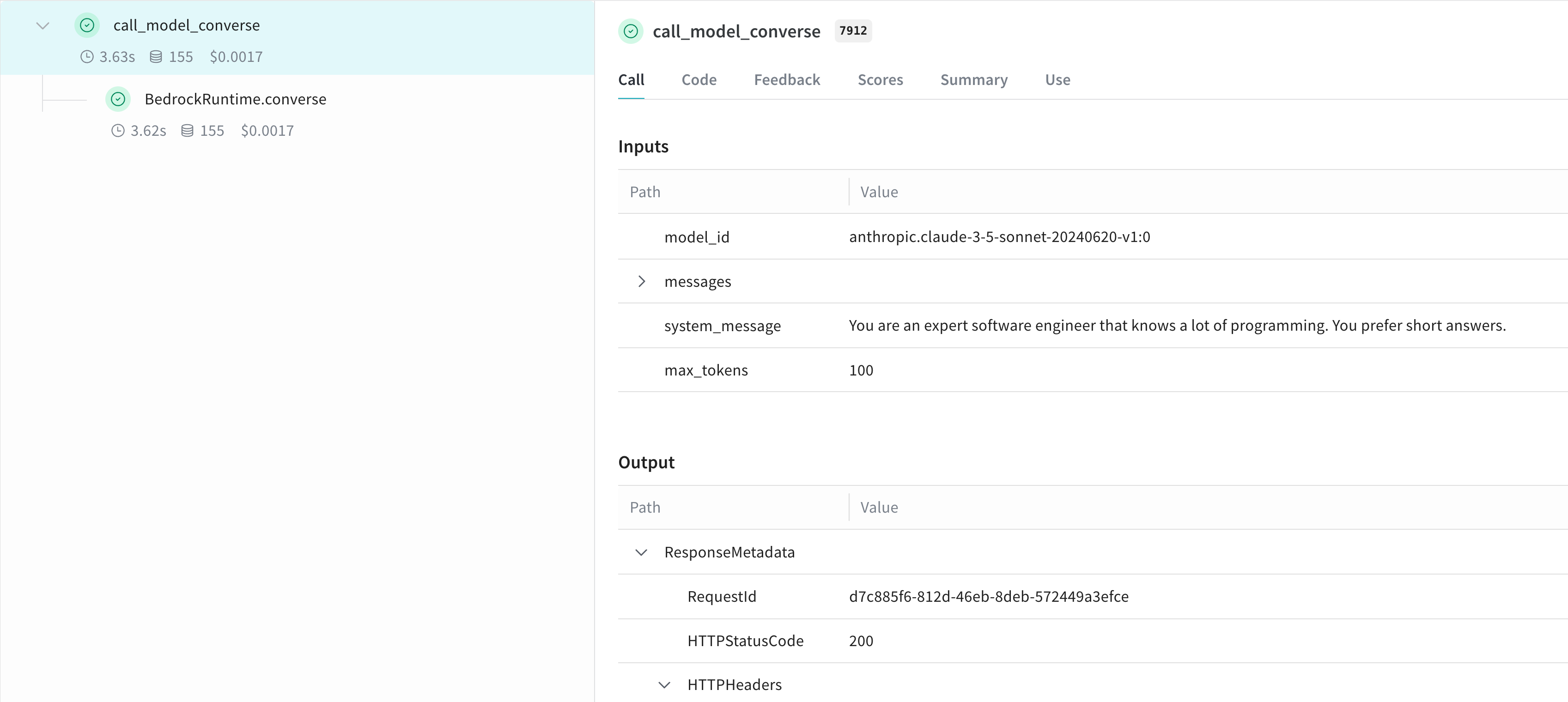
@weave.op(). Voici un exemple qui montre les API invoke_model et converse :
Créer un Model pour simplifier l’expérimentation
converse :