- Python
- TypeScript
Les évaluateurs sont transmis à un objet
weave.Evaluation pendant l’évaluation. Il existe deux types d’évaluateurs dans Weave :- évaluateurs basés sur des fonctions : fonctions Python simples décorées avec
@weave.op. - évaluateurs basés sur des classes : classes Python qui héritent de
weave.Scorerpour des évaluations plus complexes.
Créez vos propres évaluateurs
évaluateurs basés sur des fonctions
- Python
- TypeScript
Il s’agit de fonctions décorées avec Lors de l’exécution de l’évaluation,
@weave.op qui renvoient un dictionnaire. Elles conviennent parfaitement à des évaluations simples comme :evaluate_uppercase vérifie si le texte est entièrement en majuscules.Scorers basés sur des classes
- Python
- TypeScript
Pour des évaluations plus avancées, en particulier lorsque vous devez suivre des métadonnées supplémentaires associées au scorer, essayer différents prompts pour vos évaluateurs LLM ou effectuer plusieurs appels de fonction, vous pouvez utiliser la classe Cette classe évalue la qualité d’un résumé en le comparant au texte original.
Scorer.Exigences :- Héritez de
weave.Scorer. - Définissez une méthode
scoredécorée avec@weave.op. - La méthode
scoredoit renvoyer un dictionnaire.
Fonctionnement des évaluateurs
Arguments par mot-clé du scorer
- Python
- TypeScript
Les évaluateurs peuvent accéder à la fois à la sortie de votre système d’IA et aux données d’entrée de la ligne du jeu de données.Lorsqu’une Mapper les noms de colonnes avec
Il arrive que les noms d’arguments des méthodes Désormais, l’argument
- Entrée : Si vous voulez que votre scorer utilise des données de la ligne de votre jeu de données, comme une colonne “label” ou “target”, vous pouvez facilement les mettre à sa disposition en ajoutant un argument par mot-clé
labeloutargetà la définition de votre scorer.
score) aurait une liste de paramètres comme celle-ci :Evaluation Weave est exécutée, la sortie du système d’IA est transmise au paramètre output. L’Evaluation essaie aussi automatiquement de faire correspondre les noms des arguments supplémentaires du scorer avec les colonnes de votre jeu de données. Si vous ne pouvez pas personnaliser les arguments de votre scorer ou les colonnes du jeu de données, vous pouvez utiliser un mapping de colonnes — voir ci-dessous pour en savoir plus.- Sortie : Incluez un paramètre
outputdans la signature de la fonction de votre scorer pour accéder à la sortie du système d’IA.
Mapper les noms de colonnes avec column_map
Il arrive que les noms d’arguments des méthodes score ne correspondent pas aux noms de colonnes de votre jeu de données. Vous pouvez résoudre ce problème avec column_map.Si vous utilisez un scorer basé sur une classe, transmettez un dictionnaire à l’attribut column_map de Scorer lorsque vous initialisez votre classe de scorer. Ce dictionnaire fait correspondre les noms d’arguments de votre méthode score aux noms de colonnes du jeu de données, selon le format suivant : {scorer_keyword_argument: dataset_column_name}.Exemple :text de la méthode score recevra les données de la colonne news_article du jeu de données.Notes :- Une autre option équivalente pour mapper vos colonnes consiste à sous-classer
Scoreret à surcharger la méthodescoreen faisant explicitement correspondre les colonnes.
Accéder aux variables de vos ops dans les prompts de scoring
| Variable | Description |
|---|---|
{article} | La valeur de l’argument d’entrée article |
{max_length} | La valeur de l’argument d’entrée max_length |
{inputs} | Un dictionnaire JSON de tous les arguments d’entrée |
{output} | Le résultat renvoyé par votre op |
Résumé final du scorer
- Python
- TypeScript
Pendant l’évaluation, le scorer est calculé pour chaque ligne de votre jeu de données. Pour produire un score final pour l’évaluation, nous utilisons
auto_summarize, qui dépend du type de retour de la sortie.- Les moyennes sont calculées pour les colonnes numériques
- Le nombre et la proportion pour les colonnes booléennes
- Les autres types de colonnes sont ignorés
summarize de la classe Scorer et fournir votre propre manière de calculer les scores finaux. La fonction summarize attend :- Un seul paramètre,
score_rows: il s’agit d’une liste de dictionnaires, où chaque dictionnaire contient les scores renvoyés par la méthodescorepour une ligne de votre jeu de données. - Elle doit renvoyer un dictionnaire contenant les scores récapitulatifs.
Dans cet exemple, auto_summarize aurait renvoyé par défaut le nombre et la proportion de valeurs True.
Si vous voulez en savoir plus, consultez l’implémentation de CorrectnessLLMJudge.Appliquer des évaluateurs à un appel
.call(), qui vous donne accès à la fois au résultat de l’opération et à ses informations de suivi. Cela vous permet d’associer les résultats des évaluateurs à des appels spécifiques dans la base de données de Weave.
Pour plus d’informations sur l’utilisation de la méthode .call(), consultez le guide Calling Ops.
- Python
- TypeScript
Voici un exemple simple :Vous pouvez également appliquer plusieurs évaluateurs au même appel :Notes :
- Les résultats des évaluateurs sont automatiquement stockés dans la base de données de Weave
- Les évaluateurs s’exécutent de manière asynchrone une fois l’opération principale terminée
- Vous pouvez consulter les résultats des évaluateurs dans l’UI ou les interroger via l’API
Utiliser preprocess_model_input
preprocess_model_input pour modifier les exemples du jeu de données avant qu’ils n’atteignent votre modèle pendant l’évaluation.
Pour plus d’informations sur l’utilisation et pour un exemple, voir Utiliser preprocess_model_input pour mettre en forme les lignes du jeu de dataset avant l’évaluation.
Analyse des scores
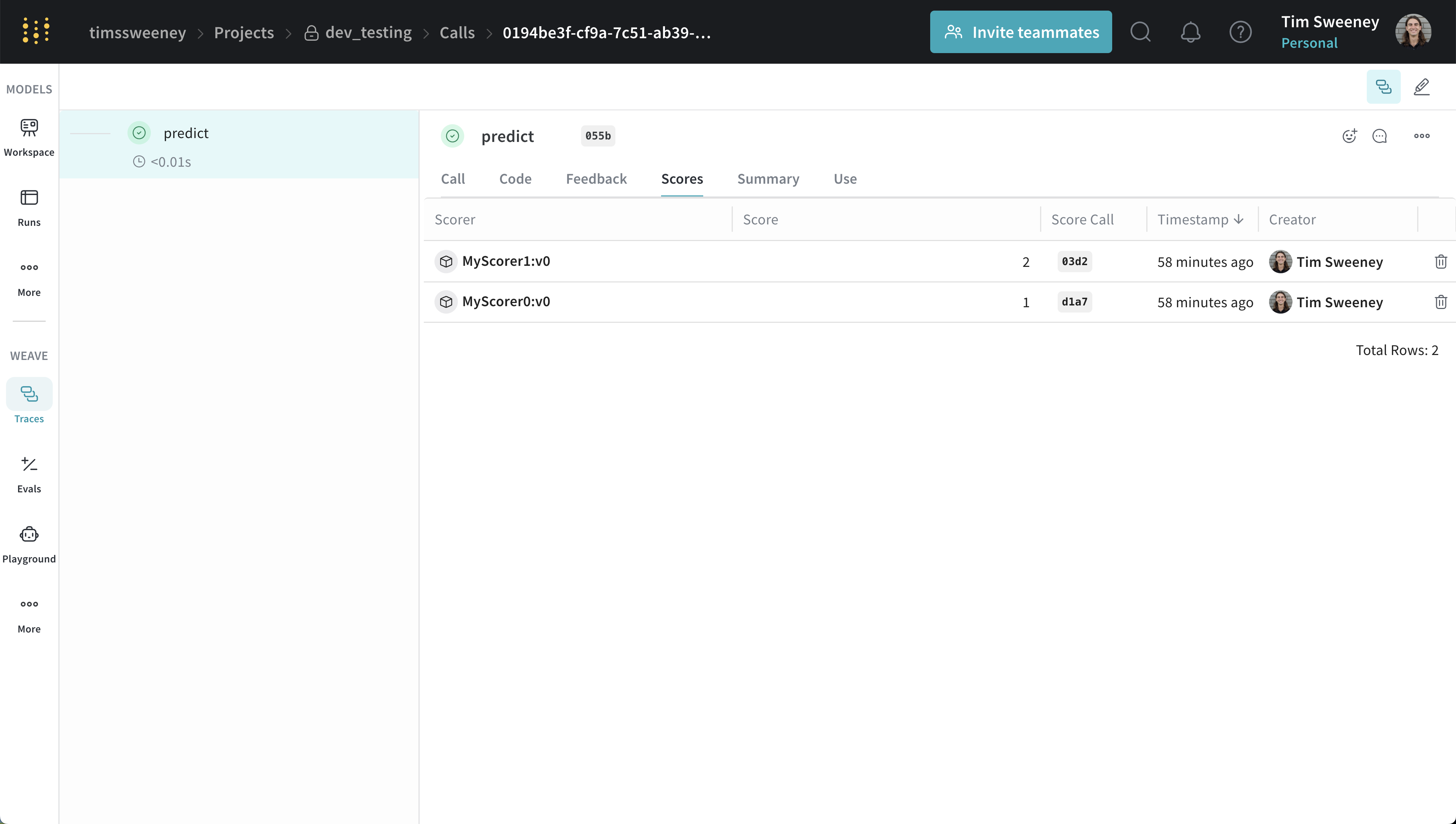
Analyser les scores d’un Appel unique
API pour un appel unique
get_call.
UI d’un appel individuel
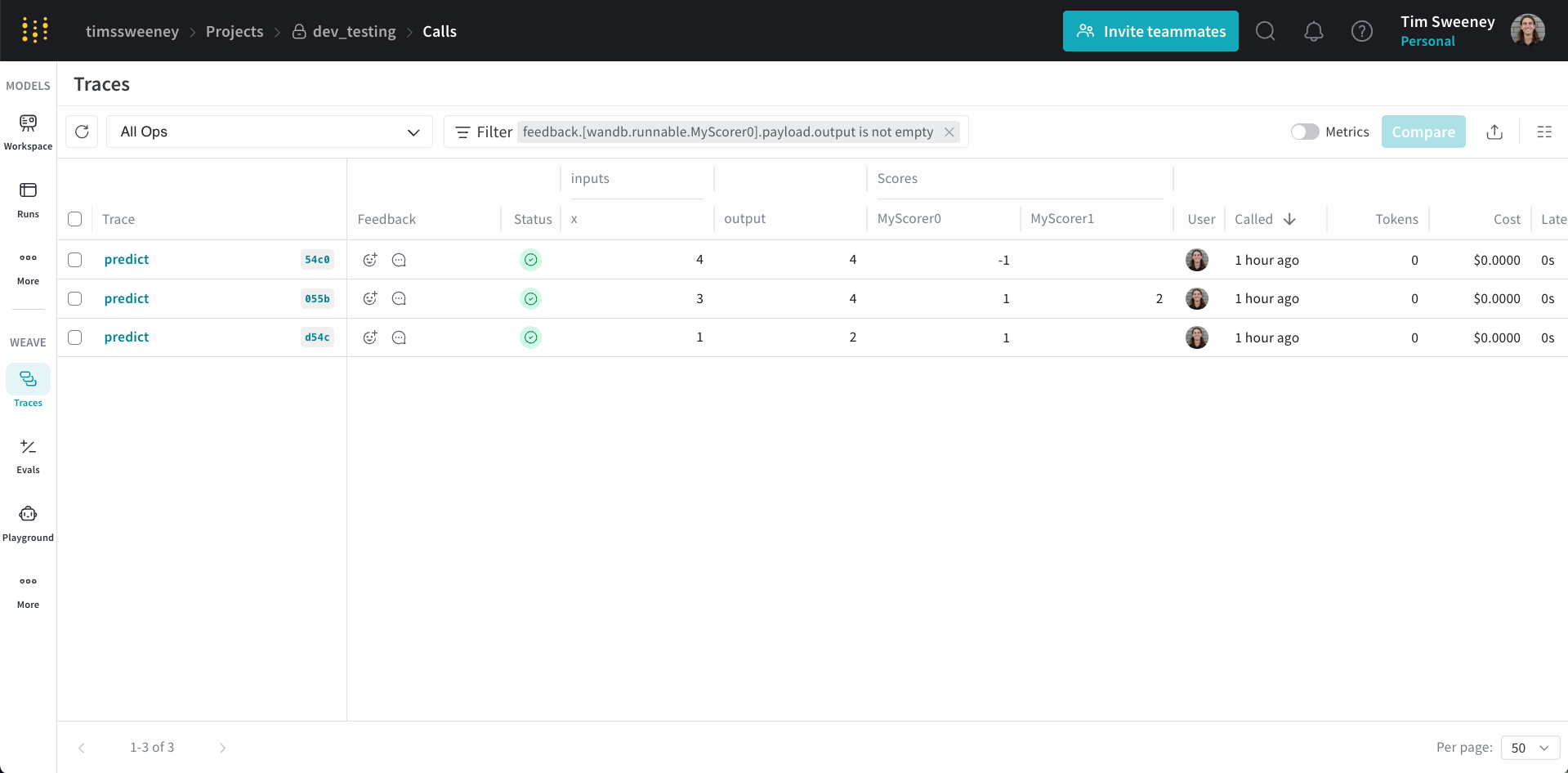
Analyser les scores de plusieurs Appels
API des appels multiples
get_calls.
Interface des appels multiples
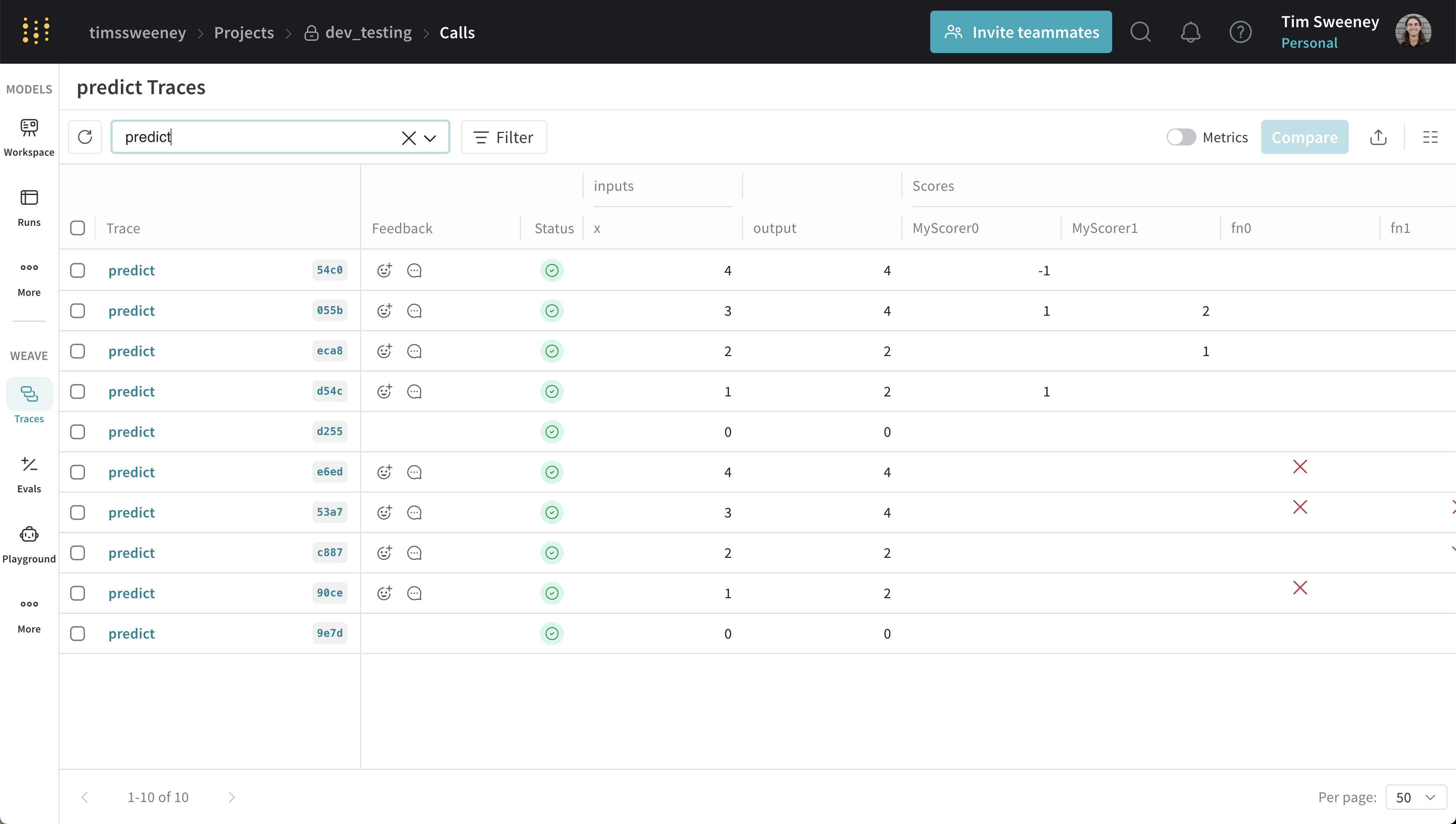
Analyser tous les Appels évalués par un scorer spécifique
API de tous les appels par scorer
get_calls.
Tous les appels d’un Scorer dans l’UI
View Traces sous Scores pour voir tous les appels évalués par votre Scorer.