Comment créer un moniteur dans Weave
- Ouvrez la W&B UI, puis ouvrez votre projet Weave.
- Dans la barre latérale de Weave, sélectionnez Monitors, puis cliquez sur le bouton + New Monitor. La boîte de dialogue Create new monitor s’ouvre.
-
Dans le menu Create new monitor, configurez les champs suivants :
- Nom : doit commencer par une lettre ou un chiffre. Peut contenir des lettres, des chiffres, des tirets et des tirets bas.
- Description (facultatif) : expliquez ce que fait le moniteur.
- Bascule Moniteur actif : activez ou désactivez le moniteur.
- Appels à surveiller :
- Opérations : choisissez une ou plusieurs
@weave.opà surveiller. Vous devez journaliser au moins une trace qui utilise l’op pour qu’elle apparaisse dans la liste des ops disponibles. - Filtre (facultatif) : restreignez les appels éligibles (par exemple, selon
max_tokensoutop_p). - Taux d’échantillonnage : le pourcentage d’appels à scorer (de 0 % à 100 %).
- Opérations : choisissez une ou plusieurs
- Configuration LLM-as-a-judge :
- Nom du scorer : doit commencer par une lettre ou un chiffre. Peut contenir des lettres, des chiffres, des tirets et des tirets bas.
- Scorer l’audio : filtre les modèles LLM disponibles pour n’afficher que les modèles compatibles avec l’audio, et ouvre le champ Media Scoring JSON Paths.
- Scorer les images : filtre les modèles LLM disponibles pour n’afficher que les modèles compatibles avec les images, et ouvre le champ Media Scoring JSON Paths.
- Modèle juge : sélectionnez le modèle qui scorera vos ops. Le menu contient les modèles LLM commerciaux que vous avez configurés dans votre compte W&B, ainsi que les modèles W&B Inference. Les modèles compatibles avec l’audio affichent le libellé Audio Input à côté de leur nom. Pour le modèle sélectionné, configurez les paramètres suivants :
- Nom de la configuration : un nom pour cette configuration de modèle.
- Prompt système : définit le rôle et la personnalité du modèle juge, par exemple, “You are an impartial AI judge.”
- Format de réponse : le format dans lequel le juge doit produire sa réponse, par exemple un
json_objectou dutextbrut. - Prompt de scoring : la tâche d’évaluation utilisée pour scorer vos ops. Vous pouvez référencer des variables de prompt de vos ops dans vos prompts de scoring. Par exemple, “Evaluate whether
{output}is accurate based on{ground_truth}.”
- Media Scoring JSON Paths : spécifiez des expressions JSONPath (RFC 9535) pour extraire des médias de vos données de trace. Si aucun chemin n’est spécifié, tous les médias scorable provenant des messages utilisateur seront inclus. Ce champ apparaît lorsque vous activez Scorer l’audio ou Scorer les images.
- Une fois les champs du moniteur configurés, cliquez sur Create monitor. Cela ajoute le moniteur à votre projet Weave. Lorsque votre code commence à générer des traces, vous pouvez consulter les scores dans l’onglet Traces en sélectionnant le nom du moniteur, puis en examinant les données dans le panneau qui s’affiche.
feedback de l’objet Appel.
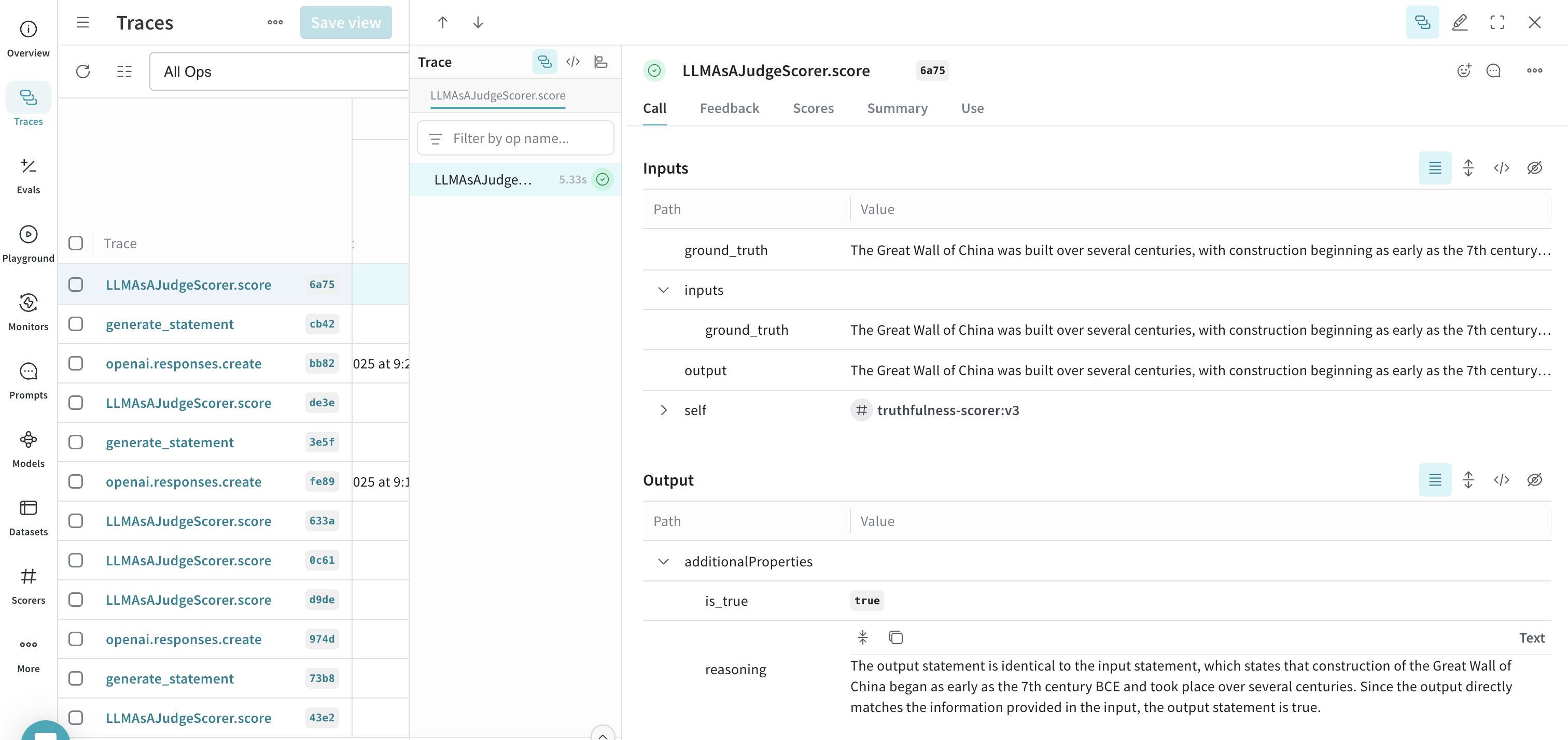
Exemple : créer un moniteur de véracité
- Définissez une fonction qui génère des énoncés. Certains sont vrais, d’autres non :
- Python
- TypeScript
- Exécutez la fonction au moins une fois pour journaliser une trace dans votre projet. Cela rend l’op disponible pour la surveillance dans l’UI W&B.
- Ouvrez votre projet Weave dans l’UI W&B et sélectionnez Monitors dans la barre latérale. Sélectionnez ensuite New Monitor.
-
Dans le menu Create new monitor, configurez les champs avec les valeurs suivantes :
- Name :
truthfulness-monitor - Description :
Évalue la véracité des énoncés générés. - moniteur actif : Activez l’option.
- opération : Sélectionnez
generate_statement. - taux d’échantillonnage : Définissez
100%pour scorer chaque Appel. - nom du scorer :
truthfulness-scorer - modèle juge :
o3-mini-2025-01-31 - prompt système :
You are an impartial AI judge. Your task is to evaluate the truthfulness of statements. - format de réponse :
json_object - prompt de scoring :
- Name :
- Cliquez sur Create Monitor. Cela ajoute le moniteur à votre projet Weave.
- Dans votre script, appelez votre fonction avec des énoncés de véracité variable pour tester la fonction de score :
- Python
- TypeScript
- Après avoir exécuté le script avec plusieurs énoncés différents, ouvrez l’UI W&B et accédez à l’onglet Traces. Sélectionnez n’importe quelle trace LLMAsAJudgeScorer.score pour voir les résultats.