- Python
- TypeScript
Dans Weave, l’objet
Evaluation est au cœur du flux de travail et définit :- Un
Datasetou une liste de dictionnaires pour les exemples de test. - Une ou plusieurs fonctions de scoring.
- Une configuration facultative, comme le prétraitement des entrées.
Evaluation définie, vous pouvez l’exécuter sur un objet Model ou sur toute fonction personnalisée contenant la logique de l’application LLM. Chaque appel à .evaluate() déclenche un run d’évaluation. Considérez l’objet Evaluation comme un plan, et chaque run comme une mesure des performances de votre application dans cette configuration.- Créer un objet
Evaluation - Définir un jeu de données d’exemples
- Définir des fonctions de scoring
- Définir un modèle ou une fonction à évaluer
- Exécuter l’évaluation
1. Créer un objet Evaluation
Evaluation est la première étape pour définir votre configuration d’évaluation. Une Evaluation se compose de données d’exemple, d’une logique d’évaluation et d’un prétraitement facultatif. Vous l’utiliserez ensuite pour exécuter une ou plusieurs évaluations.
Weave prendra chaque exemple, le fera passer par votre application et attribuera un score au résultat à l’aide de plusieurs fonctions de scoring personnalisées. Vous disposerez ainsi d’une vue d’ensemble des performances de votre application, ainsi que d’une UI riche pour examiner en détail les résultats et les scores individuels.
(Facultatif) Nommage personnalisé
- Python
- TypeScript
Il existe deux types de noms personnalisables dans le flux d’évaluation :Nommer l’objet
Pour nommer l’objet
- Nom de l’objet
Evaluation(evaluation_name) : un libellé persistant pour votre objetEvaluationconfiguré. - Nom d’affichage d’un run d’évaluation (
__weave["display_name"]) : un libellé pour une exécution d’évaluation donnée, affiché dans l’interface utilisateur.
Nommer l’objet Evaluation
Pour nommer l’objet Evaluation lui-même, passez un paramètre evaluation_name à la classe Evaluation. Ce nom vous aide à identifier l’objet Evaluation dans le code et dans les listes de l’interface utilisateur.Nommer des runs d’évaluation individuels
Pour nommer un run d’évaluation spécifique (un appel àevaluate()), utilisez le dictionnaire __weave avec un display_name. Cela détermine ce qui est affiché dans l’interface utilisateur pour ce run.2. Définir un jeu de données d’exemples de test
- Python
- TypeScript
L’exemple suivant montre un jeu de données défini comme une liste de dictionnaires :
3. Définir des fonctions de scoring
Dataset.
- Python
- TypeScript
Chaque fonction de scoring doit avoir un paramètre (Facultatif) Définir une classe
Dans certaines applications, vous pouvez vouloir créer des classes
output et renvoyer un dictionnaire contenant les scores. Vous pouvez aussi inclure d’autres entrées issues de vos exemples.Les fonctions de scoring doivent avoir un argument mot-clé output, mais les autres arguments sont définis par l’utilisateur et proviennent des exemples du jeu de données. Seules les clés nécessaires seront prises en compte, à partir d’une clé de dictionnaire basée sur le nom de l’argument.L’exemple de fonction scorer match_score1 ci-dessous utilise la valeur expected du dictionnaire examples pour le scoring.(Facultatif) Définir une classe Scorer personnalisée
Dans certaines applications, vous pouvez vouloir créer des classes Scorer personnalisées. Par exemple, une classe LLMJudge standardisée avec des paramètres spécifiques (par exemple, modèle de chat, prompt), une logique de scoring propre à chaque ligne et un calcul spécifique du score agrégé.Voir le tutoriel sur la définition d’une classe Scorer dans Model-Based Evaluation of RAG applications pour plus d’informations.4. Définir un modèle ou une fonction à évaluer
- Python
- TypeScript
Pour évaluer un Cela exécute
Model, appelez evaluate dessus en utilisant une Evaluation. Les Models sont utilisés lorsque vous avez des paramètres avec lesquels vous souhaitez expérimenter et que vous voulez capturer dans Weave.predict sur chaque exemple et attribue un score à la sortie à l’aide de chaque fonction de scoring.(Facultatif) Définir une fonction à évaluer
Vous pouvez également évaluer une fonction personnalisée suivie par@weave.op().5. Lancez l’évaluation
.evaluate() sur l’objet Evaluation.
- Python
- TypeScript
En supposant un objet
Evaluation nommé evaluation et un objet Model à évaluer nommé model, le code suivant lance un run d’évaluation.(Facultatif) Exécuter plusieurs essais
Vous pouvez définir le paramètretrials sur l’objet Evaluation pour exécuter chaque exemple plusieurs fois.Exemple complet de code d’évaluation
- Python
- TypeScript
L’exemple de code suivant montre un run d’évaluation complet, du début à la fin. Le dictionnaire
examples est utilisé par les fonctions de scoring match_score1 et match_score2 pour évaluer MyModel à partir de la valeur de prompt, ainsi qu’une fonction personnalisée, function_to_evaluate. Les évaluations du Model et de la fonction sont lancées avec asyncio.run(evaluation.evaluate()).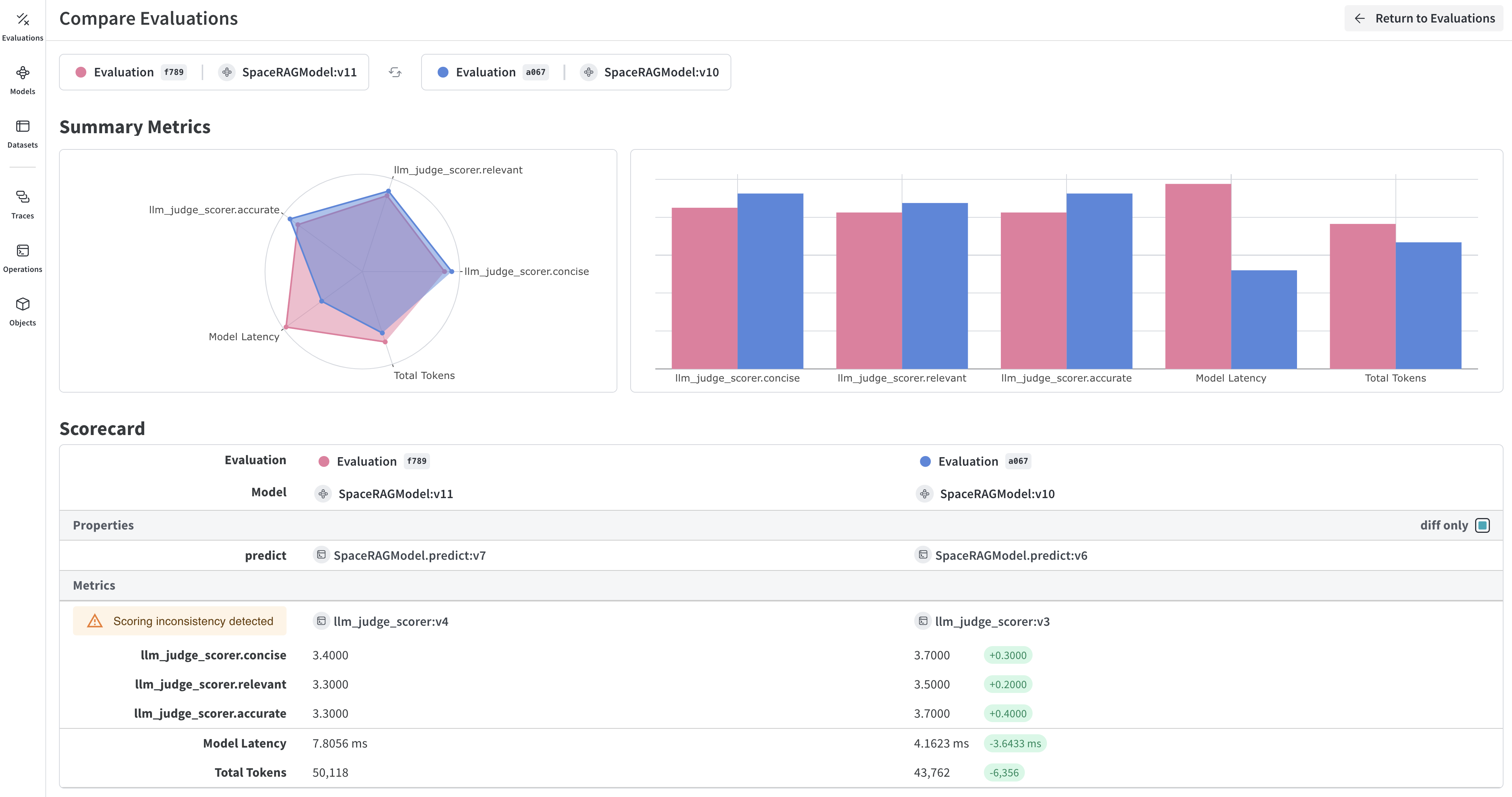
Utilisation avancée de l’évaluation
Formater les lignes du jeu de dataset avant d’évaluer
- Python
- TypeScript
Le paramètre Dans cet exemple, notre jeu de données contient des exemples avec un champ
preprocess_model_input vous permet de transformer les exemples de votre jeu de données avant qu’ils ne soient transmis à votre fonction d’évaluation. Cela est utile lorsque vous devez :- Renommer des champs pour qu’ils correspondent aux entrées attendues par votre modèle
- Transformer les données dans le bon format
- Ajouter ou supprimer des champs
- Charger des données supplémentaires pour chaque exemple
preprocess_model_input pour renommer des champs :input_text, mais notre fonction d’évaluation attend un paramètre question. La fonction preprocess_example transforme chaque exemple en renommant ce champ, ce qui permet à l’évaluation de fonctionner correctement.La fonction de prétraitement :- Reçoit l’exemple brut de votre jeu de données
- Renvoie un dictionnaire contenant les champs attendus par votre modèle
- Est appliquée à chaque exemple avant sa transmission à votre fonction d’évaluation
Utiliser des jeux de données HuggingFace avec les évaluations
- Python
- TypeScript
Nous améliorons continuellement nos intégrations avec des services et des bibliothèques tiers.En attendant des intégrations plus fluides, vous pouvez utiliser
preprocess_model_input comme solution de contournement temporaire pour utiliser des jeux de données HuggingFace dans les évaluations Weave.Voir notre cookbook sur l’utilisation de jeux de données HuggingFace dans les évaluations pour connaître l’approche actuelle.Vues enregistrées
Évaluations impératives (EvaluationLogger)
EvaluationLogger de Weave. EvaluationLogger est disponible en Python et en TypeScript, et offre davantage de flexibilité pour les flux de travail complexes, tandis que le framework d’évaluation standard apporte plus de structure et d’encadrement.