Les jobs d’Évaluation LLM sont en Aperçu sur W&B Multi-tenant Cloud. Les ressources de calcul sont gratuites pendant la période d’aperçu. En savoir plus
Fonctionnement
- Configurez un job d’évaluation dans W&B Models. Définissez ses benchmarks et sa configuration, par exemple pour indiquer s’il doit générer un classement.
- Lancez le job d’évaluation.
- Consultez et analysez les résultats et le classement.
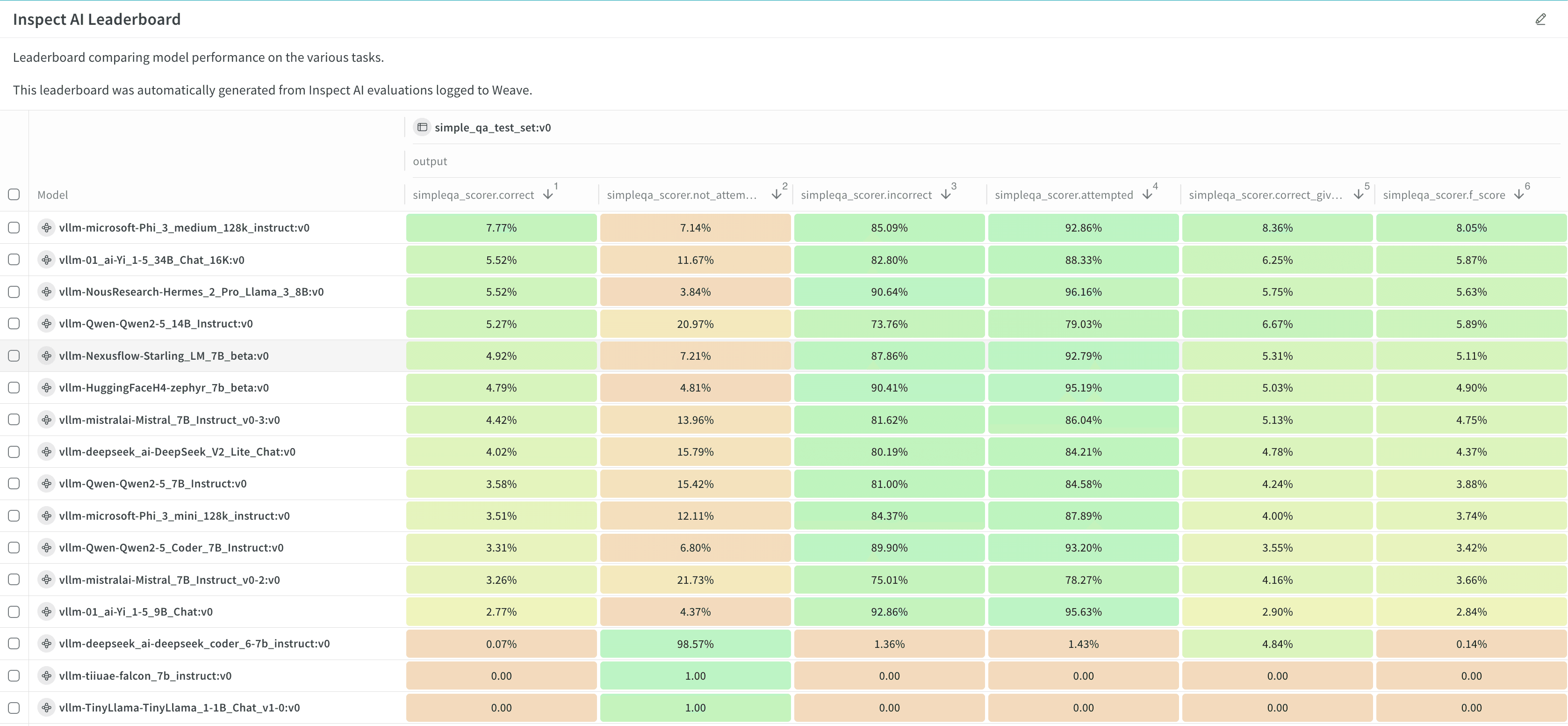
Étapes suivantes
- Parcourez le catalogue des benchmarks d’évaluation
- Évaluez un point de contrôle du modèle
- Évaluez un modèle d’API hébergé
Plus de détails
Tarification
Limites des jobs
- La taille maximale du modèle à évaluer est de 86 Go, contexte compris.
- Chaque job est limité à deux GPU.
Prérequis
- Pour évaluer un point de contrôle du modèle, les poids du modèle doivent être empaquetés dans un artifact compatible avec VLLM. Voir Exemple : préparer un modèle pour plus de détails et un exemple de code.
- Pour évaluer un modèle compatible avec OpenAI, celui-ci doit être accessible via une URL publique, et un administrateur de l’organisation ou de l’équipe doit configurer un secret d’équipe avec la clé API nécessaire à l’authentification.
- Certains benchmarks utilisent des modèles OpenAI pour la notation. Pour exécuter ces benchmarks, un administrateur de l’organisation ou de l’équipe doit configurer des secrets d’équipe avec les clés API requises. Voir le catalogue des benchmarks d’évaluation pour déterminer si un benchmark est concerné par cette exigence.
- Certains benchmarks nécessitent l’accès à des jeux de données à accès restreint dans Hugging Face. Pour exécuter l’un de ces benchmarks, un administrateur de l’organisation ou de l’équipe doit demander l’accès au jeu de données à accès restreint dans Hugging Face, générer un jeton d’accès utilisateur Hugging Face et le configurer comme secret d’équipe. Voir le catalogue des benchmarks d’évaluation pour déterminer si un benchmark est concerné par cette exigence.