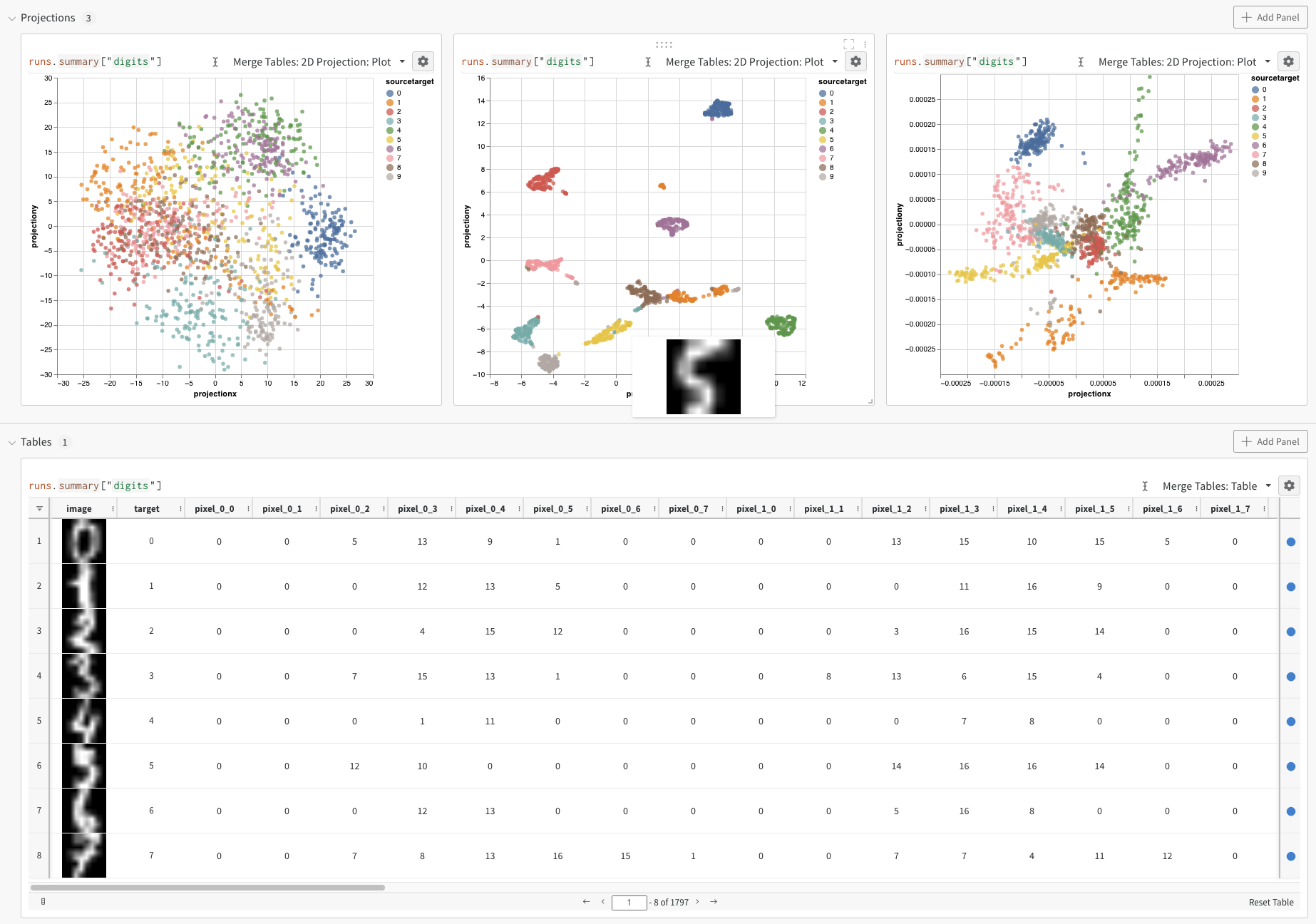
Exemples d’embeddings
Hello World
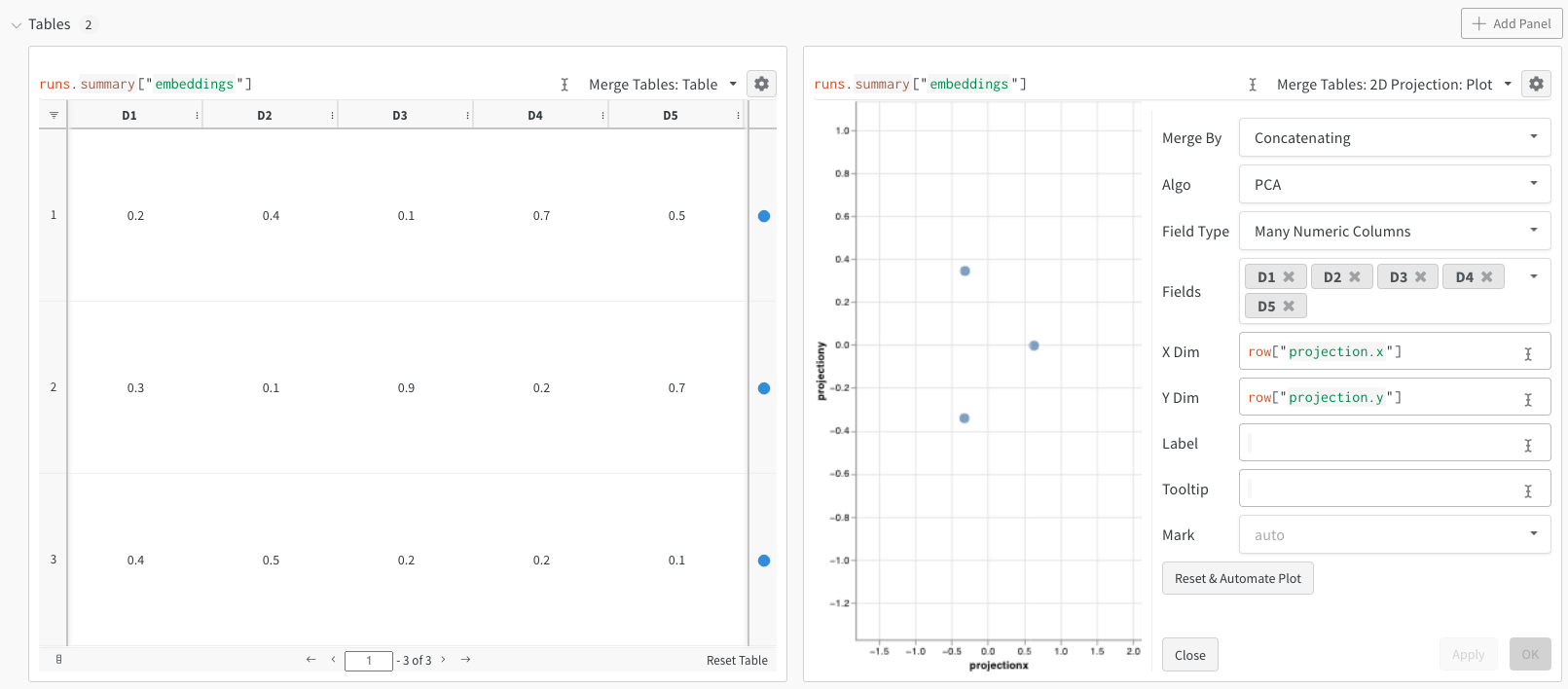
wandb.Table. Prenez l’exemple suivant de 3 embeddings, chacun composé de 5 dimensions :
2D Projection dans le sélecteur de panneau en haut à droite pour représenter les embeddings en 2 dimensions. L’option Smart default sera sélectionnée automatiquement, mais vous pouvez facilement la remplacer dans le menu de configuration accessible en cliquant sur l’icône d’engrenage. Dans cet exemple, nous utilisons automatiquement les 5 dimensions numériques disponibles.
Chiffres MNIST
2D Projection, vous pouvez configurer la définition de l’embedding, la couleur, l’algorithme (PCA, UMAP, t-SNE), les paramètres de l’algorithme, et même la superposition (dans ce cas, l’image s’affiche lorsque vous survolez un point). Dans ce cas précis, il s’agit uniquement de “valeurs par défaut intelligentes”, et vous devriez obtenir quelque chose de très similaire en cliquant simplement sur 2D Projection. (Interagissez avec cet exemple du tutoriel sur les embeddings).
Options de journalisation
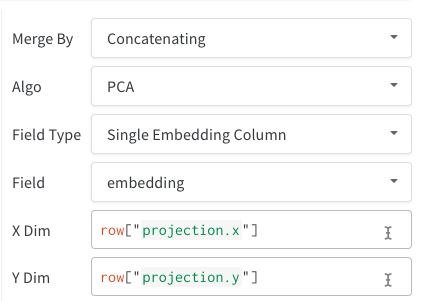
- Colonne d’embedding unique : Souvent, vos données sont déjà dans un format de type « matrice ». Dans ce cas, vous pouvez créer une seule colonne d’embedding, où le type de données des valeurs de cellule peut être
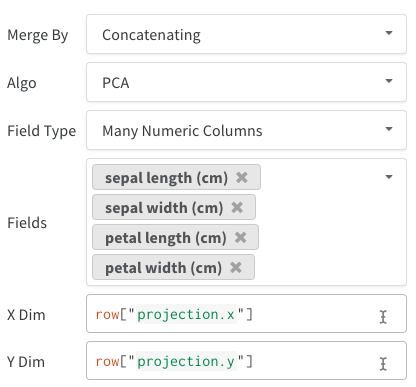
list[int],list[float]ounp.ndarray. - Plusieurs colonnes numériques : Dans les deux exemples ci-dessus, nous utilisons cette approche et créons une colonne pour chaque dimension. Nous acceptons actuellement des
intoufloatPython pour les cellules.
- Directement à partir d’un dataframe avec
wandb.Table(dataframe=df) - Directement à partir d’une liste de données avec
wandb.Table(data=[...], columns=[...]) - Construire le tableau de manière incrémentielle, ligne par ligne (idéal si vous avez une boucle dans votre code). Ajoutez des lignes à votre tableau avec
table.add_data(...) - Ajouter une colonne d’embedding à votre tableau (idéal si vous avez une liste de prédictions sous forme d’embeddings) :
table.add_col("col_name", ...) - Ajouter une colonne calculée (idéal si vous avez une fonction ou un modèle à appliquer à votre tableau) :
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
Options de tracé
2D Projection, vous pouvez cliquer sur l’icône d’engrenage pour modifier les paramètres de rendu. En plus de sélectionner les colonnes souhaitées (voir ci-dessus), vous pouvez choisir l’algorithme voulu (ainsi que les paramètres souhaités). Ci-dessous, vous pouvez voir les paramètres d’UMAP et de t-SNE, respectivement.
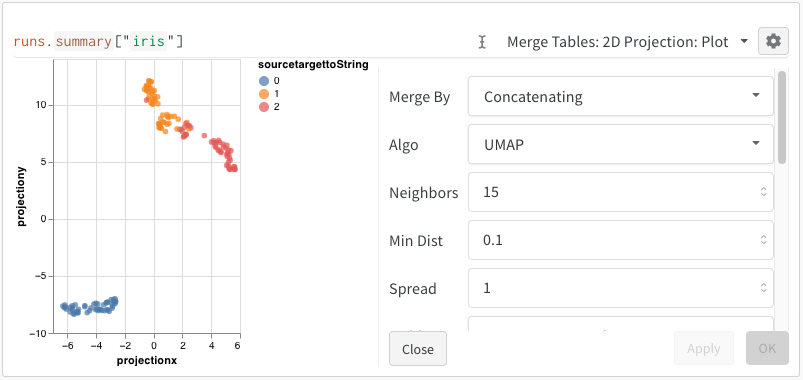
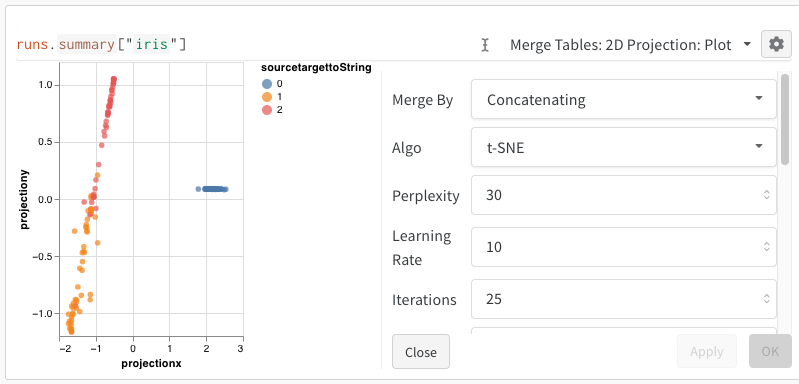
Remarque : nous sous-échantillonnons actuellement un sous-ensemble aléatoire de 1 000 lignes et 50 dimensions pour les trois algorithmes.