시작하기
uv를 사용해 Verifiers 라이브러리를 설치하세요(라이브러리 작성자들이 권장하는 방법). 다음 명령어 중 하나로 라이브러리를 설치하세요:
롤아웃 추적 및 평가하기
실험 추적과 트레이싱으로 모델 파인튜닝하기
verifiers 리포지토리에는 바로 실행해 볼 수 있는 예제가 포함되어 있어 시작하는 데 도움이 됩니다.
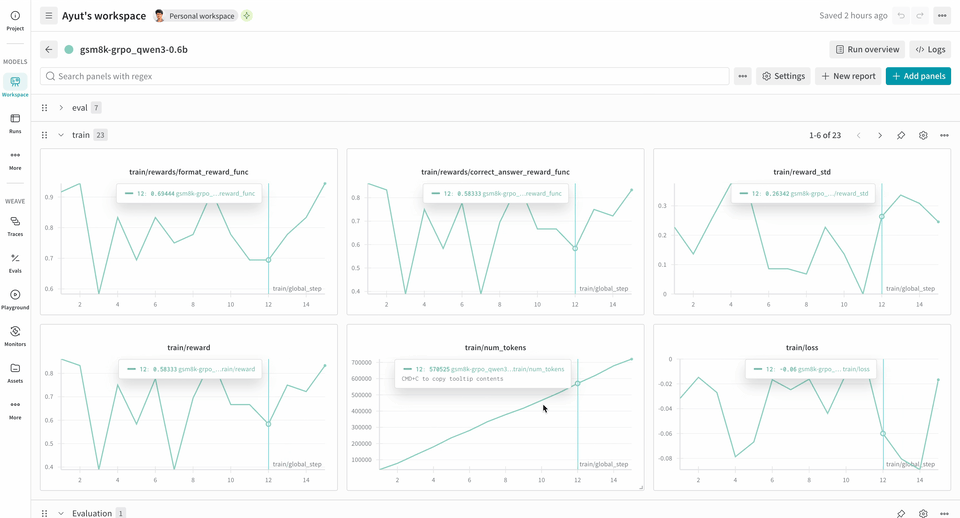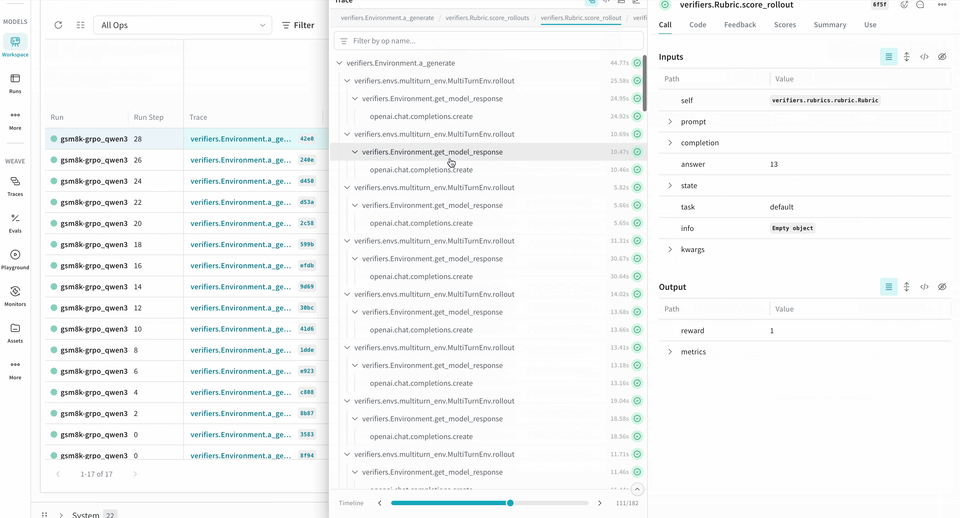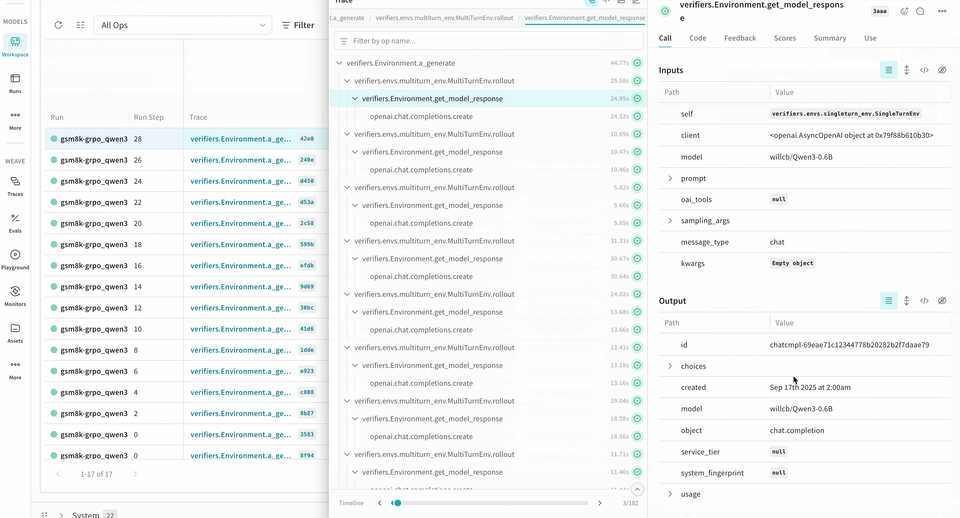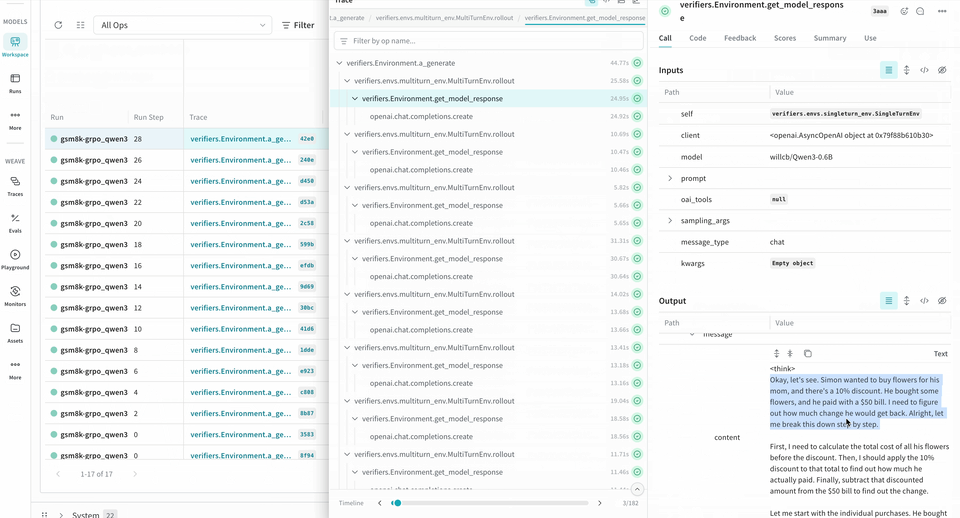
다음 예제 RL 트레이닝 파이프라인은 로컬 추론 서버를 실행하고 GSM8K 데이터셋을 사용해 모델을 트레이닝합니다. 모델은 수학 문제에 대한 답을 생성하고, 트레이닝 루프는 출력에 점수를 매긴 뒤 그에 따라 모델을 업데이트합니다. W&B는 loss, reward, accuracy와 같은 트레이닝 메트릭을 로깅하고, Weave는 입력, 출력, 추론 과정과 점수를 캡처합니다.
이 파이프라인을 사용하려면:
- 소스에서 프레임워크를 설치합니다. 다음 명령은 GitHub에서 Verifiers 라이브러리와 필요한 의존성을 설치합니다:
- 기성 환경을 설치합니다. 다음 명령은 사전 구성된 GSM8K 트레이닝 환경을 설치합니다.
- 모델을 트레이닝합니다. 다음 명령은 각각 추론 서버와 트레이닝 루프를 실행합니다. 이 예시 워크플로는 기본적으로
report_to=wandb로 설정되어 있으므로 별도로wandb.init을 호출할 필요가 없습니다. 이 머신이 W&B에 메트릭을 기록할 수 있도록 인증하라는 메시지가 표시됩니다.
이 예제는 2xH100 환경에서 성공적으로 테스트되었으며, 안정성을 높이기 위해 다음 환경 변수를 설정했습니다:이 변수들은 디바이스 메모리 할당에 대해 CUDA Unified Memory(CuMem)를 비활성화합니다.
Environment.a_generate 및 Rubric.score_rollouts 메서드에 대해서는 logprobs를 기록하지 않습니다. 이렇게 하면 페이로드 크기를 줄이면서, 트레이닝을 위해 원본은 그대로 유지할 수 있습니다.