weave.op을 사용해 Bedrock 모델에 대한 모든 호출을 추적하기 위한 재사용 가능한 연산을 만들 수 있습니다. 선택적으로, Anthropic 모델을 사용하는 경우 Weave에 내장된 Anthropic 인테그레이션을 사용할 수 있습니다.
트레이스
converse API 사용 예:
직접 정의한 op로 래핑하기
@weave.op() 데코레이터를 사용해서 재사용 가능한 연산을 만들 수 있습니다. 다음 예시는 invoke_model과 converse API를 모두 사용하는 방법을 보여 줍니다.
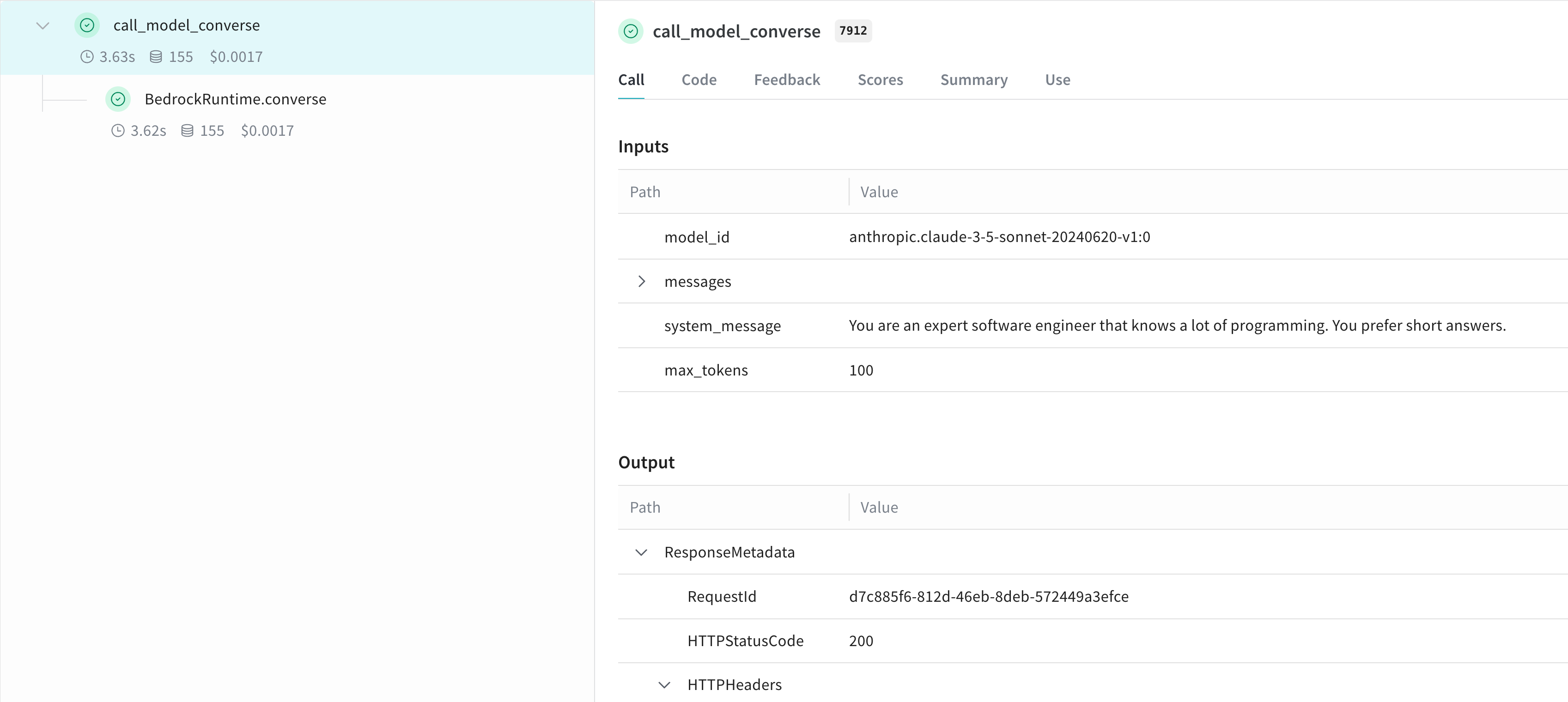
더 쉬운 실험을 위해 Model 생성하기
converse API를 사용하는 예시입니다: