데이터셋 CSV 파일 가져오기 및 로그 기록
- 시작하려면 먼저 CSV 파일을 가져오세요. 다음 코드 스니펫에서
iris.csv파일 이름을 사용자의 CSV 파일 이름으로 바꾸세요:
- CSV 파일을 W&B Table로 변환해 W&B Dashboards에서 활용합니다.
- 다음으로 W&B Artifact를 생성하고 테이블을 해당 Artifact에 추가합니다:
- 마지막으로,
wandb.init을 사용해 새로운 W&B Run을 시작하여 W&B에 추적하고 로깅하세요:
wandb.init() API는 데이터를 Run에 로깅하기 위해 새로운 백그라운드 프로세스를 생성하고, (기본적으로) 데이터를 wandb.ai와 동기화합니다. 실시간 시각화는 W&B Workspace 대시보드에서 확인할 수 있습니다. 아래 이미지는 코드 스니펫 데모를 실행했을 때의 출력 예시를 보여줍니다.
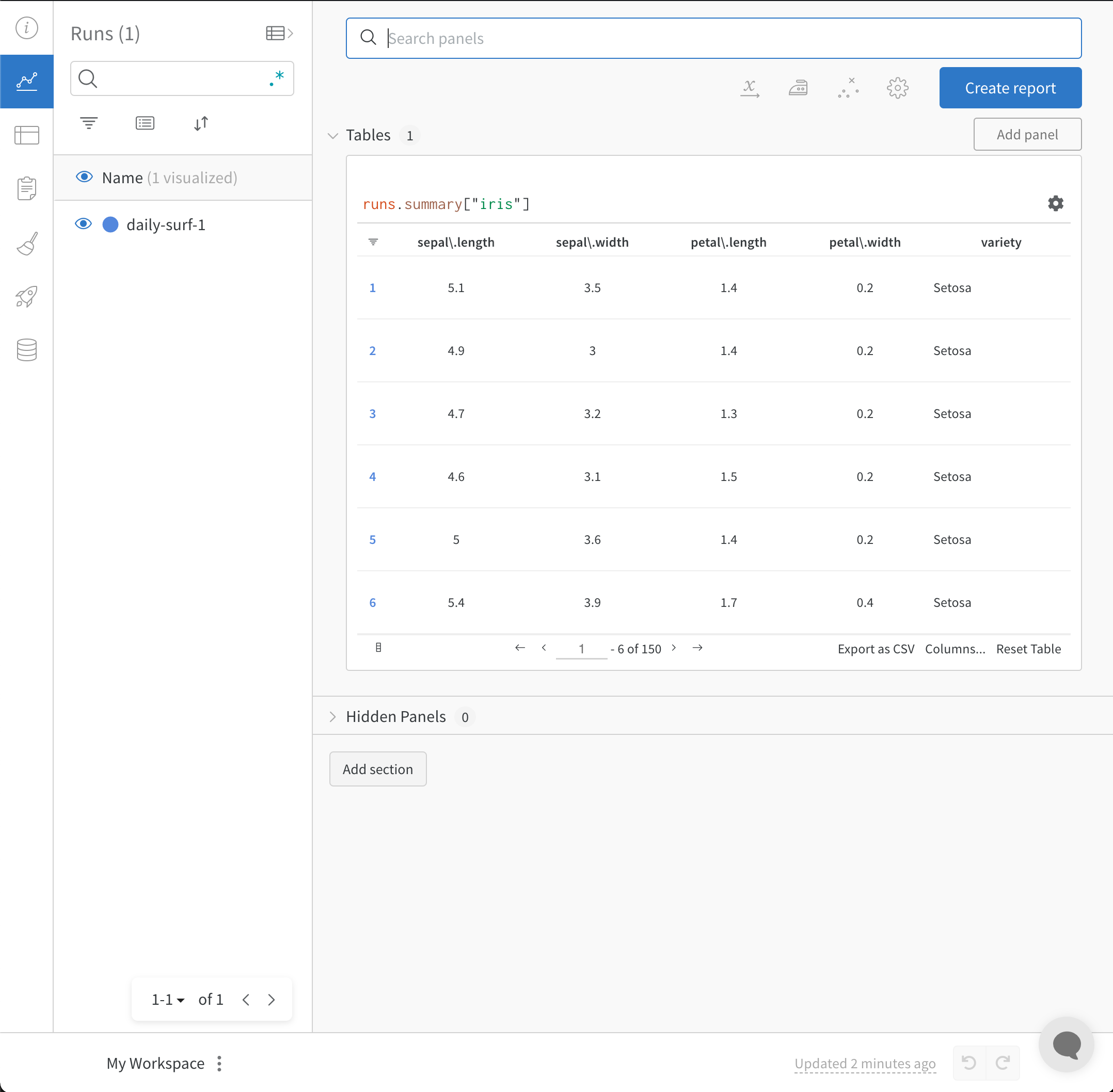
Experiments CSV를 가져와 로깅하기
- 실험 run의 이름
- 초기 노트
- 실험을 구분하기 위한 태그
- 실험에 필요한 설정(추가로 Sweeps Hyperparameter Tuning을 활용할 수 있는 이점 포함)
| 실험 | 모델 이름 | 노트 | 태그 | 레이어 수 | 최종 트레이닝 정확도 | 최종 검증 정확도 | 트레이닝 손실 |
|---|---|---|---|---|---|---|---|
| Experiment 1 | mnist-300-layers | 트레이닝 데이터에 과적합이 심하게 발생 | [latest] | 300 | 0.99 | 0.90 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 2 | mnist-250-layers | 현재 최고의 모델 | [prod, best] | 250 | 0.95 | 0.96 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 3 | mnist-200-layers | 베이스라인 모델보다 성능이 더 나쁨. 디버깅 필요 | [debug] | 200 | 0.76 | 0.70 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| … | … | … | … | … | … | … | |
| Experiment N | mnist-X-layers | 노트 | … | … | … | … | […, …] |
- 먼저 CSV 파일을 읽어 Pandas DataFrame으로 변환합니다.
"experiments.csv"를 사용 중인 CSV 파일 이름으로 바꾸십시오:
-
다음으로, 새로운 W&B Run을 시작하여
wandb.init()으로 W&B에 추적 정보와 로그를 기록합니다:
run.log() 메서드를 사용합니다:
define_metric API를 사용해 run의 결과를 나타내는 최종 요약 메트릭을 기록할 수 있습니다. 이 예제에서는 run.summary.update()를 사용해 run에 요약 메트릭을 추가합니다: