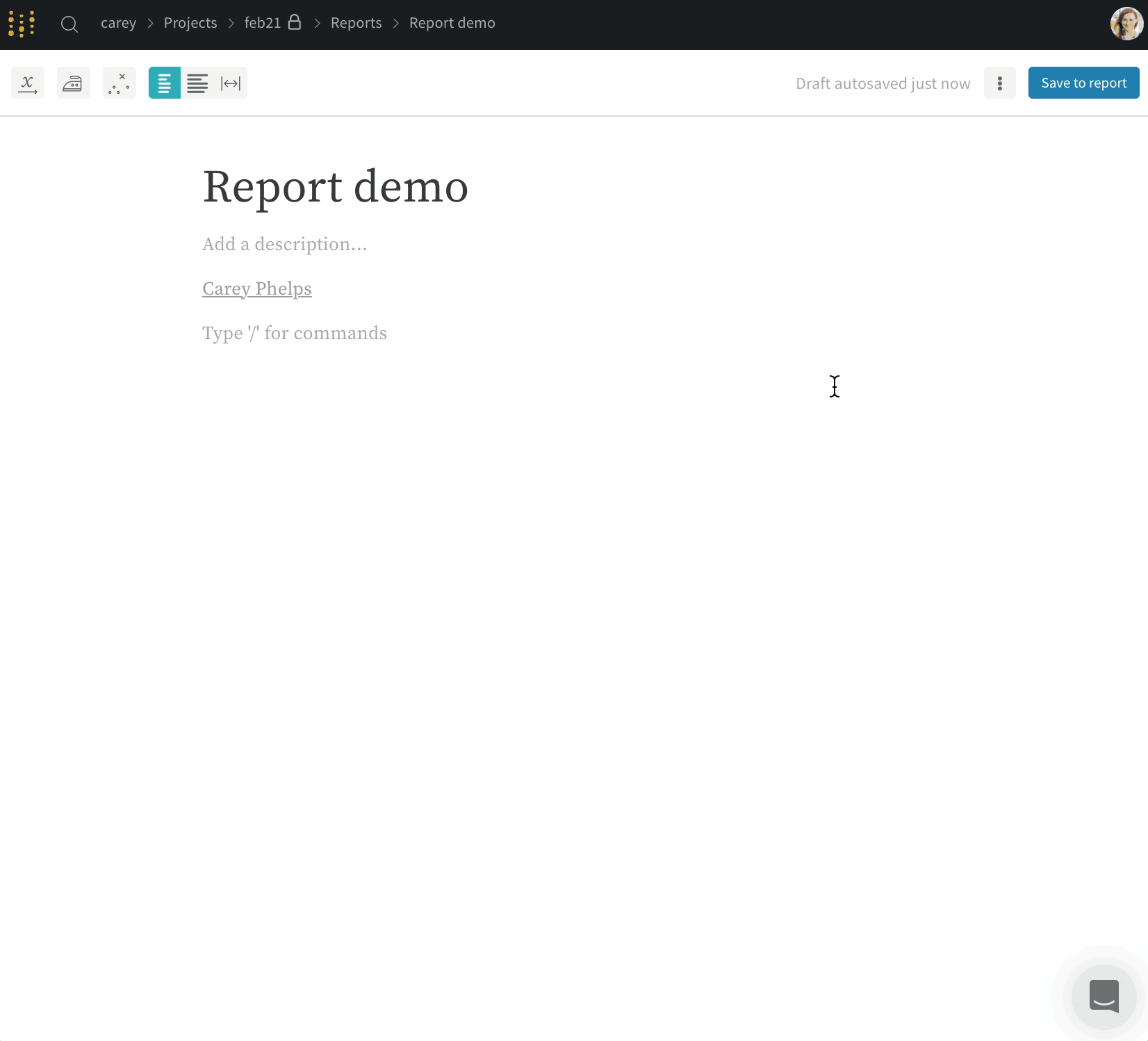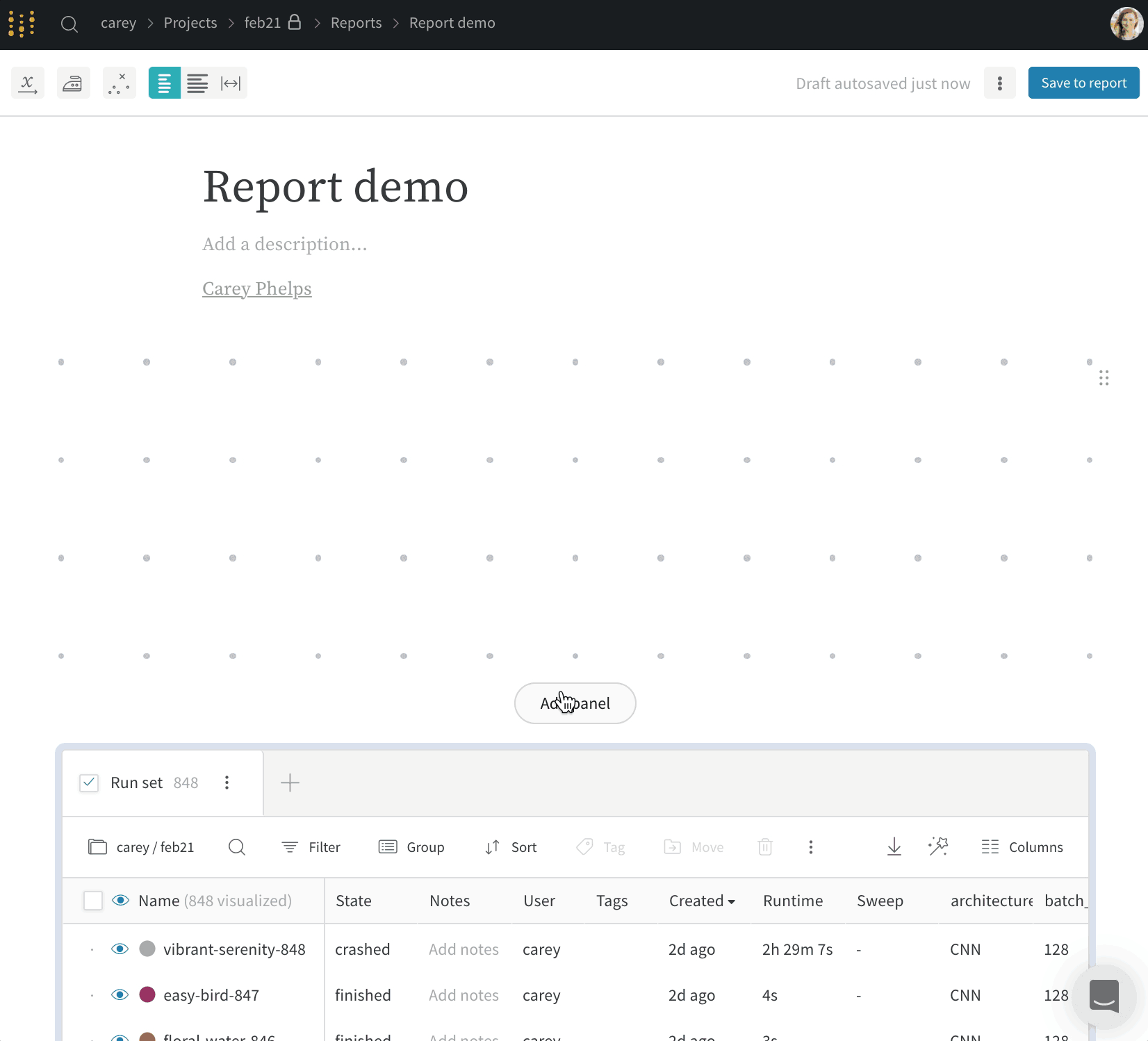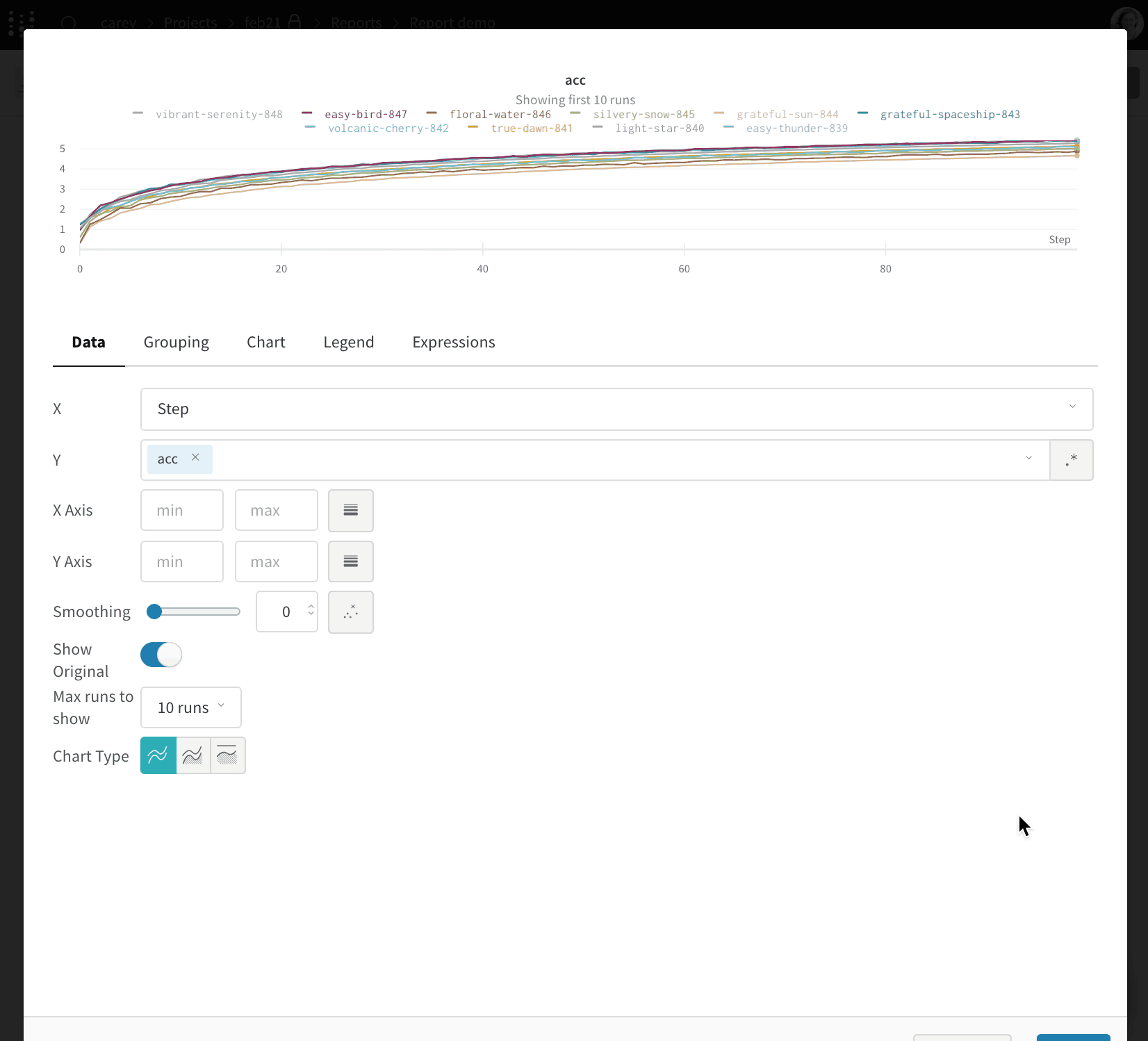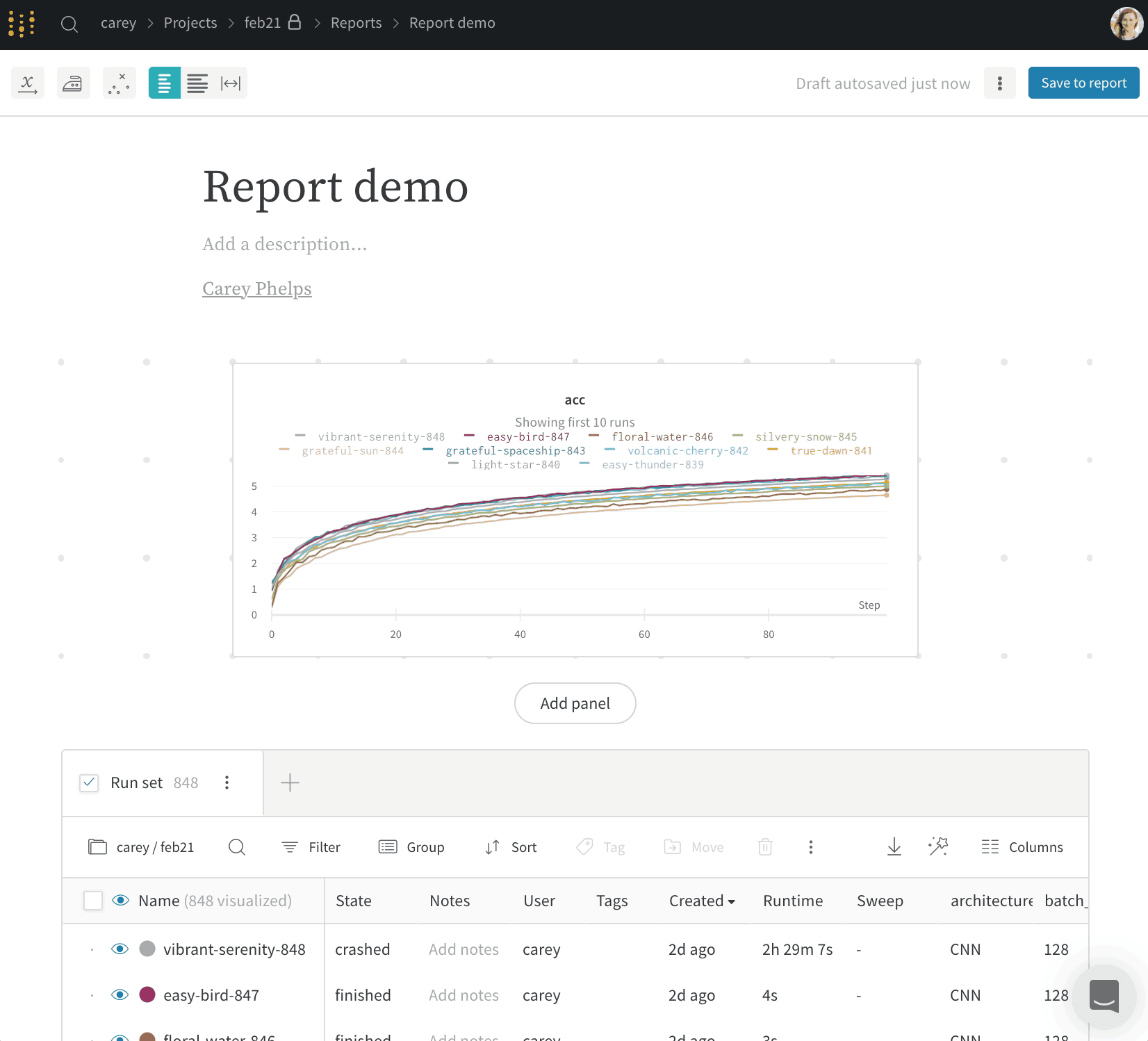
W&B Report 및 Workspace API는 Public Preview 단계입니다.
리포트를 프로그래밍 방식으로 편집하려면 W&B Python SDK 외에 W&B Report 및 Workspace API인 wandb-workspaces가 설치되어 있는지 확인하세요:pip install wandb wandb-workspaces
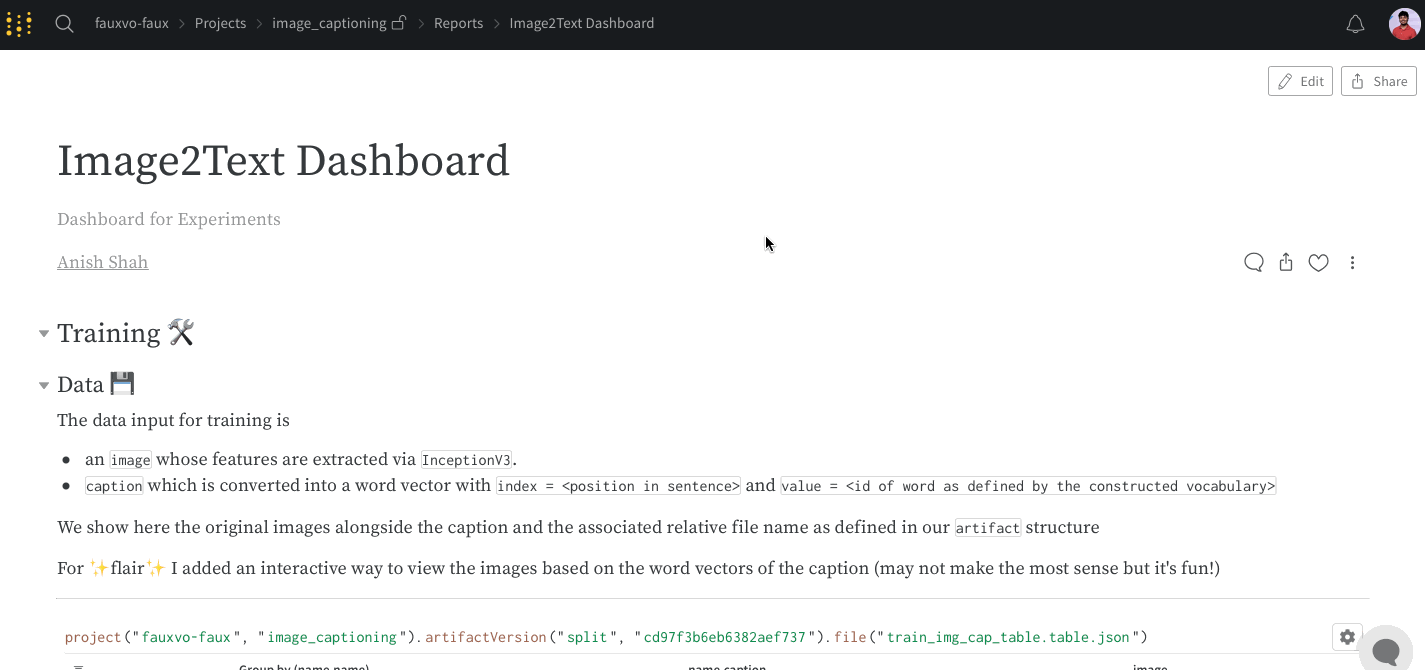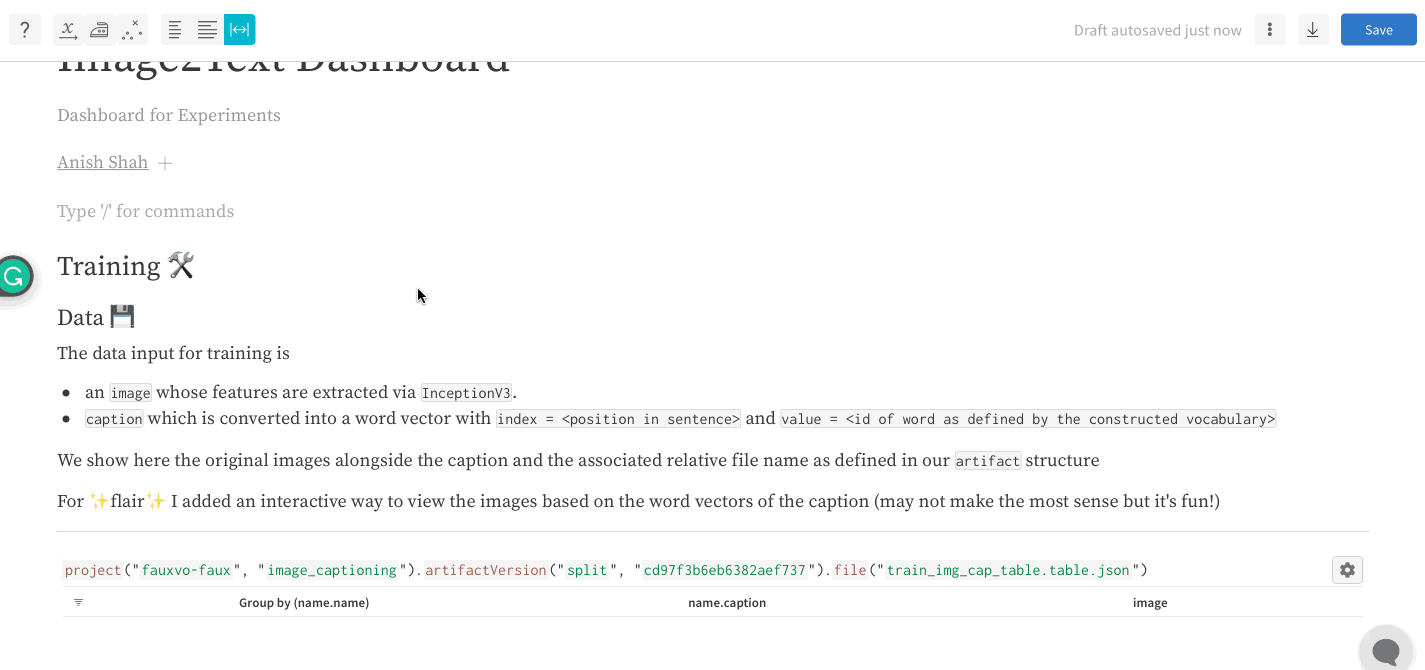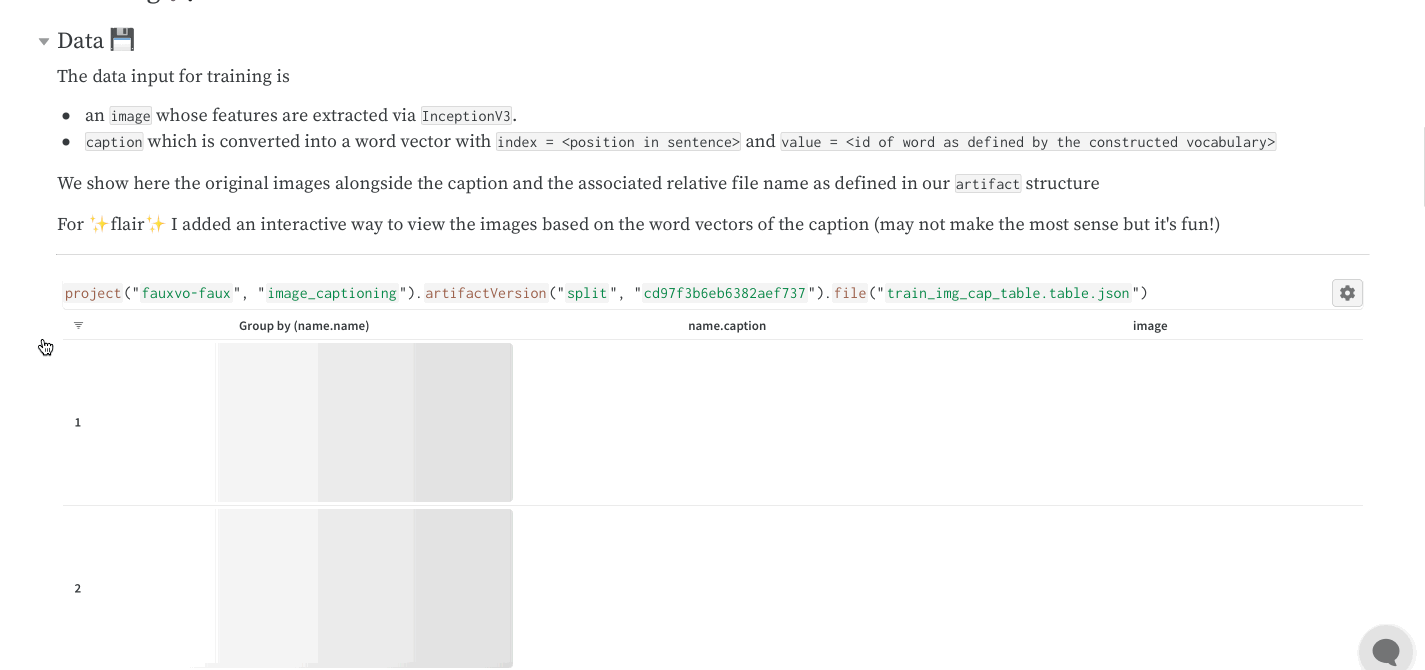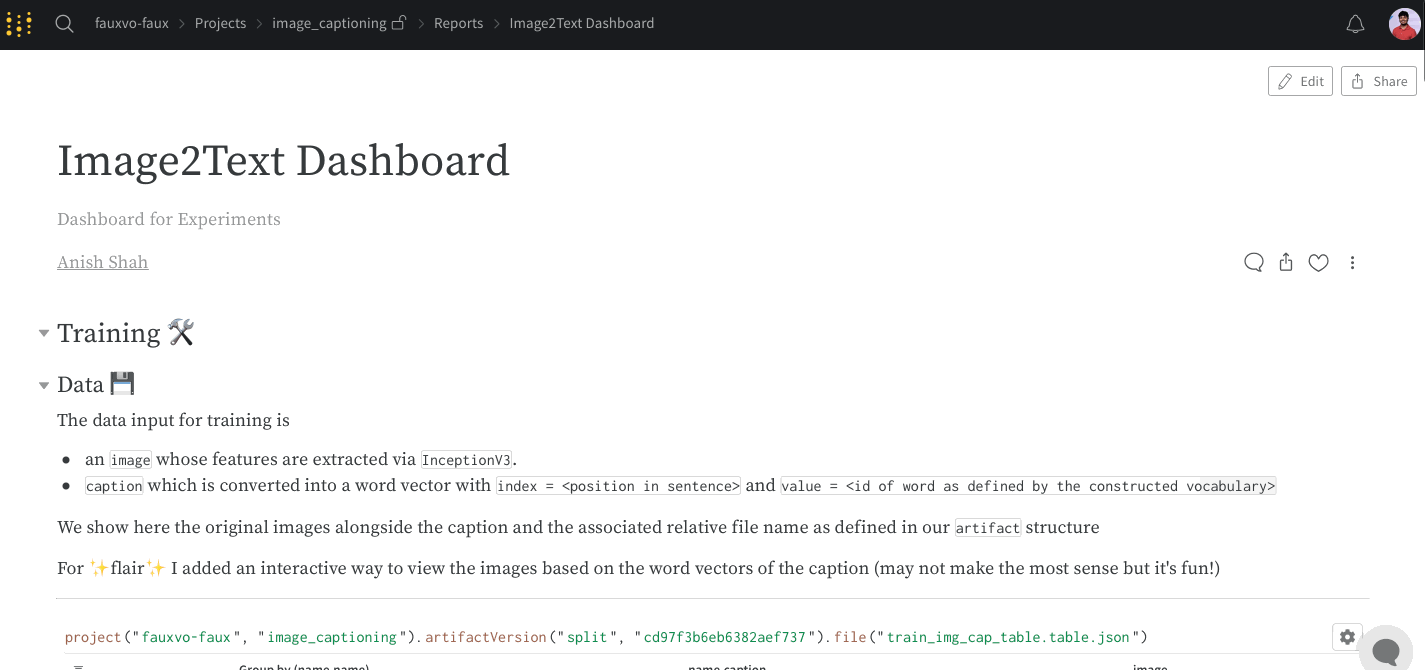
W&B App
Report and Workspace API
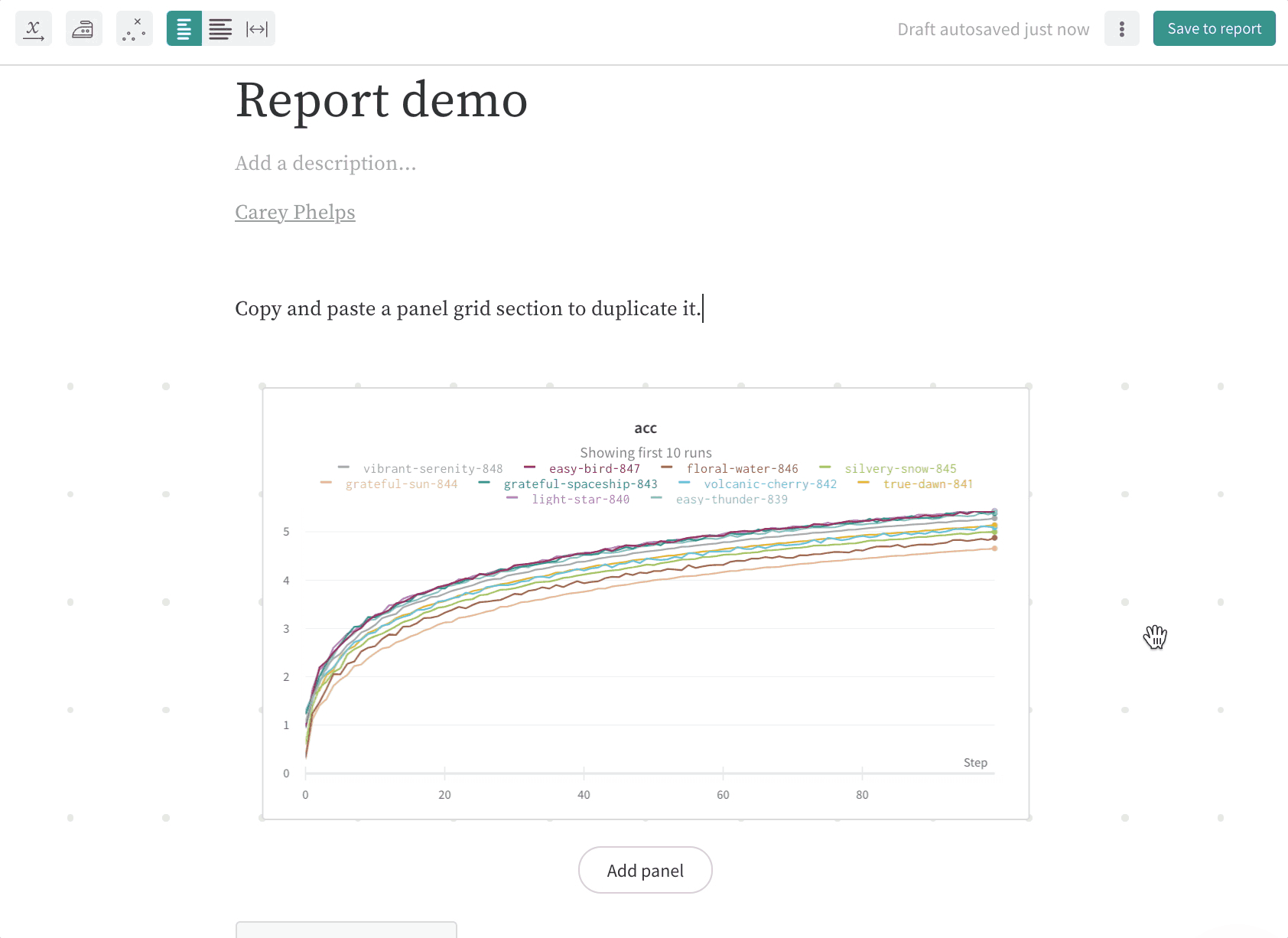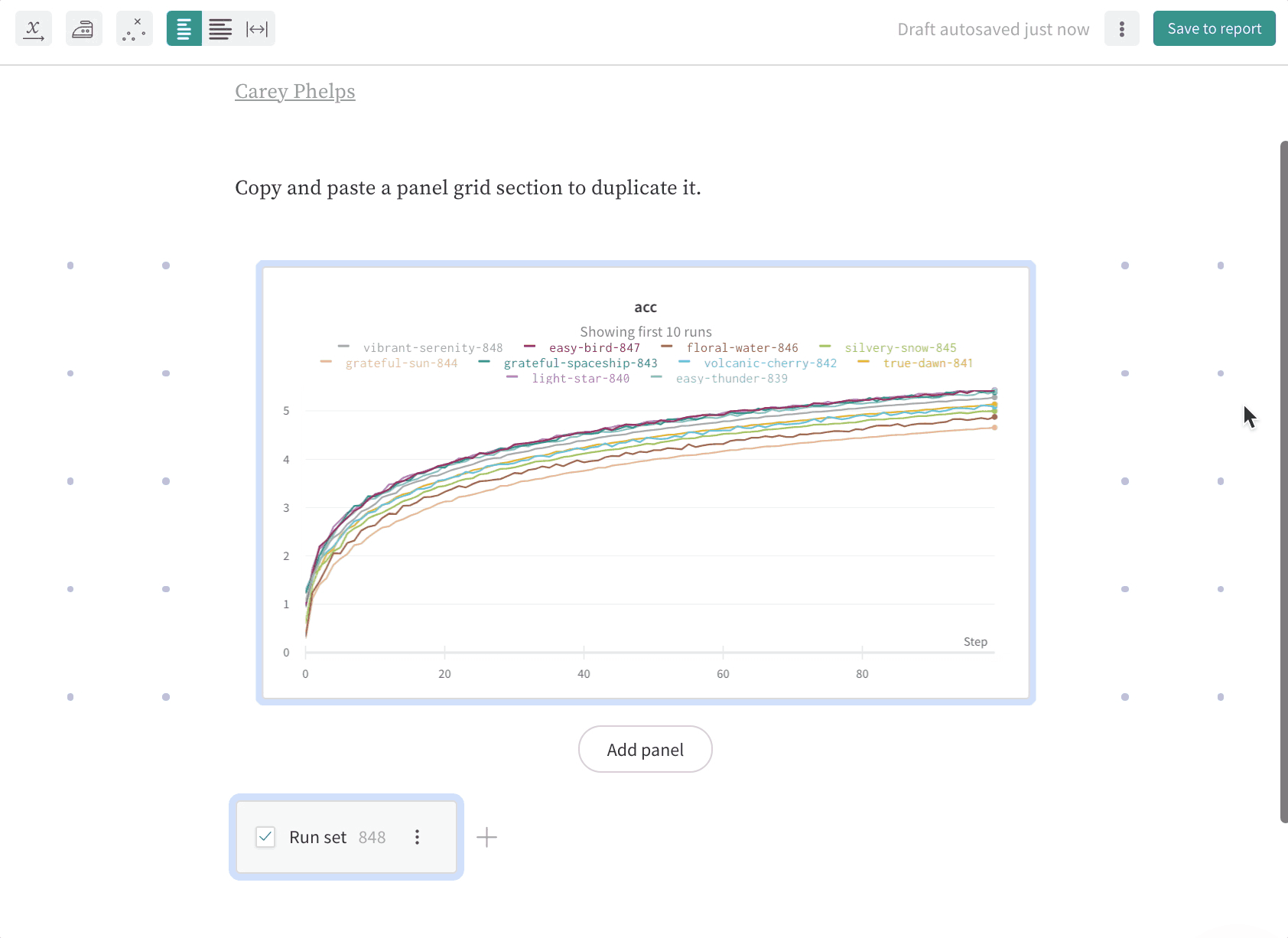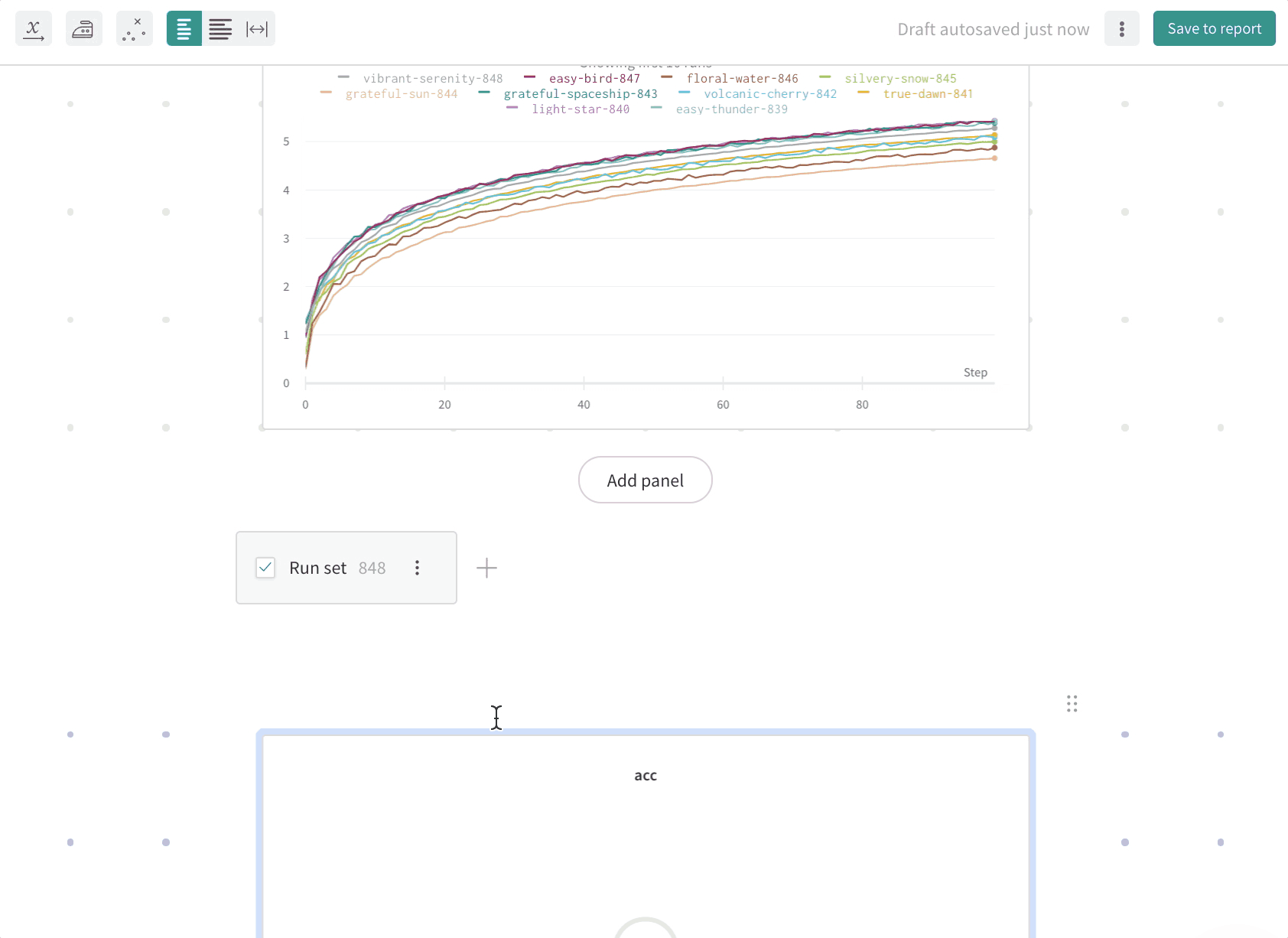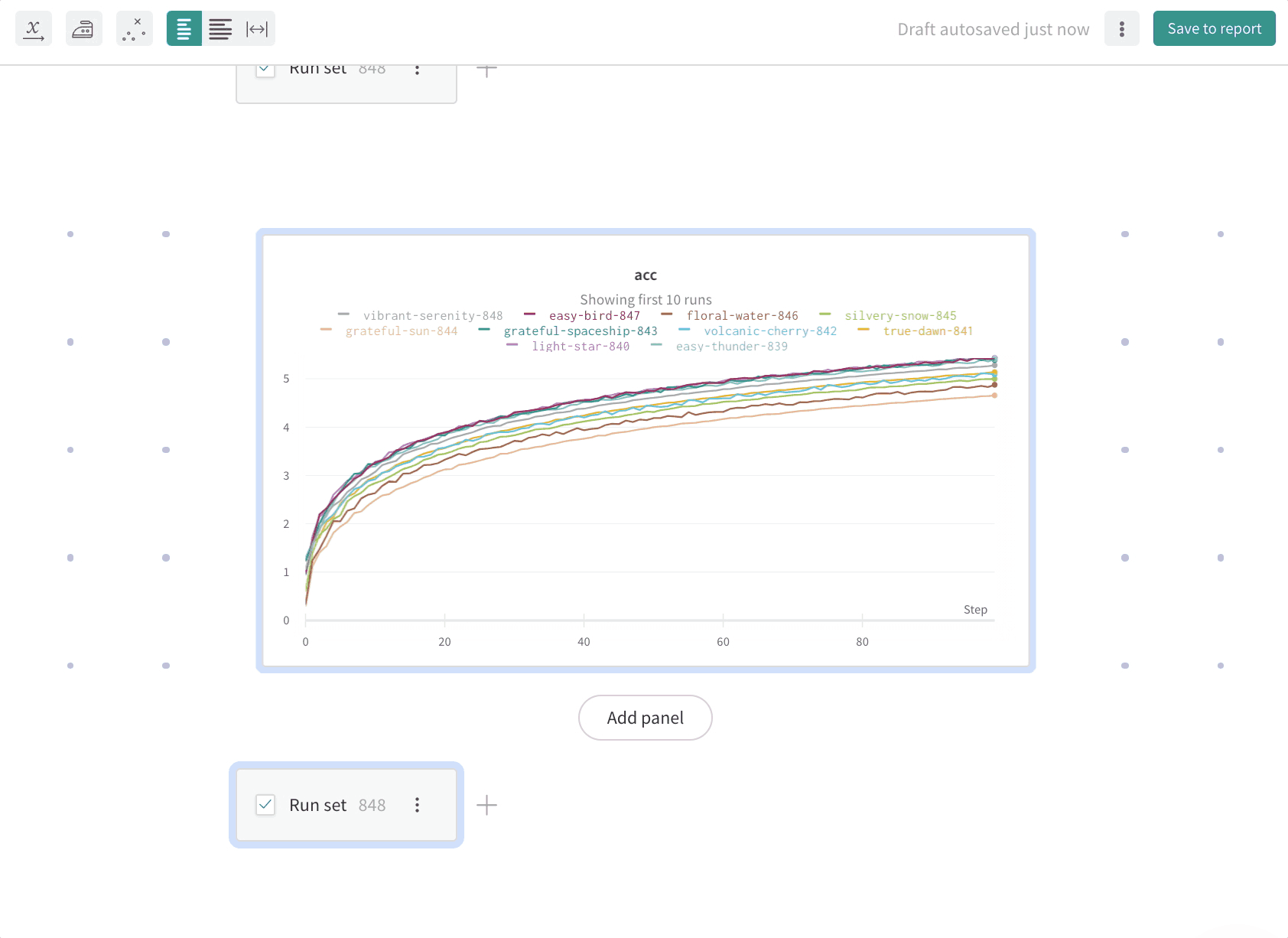
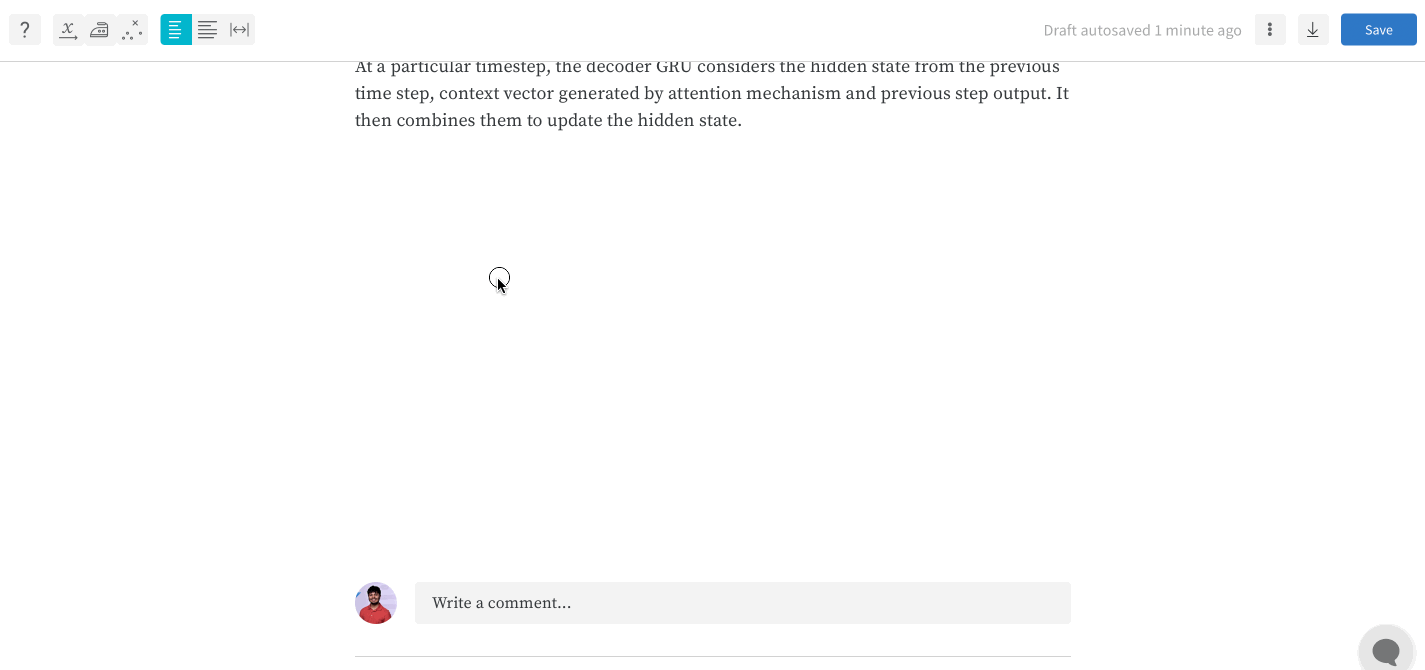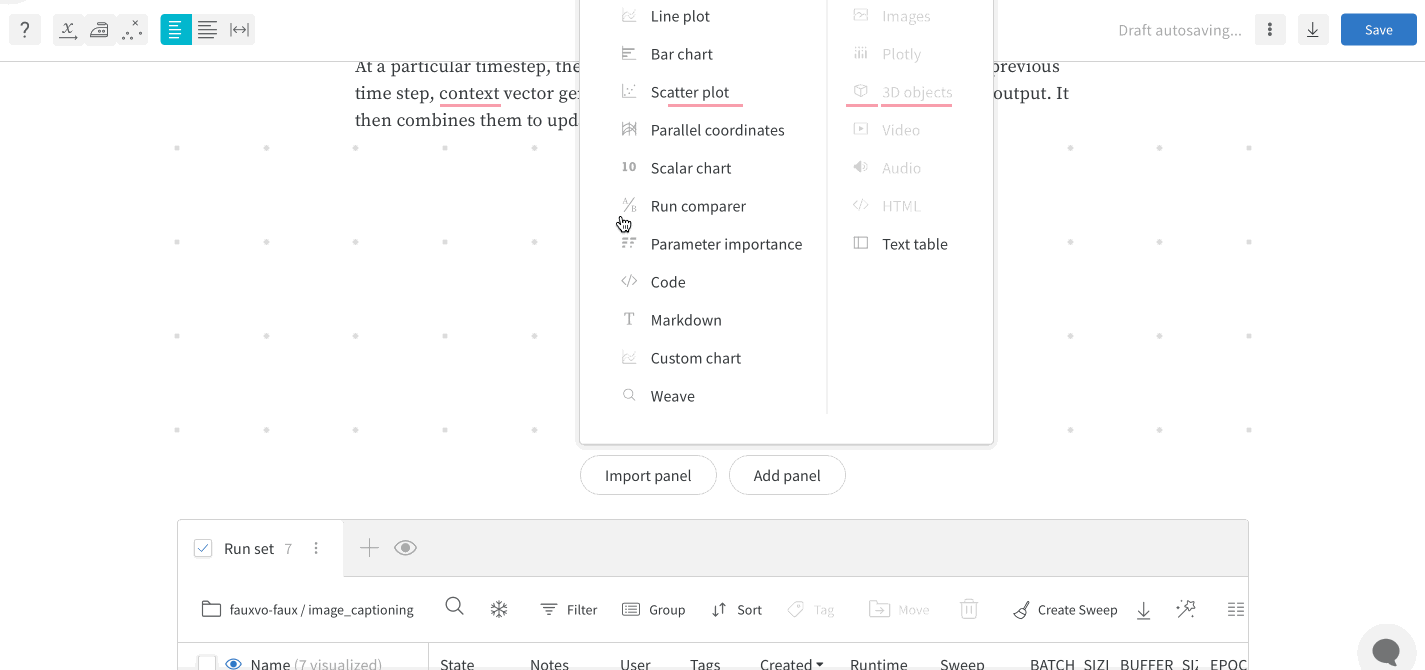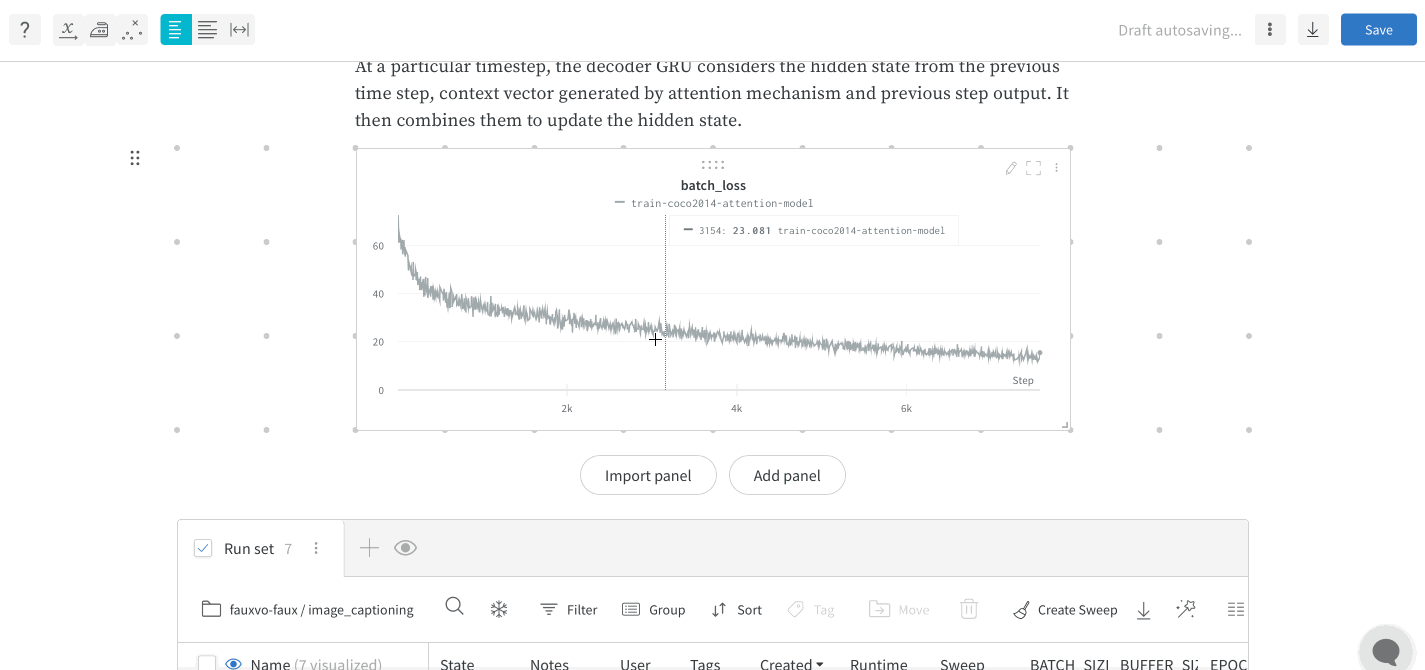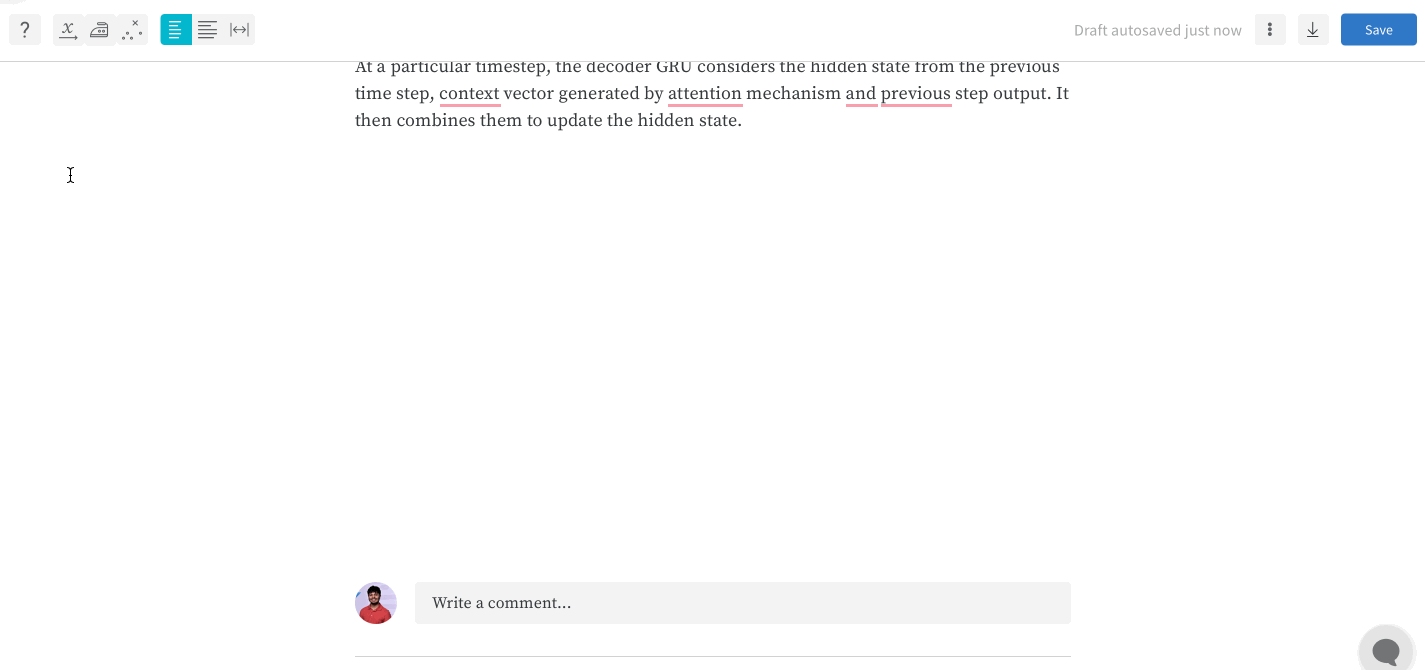
리포트에서 슬래시(/)를 입력하면 드롭다운 메뉴가 표시됩니다. 패널을 추가하려면 Add panel을 선택합니다. 라인 플롯(line plot), 산점도(scatter plot), 평행 좌표(parallel coordinates) 차트 등 W&B에서 지원하는 모든 패널을 추가할 수 있습니다. SDK를 사용해 프로그래밍 방식으로 리포트에 플롯을 추가할 수 있습니다. 하나 이상의 플롯 또는 차트 객체 목록을 PanelGrid Public API 클래스의 panels 파라미터에 전달합니다. 관련 Python 클래스와 함께 플롯 또는 차트 객체를 생성합니다.아래 예제는 라인 플롯과 산점도를 생성하는 방법을 보여줍니다.import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(
project="report-editing",
title="An amazing title",
description="A descriptive description.",
)
blocks = [
wr.PanelGrid(
panels=[
wr.LinePlot(x="time", y="velocity"),
wr.ScatterPlot(x="time", y="acceleration"),
]
)
]
report.blocks = blocks
report.save()
wr.panels를 참조하세요. W&B App
Report and Workspace API
리포트에서 슬래시(/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 Panel Grid를 선택합니다. 그러면 리포트가 생성된 프로젝트의 run 세트가 자동으로 가져와집니다.패널을 리포트에 가져오면 run 이름은 프로젝트에서 상속됩니다. 리포트에서 독자가 더 잘 이해할 수 있도록 필요하다면 run 이름 바꾸기를 할 수 있습니다. run 이름은 해당 개별 패널에서만 변경됩니다. 동일한 리포트에서 패널을 복제하면, 복제된 패널에서도 run 이름이 변경됩니다.
-
리포트에서 연필 아이콘을 클릭해 리포트 편집기를 엽니다.
-
run 세트에서 이름을 변경할 run을 찾습니다. 리포트 이름 위에 마우스를 올리고 세로 점 3개 아이콘을 클릭합니다. 다음 선택지 중 하나를 선택한 뒤, 폼을 제출합니다.
- Rename run for project: 전체 프로젝트에 걸쳐 run 이름을 변경합니다. 새 임의 이름을 생성하려면 필드를 비워 둡니다.
- Rename run for panel grid: 다른 컨텍스트에서 기존 이름은 유지한 채, 이 리포트에서만 run 이름을 변경합니다. 새 임의 이름 생성은 지원되지 않습니다.
-
Publish report를 클릭합니다.
wr.Runset() 및 wr.PanelGrid 클래스를 사용해 프로젝트에서 run 세트를 추가합니다. 다음 절차는 run 세트를 추가하는 방법을 설명합니다.
wr.Runset() 객체 인스턴스를 생성합니다. project 매개변수에는 run 세트를 포함하는 프로젝트 이름을, entity 매개변수에는 해당 프로젝트를 소유한 엔터티를 제공합니다.wr.PanelGrid() 객체 인스턴스를 생성합니다. 하나 이상의 runset 객체 목록을 run sets 매개변수에 전달합니다.- 하나 이상의
wr.PanelGrid() 객체 인스턴스를 리스트에 저장합니다.
- panel grid 인스턴스 리스트로 리포트 인스턴스의
blocks 속성을 업데이트합니다.
import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(
project="report-editing",
title="An amazing title",
description="A descriptive description.",
)
panel_grids = wr.PanelGrid(
runsets=[wr.RunSet(project="<project-name>", entity="<entity-name>")]
)
report.blocks = [panel_grids]
report.save()
import wandb
report = wr.Report(
project="report-editing",
title="An amazing title",
description="A descriptive description.",
)
panel_grids = wr.PanelGrid(
panels=[
wr.LinePlot(
title="line title",
x="x",
y=["y"],
range_x=[0, 100],
range_y=[0, 100],
log_x=True,
log_y=True,
title_x="x axis title",
title_y="y axis title",
ignore_outliers=True,
groupby="hyperparam1",
groupby_aggfunc="mean",
groupby_rangefunc="minmax",
smoothing_factor=0.5,
smoothing_type="gaussian",
smoothing_show_original=True,
max_runs_to_show=10,
plot_type="stacked-area",
font_size="large",
legend_position="west",
),
wr.ScatterPlot(
title="scatter title",
x="y",
y="y",
# z='x',
range_x=[0, 0.0005],
range_y=[0, 0.0005],
# range_z=[0,1],
log_x=False,
log_y=False,
# log_z=True,
running_ymin=True,
running_ymean=True,
running_ymax=True,
font_size="small",
regression=True,
),
],
runsets=[wr.RunSet(project="<project-name>", entity="<entity-name>")],
)
report.blocks = [panel_grids]
report.save()
| Grouping Method | Description | Available keys |
|---|
| Config values | config 값으로 run을 그룹화 | wandb.init(config=)의 config 파라미터에 지정한 값 |
| Run metadata | run 메타데이터로 run을 그룹화 | State, Name, JobType |
| Summary metrics | summary 메트릭으로 run을 그룹화 | wandb.Run.log()으로 run에 기록하는 값 |
(wandb.init(config=)) 에서 지정하는 파라미터이다. run을 config 값으로 그룹화하려면 config.<key> 문법을 사용한다. 여기서 <key> 는 그룹화에 사용할 config 값의 이름이다.
예를 들어, 다음 코드 스니펫은 먼저 group 에 대한 config 값을 사용해 run을 초기화한 다음, 리포트에서 group config 값을 기준으로 run을 그룹화한다. <entity> 와 <project> 값은 자신의 W&B entity 및 프로젝트 이름으로 교체한다.
import wandb
import wandb_workspaces.reports.v2 as wr
entity = "<entity>"
project = "<project>"
for group in ["control", "experiment_a", "experiment_b"]:
for i in range(3):
with wandb.init(entity=entity, project=project, group=group, config={"group": group, "run": i}, name=f"{group}_run_{i}") as run:
# 트레이닝을 간단히 시뮬레이션합니다
for step in range(100):
run.log({
"acc": 0.5 + (step / 100) * 0.3 + (i * 0.05),
"loss": 1.0 - (step / 100) * 0.5
})
config.group 값을 기준으로 run을 그룹화할 수 있습니다.
runset = wr.Runset(
project=project,
entity=entity,
groupby=["config.group"] # "group" config 값으로 그룹화
)
report = wr.Report(
entity=entity,
project=project,
title="Grouped Runs Example",
)
report.blocks = [
wr.PanelGrid(
runsets=[runset],
)
]
report.save()
Name), 상태(State), 또는 job 유형(JobType)별로 Runs를 그룹화할 수 있습니다.
이전 예시에서 이어서, 다음 코드 스니펫을 사용해 Runs를 이름 기준으로 그룹화할 수 있습니다:
runset = wr.Runset(
project=project,
entity=entity,
groupby=["Name"] # run 이름으로 그룹화
)
run의 이름은 wandb.init(name=) 파라미터에 지정한 이름입니다. 이름을 지정하지 않으면, W&B가 해당 run에 대해 임의의 이름을 생성합니다.run의 이름은 W&B App에서 해당 run의 Overview 페이지에서 확인하거나, Api.runs().run.name을 사용해 프로그램 코드에서 확인할 수 있습니다.
wandb.Run.log()를 사용해 run에 로그로 기록하는 값입니다. run을 기록한 후에는 W&B App에서 해당 run의 Overview 페이지에 있는 Summary 섹션에서 요약 메트릭의 이름을 확인할 수 있습니다.
요약 메트릭으로 runs를 그룹화하는 구문은 summary.<key>이며, 여기서 <key>는 그룹화에 사용할 요약 메트릭의 이름입니다.
예를 들어, acc라는 이름의 요약 메트릭을 기록했다고 가정해 보겠습니다:
import wandb
import wandb_workspaces.reports.v2 as wr
entity = "<entity>"
project = "<project>"
for group in ["control", "experiment_a", "experiment_b"]:
for i in range(3):
with wandb.init(entity=entity, project=project, group=group, config={"group": group, "run": i}, name=f"{group}_run_{i}") as run:
# 트레이닝 시뮬레이션
for step in range(100):
run.log({
"acc": 0.5 + (step / 100) * 0.3 + (i * 0.05),
"loss": 1.0 - (step / 100) * 0.5
})
summary.acc 요약 메트릭을 기준으로 run을 그룹화할 수 있습니다:
runset = wr.Runset(
project=project,
entity=entity,
groupby=["summary.acc"] # 요약 값으로 그룹화
)
Filter('key') operation <value>
key는 필터 이름이고, operation은 비교 연산자(예: >, <, ==, in, not in, or, and)이며, <value>는 비교 대상 값입니다. Filter는 적용하려는 필터 유형을 나타내는 플레이스홀더입니다. 다음 표에는 사용 가능한 필터와 그 설명이 나와 있습니다:
| Filter | Description | Available keys |
|---|
Config('key') | config 값으로 필터링 | wandb.init(config=)의 config 파라미터에 지정한 값. |
SummaryMetric('key') | 요약 메트릭으로 필터링 | wandb.Run.log()을 사용해 run에 로깅한 값. |
Tags('key') | 태그로 필터링 | run에 추가한 태그 값(프로그램 코드에서 또는 W&B App에서 추가). |
Metric('key') | run 속성으로 필터링 | tags, state, displayName, jobType |
wr.PanelGrid(runsets=)에 전달할 수 있습니다. 리포트에 다양한 요소를 프로그래밍 방식으로 추가하는 방법에 대해서는 이 페이지 전반에 걸쳐 있는 Report and Workspace API 탭을 참고하십시오.
다음 예시는 리포트에서 run 세트를 필터링하는 방법을 보여줍니다. <>로 둘러싸인 값을 사용자 값으로 바꾸십시오.
하나 이상의 설정 값으로 runset을 필터링합니다. 설정 값은 run 설정(wandb.init(config=))에서 지정하는 파라미터입니다.
예를 들어, 다음 코드 스니펫에서는 먼저 learning_rate와 batch_size 설정 값으로 run을 초기화한 다음, 리포트에서 learning_rate 설정 값을 기준으로 Runs를 필터링합니다.
import wandb
config = {
"learning_rate": 0.01,
"batch_size": 32,
}
with wandb.init(project="<project>", entity="<entity>", config=config) as run:
# 트레이닝 코드를 여기에 작성하세요
pass
0.01보다 큰 run만 코드로 필터링할 수 있습니다.
import wandb_workspaces.reports.v2 as wr
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Config('learning_rate') > 0.01"
)
and 연산자를 사용하여 여러 config 값을 기준으로 필터링할 수도 있습니다:
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Config('learning_rate') > 0.01 and Config('batch_size') == 32"
)
report = wr.Report(
entity="<entity>",
project="<project>",
title="My Report"
)
report.blocks = [
wr.PanelGrid(
runsets=[runset],
panels=[
wr.LinePlot(
x="Step",
y=["accuracy"],
)
]
)
]
report.save()
tags), run 상태(state), run 이름(displayName), 또는 job 타입(jobType)을 기준으로 필터링한다.
Metric 필터는 다른 구문을 사용한다. 값들은 리스트로 전달해야 한다.Metric('key') operation [<value>]
import wandb
with wandb.init(project="<project>", entity="<entity>") as run:
for i in range(3):
run.name = f"run{i+1}"
# 트레이닝 코드를 여기에 작성하세요
pass
run1, run2, run3인 run만 필터링하려면 다음 코드를 사용할 수 있습니다:
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('displayName') in ['run1', 'run2', 'run3']"
)
run의 이름은 W&B App에서 해당 run의 Overview 페이지에서 확인하거나, 프로그래밍 방식으로 Api.runs().run.name을 사용해 가져올 수 있습니다.
finished, crashed, 또는 running)에 따라 runset을 필터링하는 방법을 보여줍니다:
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('state') in ['finished']"
)
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('state') not in ['crashed']"
)
wandb.Run.log()을 사용해 run에 기록한 값이다. run을 로깅한 후에는 W&B App에서 해당 run의 Overview 페이지에 있는 Summary 섹션에서 Summary 메트릭의 이름을 확인할 수 있다.
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="SummaryMetric('accuracy') > 0.9"
)
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Metric('state') in ['finished'] and SummaryMetric('train/train_loss') < 0.5"
)
runset = wr.Runset(
entity="<entity>",
project="<project>",
filters="Tags('training') == 'training'"
)
App UI
Report and Workspace API
리포트에서 슬래시(/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 Code를 선택합니다.코드 블록 오른쪽에서 프로그래밍 언어 이름을 선택합니다. 그러면 드롭다운이 펼쳐집니다. 이 드롭다운에서 사용할 프로그래밍 언어 구문을 선택합니다. JavaScript, Python, CSS, JSON, HTML, Markdown, YAML 중에서 선택할 수 있습니다.
wr.CodeBlock 클래스를 사용해 코드 블록을 프로그래밍 방식으로 생성합니다. language와 code 파라미터에 각각 표시하려는 언어 이름과 코드를 전달합니다.예를 들어, 다음 예시는 YAML 파일의 리스트를 보여줍니다:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.CodeBlock(
code=["this:", "- is", "- a", "cool:", "- yaml", "- file"], language="yaml"
)
]
report.save()
this:
- is
- a
cool:
- yaml
- file
report = wr.Report(project="report-editing")
report.blocks = [wr.CodeBlock(code=["Hello, World!"], language="python")]
report.save()
App UI
Report and Workspace API
리포트에서 슬래시(/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 Markdown을 선택합니다.
wandb.apis.reports.MarkdownBlock 클래스를 사용해 프로그래밍 방식으로 마크다운 블록을 생성합니다. 문자열을 text 파라미터에 전달합니다:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.MarkdownBlock(text="Markdown cell with *italics* and **bold** and $e=mc^2$")
]
앱 UI
Report 및 Workspace API
리포트에서 슬래시(/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 텍스트 블록 유형을 선택합니다. 예를 들어 H2 헤딩 블록을 만들려면 Heading 2 옵션을 선택합니다.
하나 이상의 HTML 요소로 이루어진 목록을 wandb.apis.reports.blocks 속성에 지정합니다. 다음 예시는 H1, H2, 그리고 순서 없는 목록을 생성하는 방법을 보여줍니다:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.H1(text="How Programmatic Reports work"),
wr.H2(text="Heading 2"),
wr.UnorderedList(items=["Bullet 1", "Bullet 2"]),
]
report.save()
App UI
Report 및 Workspace API
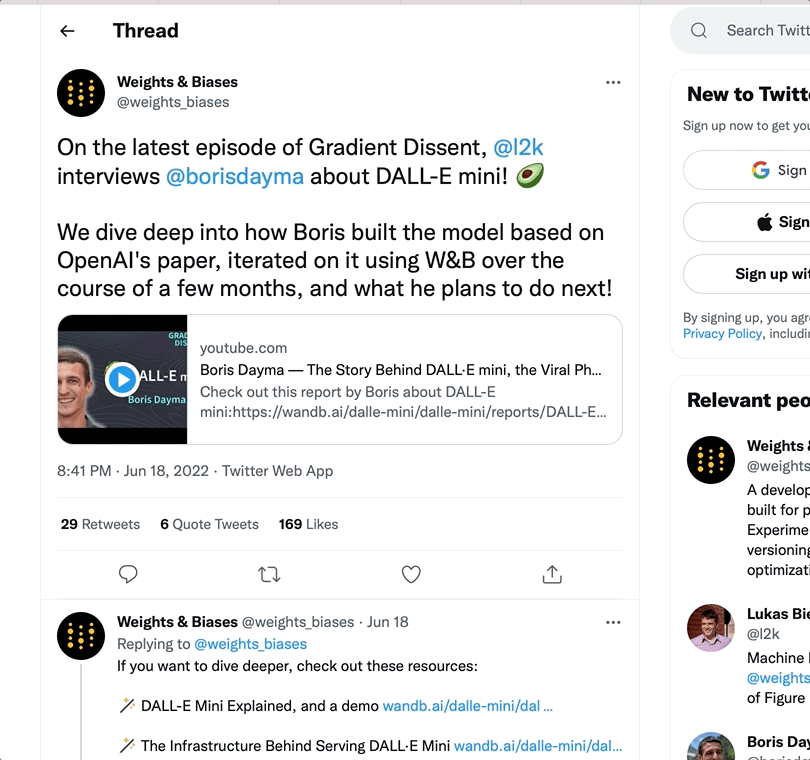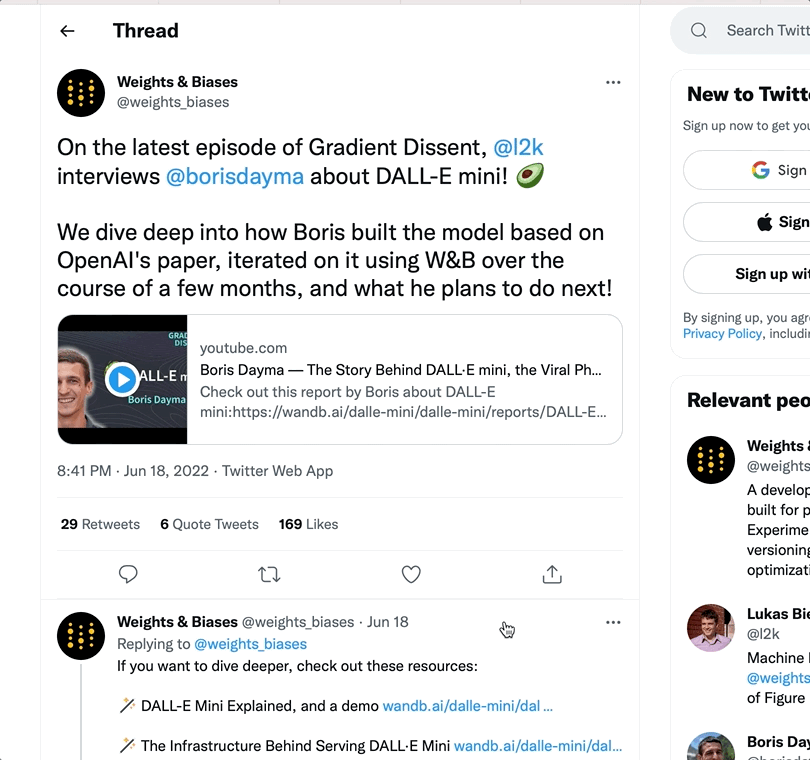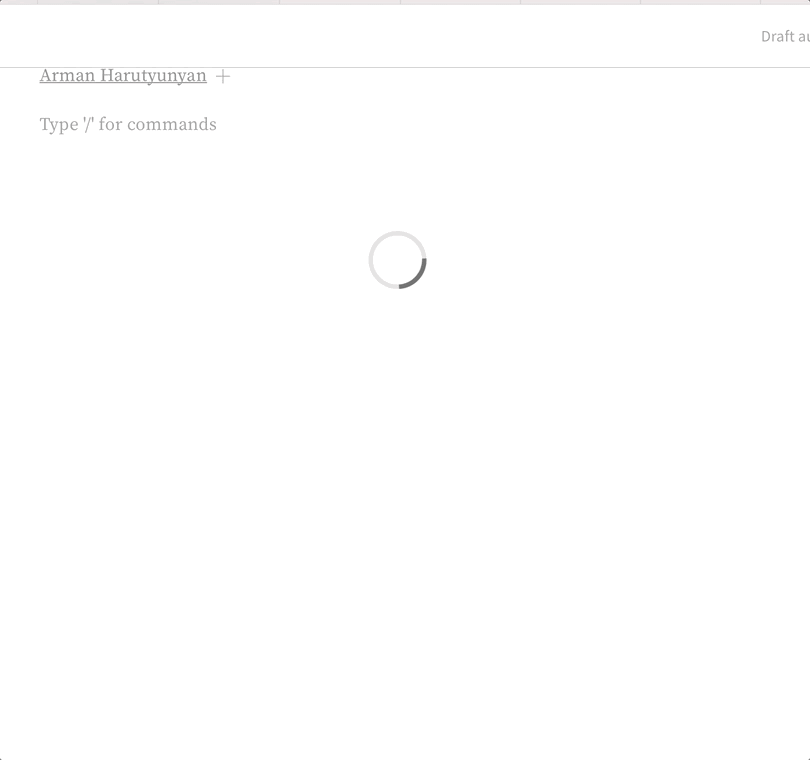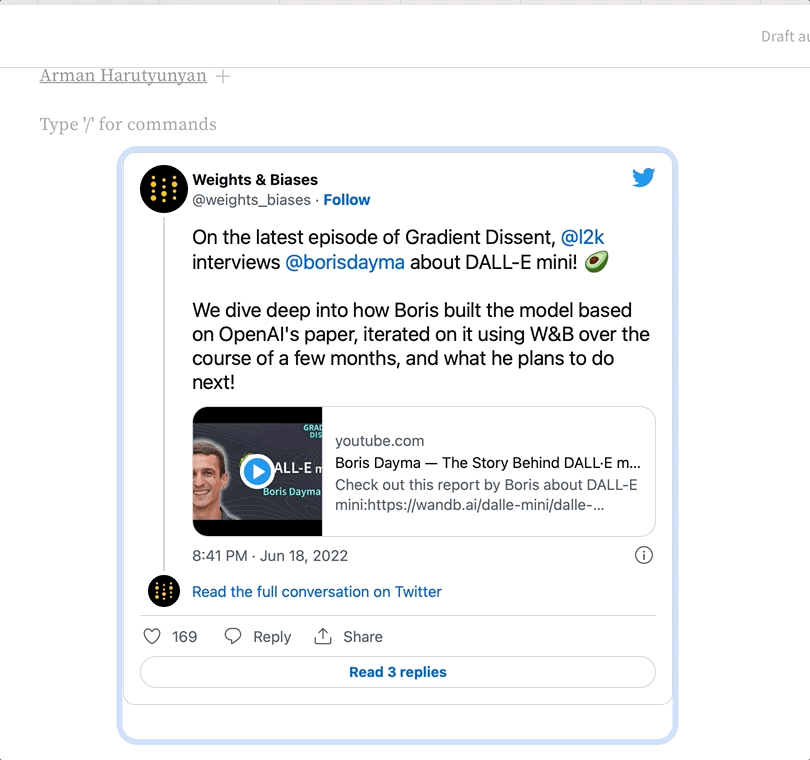
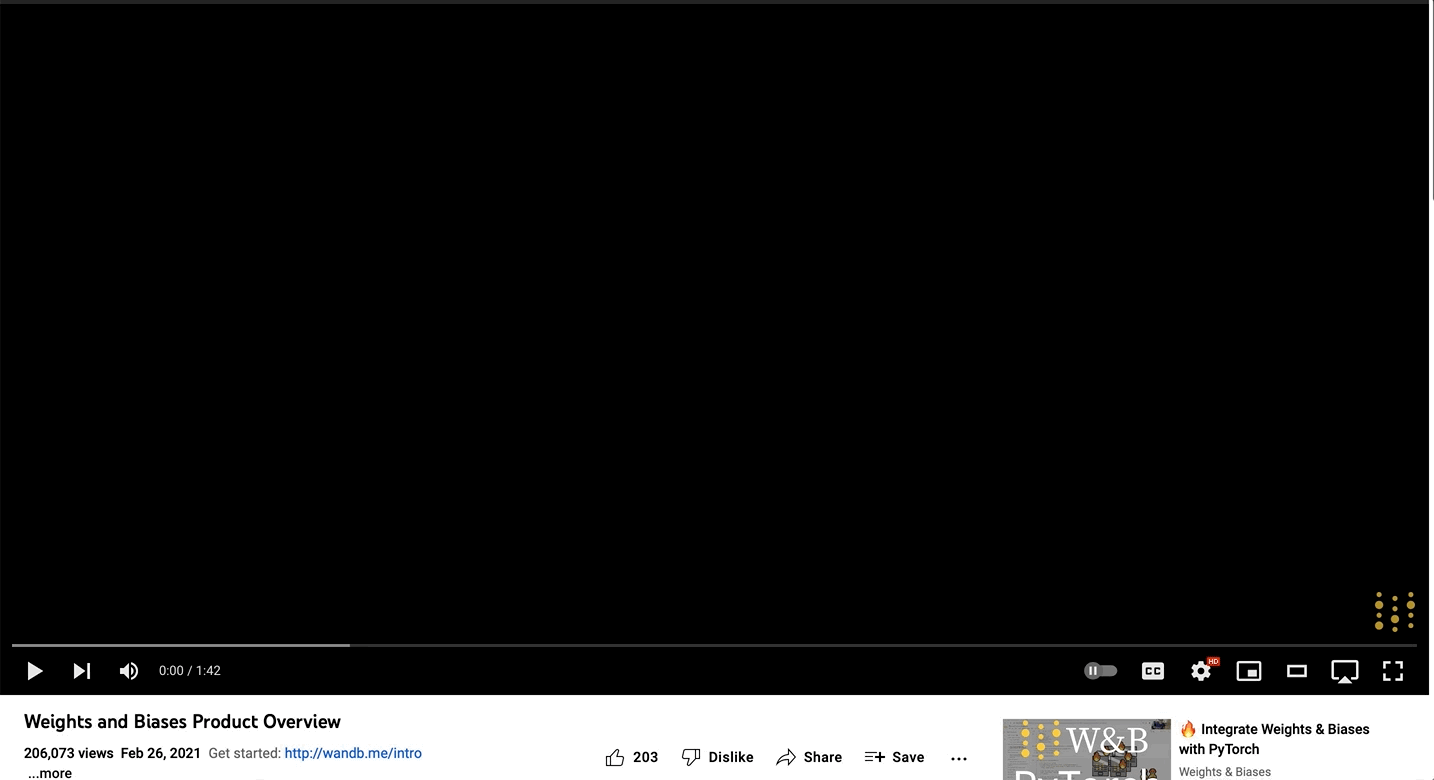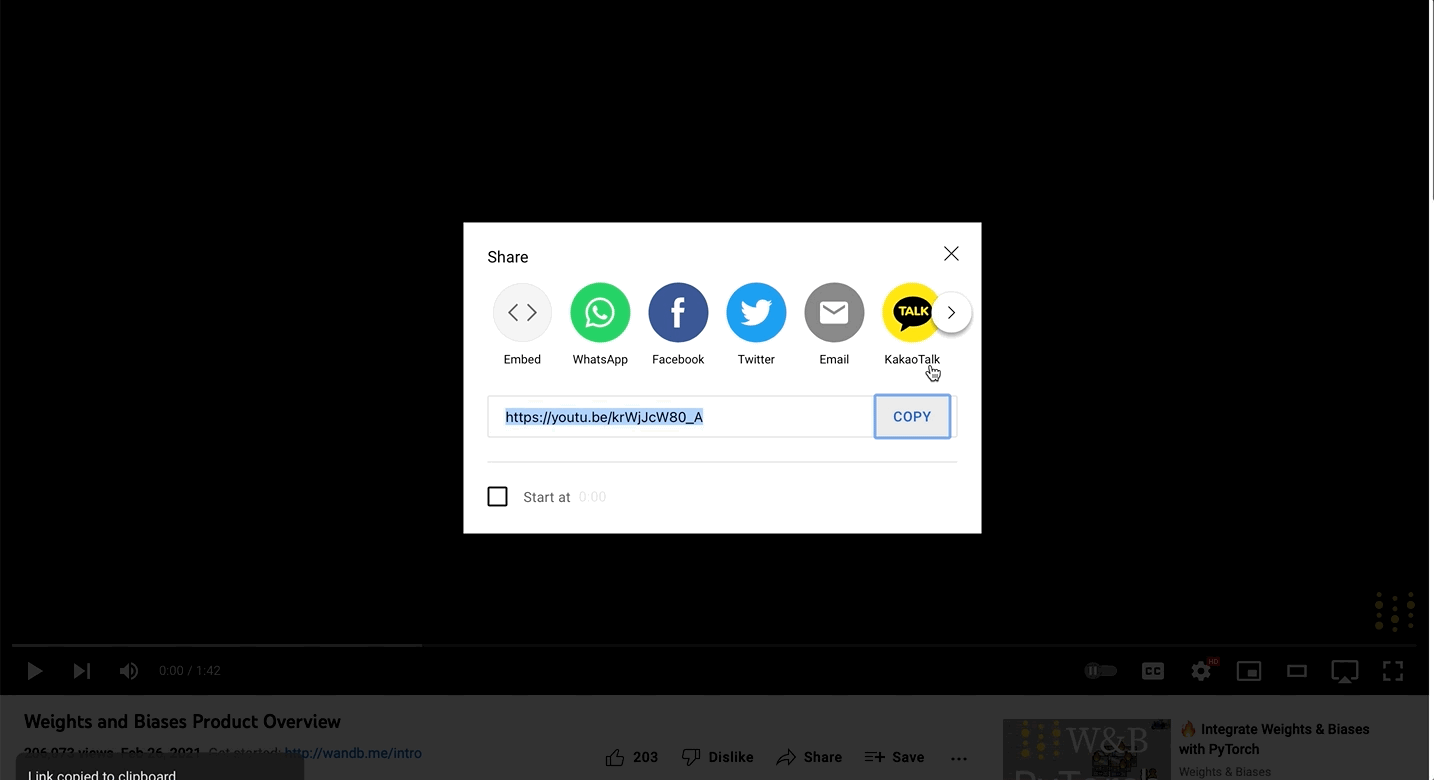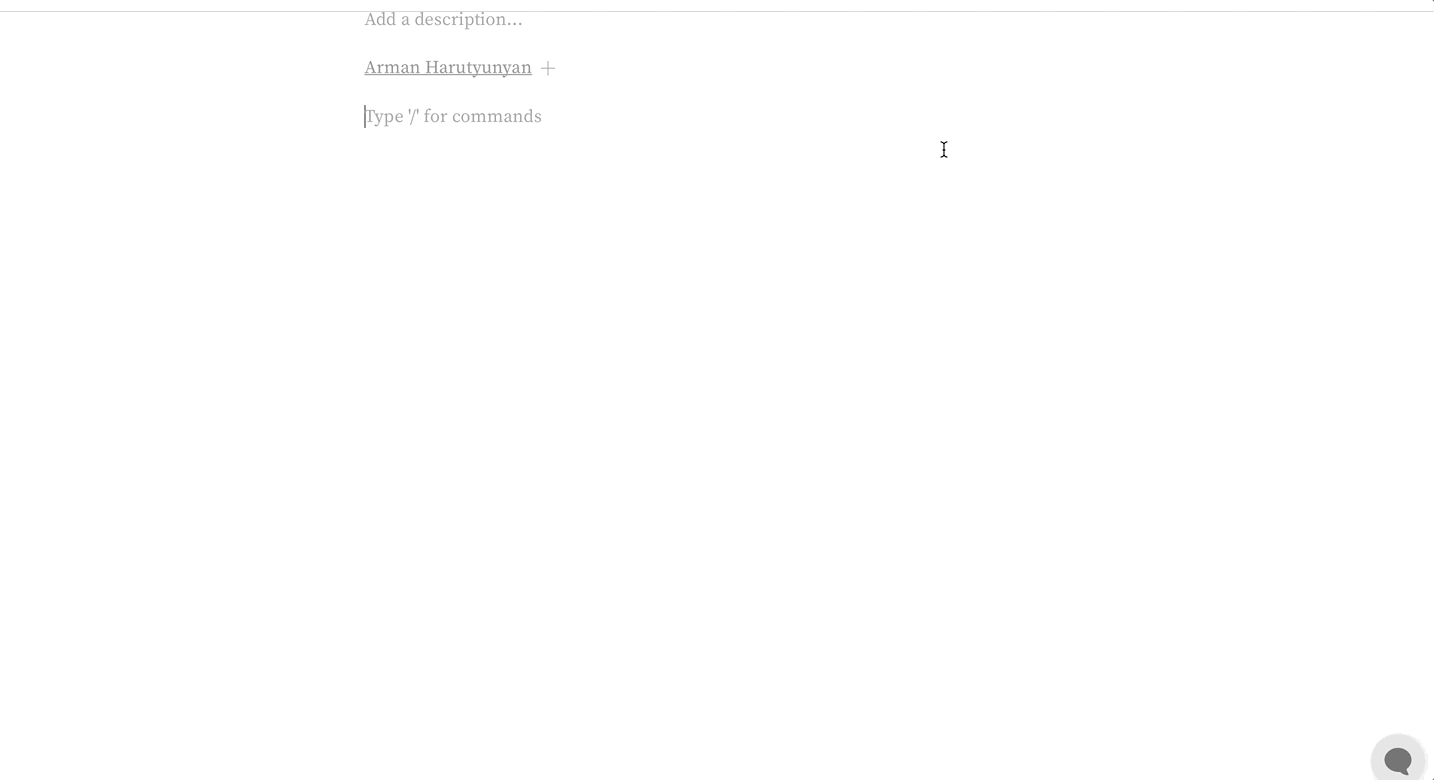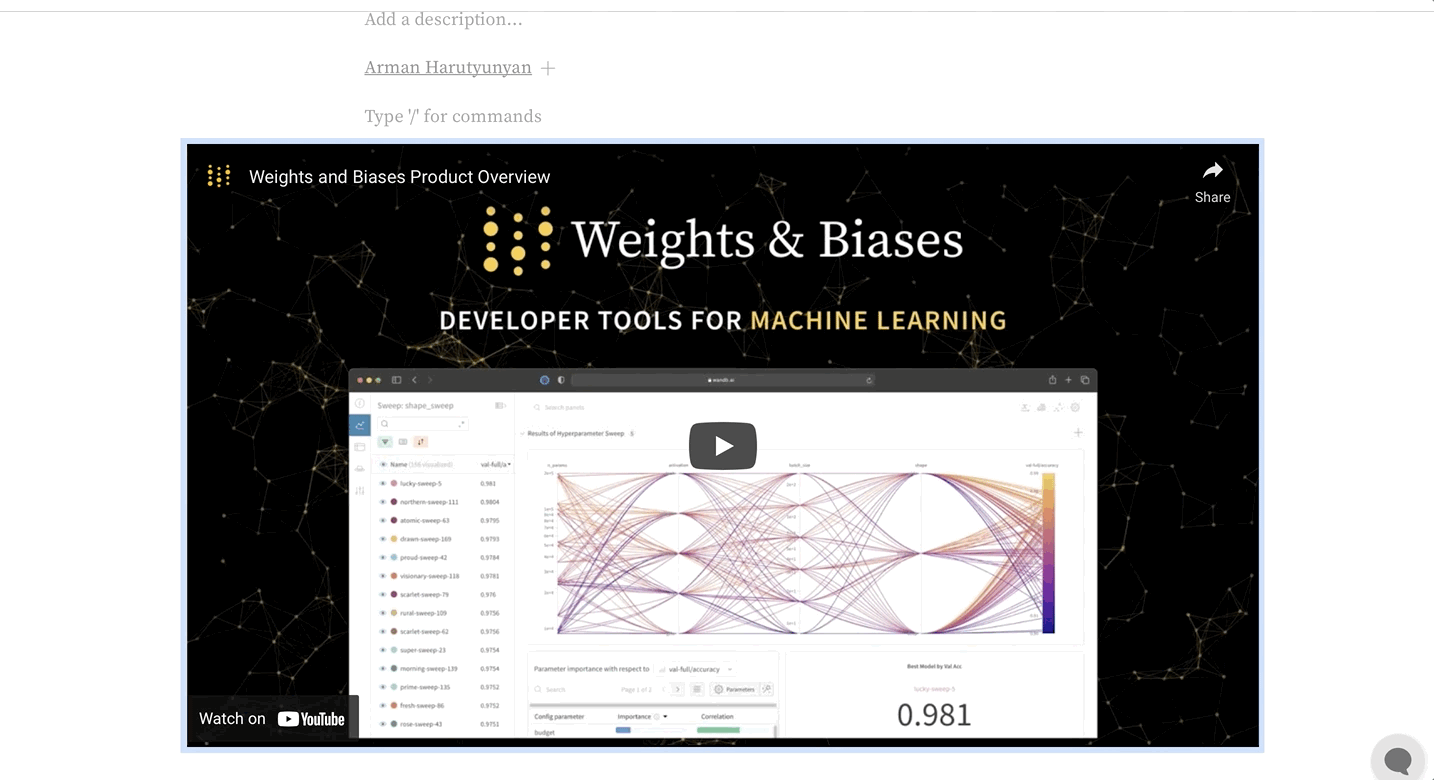
리포트에 URL을 복사해 붙여넣으면 리포트 안에 리치 미디어를 임베드할 수 있습니다. 아래 애니메이션은 Twitter, YouTube, SoundCloud에서 URL을 복사해 붙여넣는 방법을 보여줍니다.리포트 안에서 트윗을 볼 수 있도록 트윗 링크 URL을 리포트에 복사해 붙여넣습니다.Youtube
리포트에 동영상을 임베드하려면 YouTube 동영상 URL 링크를 복사해 붙여넣습니다.SoundCloud
리포트에 오디오 파일을 임베드하려면 SoundCloud 링크를 복사해 붙여넣습니다. wandb.apis.reports.blocks 속성에 하나 이상의 임베드된 미디어 객체 목록을 전달합니다. 다음 예시는 비디오와 Twitter 미디어를 리포트에 임베드하는 방법을 보여줍니다:import wandb
import wandb_workspaces.reports.v2 as wr
report = wr.Report(project="report-editing")
report.blocks = [
wr.Video(url="https://www.youtube.com/embed/6riDJMI-Y8U"),
wr.Twitter(
embed_html='<blockquote class="twitter-tweet"><p lang="en" dir="ltr">The voice of an angel, truly. <a href="https://twitter.com/hashtag/MassEffect?src=hash&ref_src=twsrc%5Etfw">#MassEffect</a> <a href="https://t.co/nMev97Uw7F">pic.twitter.com/nMev97Uw7F</a></p>— Mass Effect (@masseffect) <a href="https://twitter.com/masseffect/status/1428748886655569924?ref_src=twsrc%5Etfw">August 20, 2021</a></blockquote>\n'
),
]
report.save()
delete 키를 눌러 패널 그리드를 삭제합니다.
리포트에서 헤더를 접어 텍스트 블록 안의 콘텐츠를 숨길 수 있습니다. 리포트를 불러올 때는 확장된 헤더에 포함된 콘텐츠만 표시됩니다. 리포트에서 헤더를 접으면 콘텐츠를 더 잘 정리하고 과도한 데이터 로딩을 방지할 수 있습니다. 다음 GIF는 이 과정을 보여 줍니다.
여러 차원에 걸친 관계를 효과적으로 시각화하려면 변수 중 하나를 색상 그라디언트로 표현하십시오. 이렇게 하면 시각적 명확성이 높아지고 패턴을 더 쉽게 해석할 수 있습니다.
- 색상 그라디언트로 표현할 변수를 선택합니다(예: penalty 점수, learning rate 등). 이렇게 하면 트레이닝 시간(x축)에 따라 penalty(색상)가 reward/부작용(y축)과 어떻게 상호작용하는지 더 명확하게 이해할 수 있습니다.
- 주요 추세를 강조합니다. 특정 run 그룹 위에 커서를 올리면 시각화에서 해당 그룹이 강조 표시됩니다.